计算机视觉"新"范式:Transformer | NLP和CV能用同一种范式来表达吗?( 二 )
DETR主要有两个部分:architecture和set prediction loss 。
1. Architecture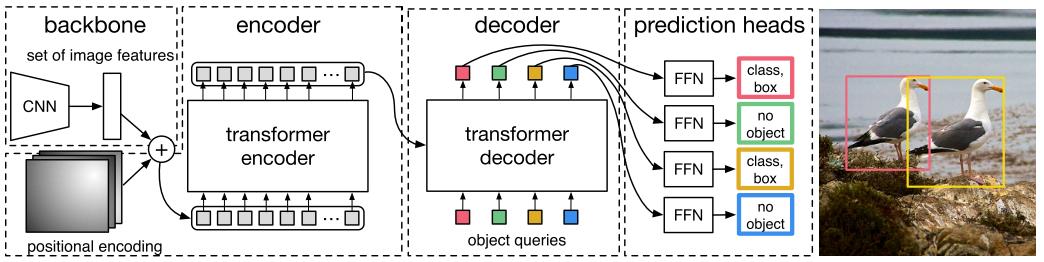 文章插图
文章插图
DETR先用CNN将输入图像embedding成一个二维表征 , 然后将二维表征转换成一维表征并结合positional encoding一起送入encoder , decoder将少量固定数量的已学习的object queries(可以理解为positional embeddings)和encoder的输出作为输入 。
最后将decoder得到的每个output embdding传递到一个共享的前馈网络(FFN) , 该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类 。
1.1 Transformer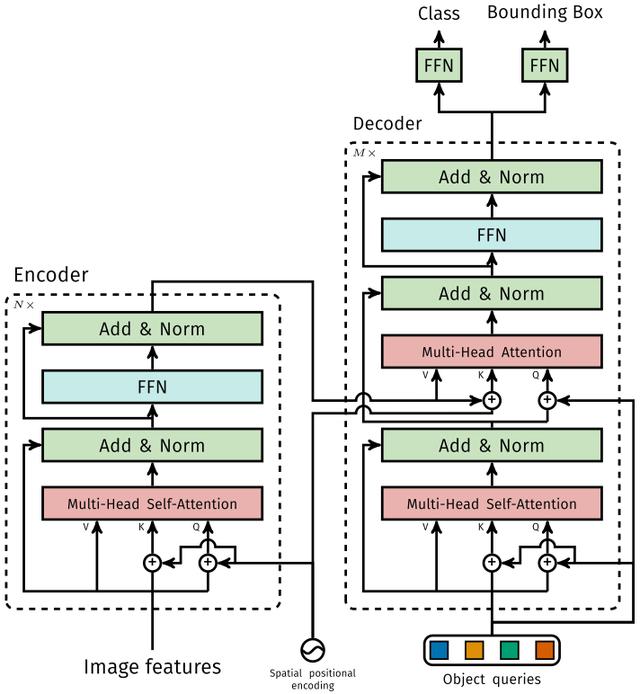 文章插图
文章插图
1.1.1 Encoder
将Backbone输出的feature map转换成一维表征 , 得到 特征图 , 然后结合positional encoding作为Encoder的输入 。
每个Encoder都由Multi-Head Self-Attention和FFN组成 。
和Transformer Encoder不同的是 , 因为Encoder具有位置不变性 , DETR将positional encoding添加到每一个Multi-Head Self-Attention中 , 来保证目标检测的位置敏感性 。
1.1.2 Decoder
因为Decoder也具有位置不变性 , Decoder的 个object query(可以理解为学习不同object的positional embedding)必须是不同 , 以便产生不同的结果 , 并且同时把它们添加到每一个Multi-Head Attention中 。
个object queries通过Decoder转换成一个output embedding , 然后output embedding通过FFN独立解码出 个预测结果 , 包含box和class 。
对输入embedding同时使用Self-Attention和Encoder-Decoder Attention , 模型可以利用目标的相互关系来进行全局推理 。
和Transformer Decoder不同的是 , DETR的每个Decoder并行输出 个对象 , Transformer Decoder使用的是自回归模型 , 串行输出 个对象 , 每次只能预测一个输出序列的一个元素 。
1.1.3 FFN
FFN由3层perceptron和一层linear projection组成 。 FFN预测出box的归一化中心坐标、长、宽和class 。
DETR预测的是固定数量的 个box的集合 , 并且 通常比实际目标数要大的多 , 所以使用一个额外的空类来表示预测得到的box不存在目标 。
2. Set prediction loss
DETR模型训练的主要困难是如何根据gt衡量预测结果(类别、位置、数量) 。 DETR提出的loss函数可以产生pred和gt的最优双边匹配(确定pred和gt的一对一关系) , 然后优化loss 。
