用Python中从头开始的实现完整的异常检测算法
 文章插图
文章插图
> Photo by Scott Umstattd on Unsplash
利用概率的异常检测算法异常检测可以作为离群分析的统计任务来对待 。但是 , 如果我们开发一个机器学习模型 , 它可以自动化 , 并且像往常一样可以节省大量时间 。有很多异常检测用例 。信用卡欺诈检测 , 故障机器检测或基于其异常功能的硬件系统检测 , 基于病历的疾病检测都是很好的例子 。还有更多用例 。并且异常检测的使用只会增加 。
在本文中 , 我将解释从头开始用Python开发异常检测算法的过程 。
公式和过程与我之前解释的其他机器学习算法相比 , 这将简单得多 。该算法将使用均值和方差来计算每个训练数据的概率 。
如果一个训练示例的概率很高 , 那是正常的 。如果某个训练示例的概率较低 , 则为异常示例 。对于不同的训练集 , 高概率和低概率的定义将有所不同 。稍后我们将讨论如何确定 。
如果我必须解释异常检测的工作过程 , 那非常简单 。
· 使用以下公式计算平均值: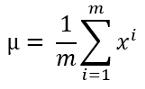 文章插图
文章插图
这里m是数据集的长度或训练数据的数量 , xi是一个训练示例 。如果您拥有多个训练功能 , 那么大多数时候您将需要为每个功能计算平均值 。
2.使用以下公式计算方差: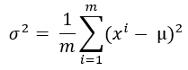 文章插图
文章插图
此处 , mu是从上一步计算得出的平均值 。
3.现在 , 使用此概率公式计算每个训练示例的概率 。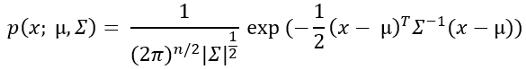 文章插图
文章插图
不要为这个公式中的加号感到困惑! 这实际上是对角线形状的变化 。
稍后我们将实现算法时 , 您将看到它的外观 。
4.我们现在需要找到概率的阈值 。正如我之前提到的 , 如果训练示例的概率较低 , 那么这就是一个异常示例 。
低概率是多少概率?
没有通用的限制 。我们需要为我们的训练数据集找到答案 。
我们从步骤3中获得的输出中获取一系列概率值 。 对于每种概率 , 如果数据是异常或正常的 , 请找到标签 。
然后计算一系列概率的精度 , 召回率和f1分数 。
可以使用以下公式计算精度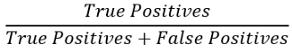 文章插图
文章插图
召回率可以通过以下公式计算: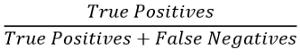 文章插图
文章插图
在此 , "正肯定"是指算法将示例检测为异常并且实际上是异常的情况下的数量 。
当算法将示例检测为异常时会出现误报 , 但事实并非如此 。
False Negative表示算法检测到的示例不是异常示例 , 但实际上 , 这是一个异常示例 。
从上面的公式中 , 您可以看到更高的精度和更高的召回率总会很好 , 因为这意味着我们拥有更多的积极优势 。但是同时 , 如您在公式中所看到的 , 误报和误报也起着至关重要的作用 。那里需要保持平衡 。根据您所在的行业 , 您需要确定哪个是您可以容忍的 。
一个好的方法是取平均值 。有一个求平均值的独特公式 。这就是f1分数 。f1得分的公式是: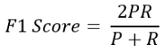 文章插图
文章插图
这里 , P和R分别是精度和召回率 。
我不会详细说明为什么公式如此独特 。因为本文是关于异常检测的 。如果您有兴趣了解有关精度 , 召回率和f1得分的更多信息 , 请在此处查看有关该主题的详细文章:
完全了解精度 , 召回率和F分数概念如何处理机器学习中偏斜的数据集根据f1分数 , 您需要选择阈值概率 。
1是完美的f得分 , 0是最差的概率得分
异常检测算法我将使用Andrew Ng的机器学习课程中的数据集 , 该数据集具有两个训练功能 。我没有使用本文的真实数据集 , 因为该数据集非常适合学习 。它只有两个功能 。在任何现实世界的数据集中 , 不可能只有两个功能 。
开始任务吧!
首先 , 导入必要的软件包
import pandas as pd
import numpy as np
导入数据集 。这是一个excel数据集 。此处 , 训练数据和交叉验证数据存储在单独的表格中 。因此 , 让我们带来培训数据 。
df = pd.read_excel('ex8data1.xlsx', sheet_name='X', header=None)
df.head()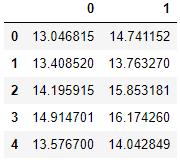 文章插图
文章插图
让我们针对第1列绘制第0列 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行