用Python中从头开始的实现完整的异常检测算法( 二 )
plt.figure()
plt.scatter(df[0], df[1])
plt.show()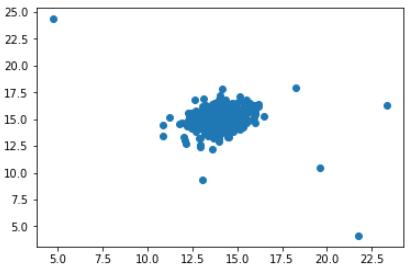 文章插图
文章插图
通过查看此图 , 您可能知道哪些数据是异常的 。
检查此数据集中有多少训练示例:
m = len(df)
计算每个特征的平均值 。这里我们只有两个功能:0和1 。
s = np.sum(df, axis=0)
mu = s/mmu
输出:
0 14.1122261 14.997711
dtype: float64
根据上面"公式和过程"部分所述的公式 , 计算出方差:
vr = np.sum((df - mu)**2, axis=0)
variance = vr/mvariance
输出:
0 1.8326311 1.709745
dtype: float64
现在使其成为对角线形状 。正如我在概率公式后面的"公式和过程"部分所解释的那样 , 求和符号实际上是方差的对角线 。
var_dia = np.diag(variance)
var_dia
输出:
array([[1.83263141, 0. ], [0. , 1.70974533]])
计算概率:
k = len(mu)
X = df - mu
p = 1/((2*np.pi)**(k/2)*(np.linalg.det(var_dia)**0.5))* np.exp(-0.5* np.sum(X @ np.linalg.pinv(var_dia) * X,axis=1))
p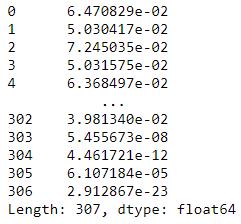 文章插图
文章插图
训练部分完成 。
下一步是找出阈值概率 。如果该概率低于阈值概率 , 则示例数据为异常数据 。但是我们需要为我们的特殊情况找出该阈值 。
在此步骤中 , 我们使用交叉验证数据以及标签 。在此数据集中 , 我们具有交叉验证数据以及单独的工作表中的标签 。
对于您的情况 , 您只需保留原始数据的一部分以进行交叉验证 。
现在导入交叉验证数据和标签:
cvx = pd.read_excel('ex8data1.xlsx', sheet_name='Xval', header=None)
cvx.head() 文章插图
文章插图
标签是:
cvy = pd.read_excel('ex8data1.xlsx', sheet_name='y', header=None)
cvy.head() 文章插图
文章插图
我将" cvy"转换为NumPy数组只是因为我喜欢使用数组 。DataFrames也很好 。
y = np.array(cvy)
输出:
#Part of the array
array([[0], [0], [0], [0], [0], [0], [0], [0], [0],
在这里 , " y"的值为0表示这是一个正常的例子 , 而y的值为1则表示这是一个异常的例子 。
现在 , 如何选择阈值?
我不想只是从概率列表中检查所有概率 。那可能是不必要的 。让我们再检查几率值 。
p.describe()
输出:
count 3.070000e+02
mean 5.905331e-02
std 2.324461e-02
min 1.181209e-2325% 4.361075e-0250% 6.510144e-0275% 7.849532e-02
max 8.986095e-02
dtype: float64
如您在图片中看到的 , 我们没有太多异常数据 。因此 , 如果我们仅从75%的值开始 , 那应该很好 。但是为了更加安全 , 我将从平均值开始 。
因此 , 我们将从平均值到较低范围取一系列概率 。我们将检查该范围内每个概率的f1分数 。
首先 , 定义一个函数来计算真实肯定 , 错误肯定和错误否定:
def tpfpfn(ep): tp, fp, fn = 0, 0, 0 for i in range(len(y)):if p[i] <= ep and y[i][0] == 1:tp += 1elif p[i] <= ep and y[i][0] == 0:fp += 1elif p[i] > ep and y[i][0] == 1:fn += 1 return tp, fp, fn列出小于或等于平均概率的概率 。
eps = [i for i in p if i <= p.mean()]
检查清单的长度 ,
len(eps)
输出:
133
根据我们之前讨论的公式 , 定义一个函数来计算f1分数:
def f1(ep): tp, fp, fn = tpfpfn(ep) prec = tp/(tp + fp) rec = tp/(tp + fn) f1 = 2*prec*rec/(prec + rec) return f1所有功能都准备就绪!
现在计算所有ε或我们之前选择的概率值范围的f1分数 。
f = []
for i in eps:
f.append(f1(i))
f
输出:
[0.14285714285714285, 0.14035087719298248, 0.1927710843373494, 0.1568627450980392, 0.208955223880597, 0.41379310344827586, 0.15517241379310345, 0.28571428571428575, 0.19444444444444445, 0.5217391304347826, 0.19718309859154928, 0.19753086419753085, 0.29268292682926833, 0.14545454545454545,
这是f得分列表的一部分 。长度应为133 。
f分数通常介于0和1之间 , 其中1是完美的f分数 。f1分数越高越好 。因此 , 我们需要从刚刚计算出的" f"分数列表中获得最高的f分数 。
现在 , 使用" argmax"函数确定最大f得分值的索引 。
np.array(f).argmax()
输出:
131
现在使用该索引来获取阈值概率 。
e = eps[131]
e
输出:
6.107184445968581e-05
找出异常的例子我们有阈值概率 。我们可以从中找出训练数据的标签 。
如果概率值小于或等于该阈值 , 则数据为异常 , 否则为正常 。我们将正常数据和异常数据分别表示为0和1 ,
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行