将y表示为gt的集合 ,表示为 个预测结果的集合 。 假设 大于图片目标数 ,可以认为是用空类(无目标)填充的大小为 的集合 。
搜索两个集合 个元素 的不同排列顺序 , 使得loss尽可能的小的排列顺序即为二分图最大匹配(Bipartite Matching) , 公式如下:
其中 表示pred和gt关于 元素 的匹配loss 。 其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到 。
匹配loss同时考虑了pred class和pred box的准确性 。 每个gt的元素 可以看成,表示class label(可能是空类) 表示gt box , 将元素 二分图匹配指定的pred class表示为, pred box表示为。
第一步先找到一对一匹配的pred和gt , 第二步再计算hungarian loss 。
hungarian loss公式如下:
其中 结合了L1 loss和generalized IoU loss , 公式如下:
ViT和DETR两篇文章的实验和可视化分析很有启发性 , 感兴趣的可以仔细看看~~
4 Deformable DETR
从DETR看 , 还不足以赶上CNN , 因为训练时间太久了 , Deformable DETR的出现 , 让我对Transformer有了新的期待 。
Deformable DETR将DETR中的attention替换成Deformable Attention , 使DETR范式的检测器更加高效 , 收敛速度加快10倍 。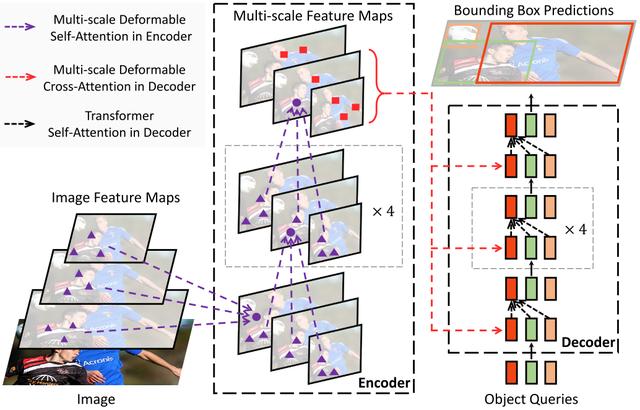 文章插图
文章插图
Deformable DETR提出的Deformable Attention可以可以缓解DETR的收敛速度慢和复杂度高的问题 。 同时结合了deformable convolution的稀疏空间采样能力和transformer的关系建模能力 。
Deformable Attention可以考虑小的采样位置集作为一个pre-filter突出所有feature map的关键特征 , 并且可以自然地扩展到融合多尺度特征 , 并且Multi-scale Deformable Attention本身就可以在多尺度特征图之间进行交换信息 , 不需要FPN操作 。
1. Deformable Attention Module
给定一个query元素(如输出句子中的目标词)和一组key元素(如输入句子的源词) , Multi-Head Attention能够根据query-key pairs的相关性自适应的聚合key的信息 。 为了让模型关注来自不同表示子空间和不同位置的信息 , 对multi-head的信息进行加权聚合 。
其中 表示query元素(特征表示为 ) ,表示key元素(特征表示为 ) ,是特征维度 ,和 分别为 和 的集合 。
那么Transformer 的 Multi-Head Attention公式表示为:
- 计算机学科|机器视觉系统是什么
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 吉林大学TARS-GO战队视觉代码
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 京东另类科学实验室之"5G来了"