计算机视觉"新"范式:Transformer | NLP和CV能用同一种范式来表达吗?
自从Transformer出来以后 , Transformer便开始在NLP领域一统江湖 。
而Transformer在CV领域反响平平 , 一度认为不适合CV领域 , 直到最近计算机视觉领域出来几篇Transformer文章 , 性能直逼CNN的SOTA , 给予了计算机视觉领域新的想象空间 。
本文不拘泥于Transformer原理和细节实现(知乎有很多优质的Transformer解析文章 , 感兴趣的可以看看) , 着重于Transformer对计算机视觉领域的革新 。
首先简略回顾一下Transformer , 然后介绍最近几篇计算机视觉领域的Transformer文章 , 其中ViT用于图像分类 , DETR和Deformable DETR用于目标检测 。
从这几篇可以看出 , Transformer在计算机视觉领域的范式已经初具雏形 , 可以大致概括为:Embedding->Transformer->Head
一些有趣的点写在最后~~
1 Transformer
Transformer详解:
下面以机器翻译为例子 , 简略介绍Transformer结构 。
【计算机视觉"新"范式:Transformer | NLP和CV能用同一种范式来表达吗?】1. Encoder-Decoder
Transformer结构可以表示为Encoder和Decoder两个部分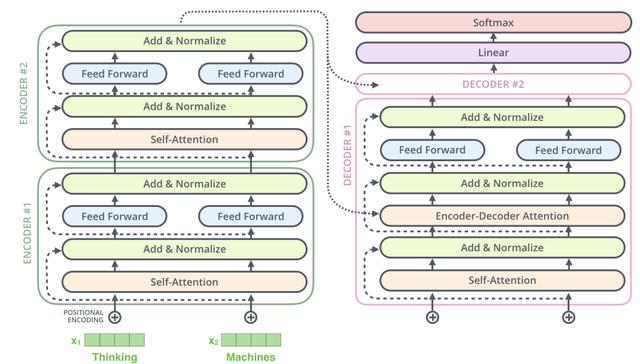 文章插图
文章插图
Encoder和Decoder主要由Self-Attention和Feed-Forward Network两个组件构成 , Self-Attention由Scaled Dot-Product Attention和Multi-Head Attention两个组件构成 。
Scaled Dot-Product Attention公式:
Multi-Head Attention公式:
Feed-Forward Network公式:
2. Positional Encoding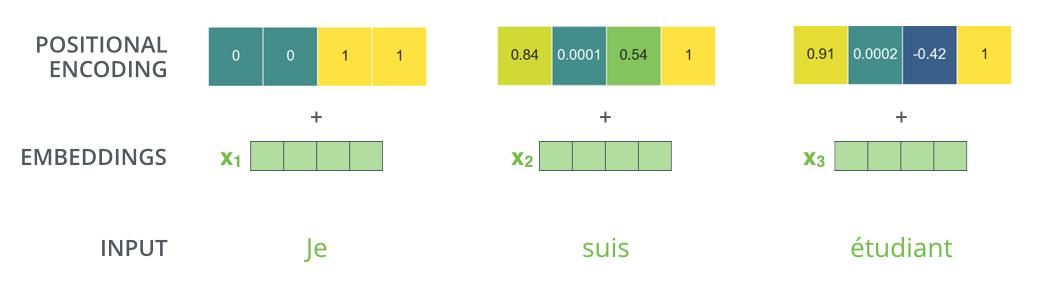 文章插图
文章插图
如图所示 , 由于机器翻译任务跟输入单词的顺序有关 , Transformer在编码输入单词的嵌入向量时引入了positional encoding , 这样Transformer就能够区分出输入单词的位置了 。
引入positional encoding的公式为:
是位置 ,是维数 ,是输入单词的嵌入向量维度 。
3. Self-Attention
3.1 Scaled Dot-Product Attention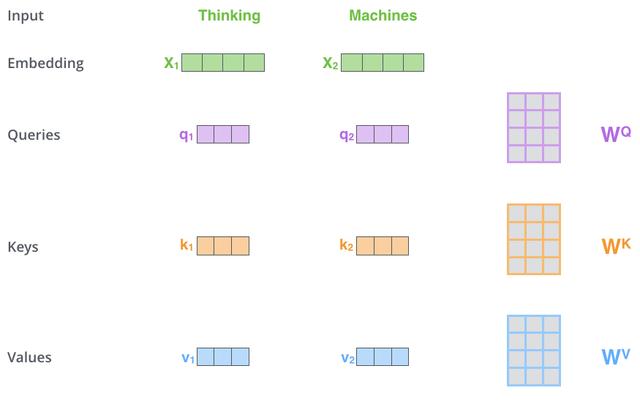 文章插图
文章插图
在Scaled Dot-Product Attention中 , 每个输入单词的嵌入向量分别通过3个矩阵,和 来分别得到Query向量 , Key向量和Value向量 。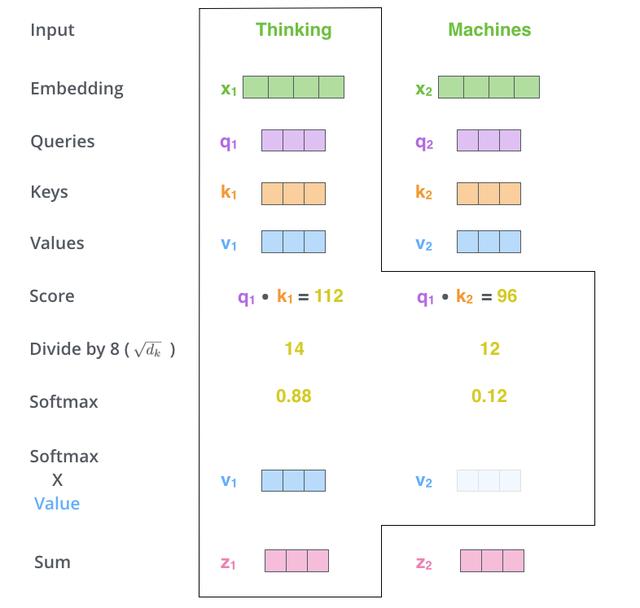 文章插图
文章插图
如图所示 , Scaled Dot-Product Attention的计算过程可以分成7个步骤:
- 每个输入单词转化成嵌入向量 。
- 根据嵌入向量得到 ,,三个向量 。
- 通过 , 向量计算 :。
- 对 进行归一化 , 即除以。
- 通过 激活函数计算。
- 点乘Value值, 得到每个输入向量的评分。
- 所有输入向量的评分 之和为 :。
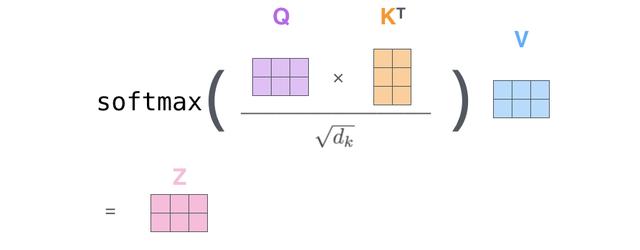 文章插图
文章插图与Scaled Dot-Product Attention公式一致 。
3.2 Multi-Head Attention
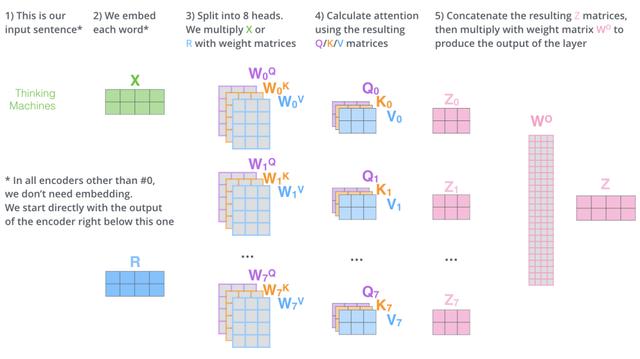 文章插图
文章插图如图所示 , Multi-Head Attention相当于h个不同Scaled Dot-Product Attention的集成 , 以h=8为例子 , Multi-Head Attention步骤如下:
- 将数据 分别输入到8个不同的Scaled Dot-Product Attention中 , 得到8个加权后的特征矩阵。
- 将8个 按列拼成一个大的特征矩阵 。
- 特征矩阵经过一层全连接得到输出。
2 ViT
ViT将Transformer巧妙的应用于图像分类任务 , 更少计算量下性能跟SOTA相当 。
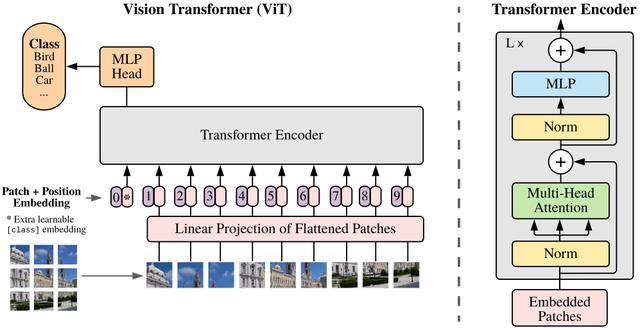 文章插图
文章插图Vision Transformer(ViT)将输入图片拆分成16x16个patches , 每个patch做一次线性变换降维同时嵌入位置信息 , 然后送入Transformer , 避免了像素级attention的运算 。 类似BERT[class]标记位的设置 , ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位 , 并且该位置的Transformer Encoder输出作为图像特征 。
其中 为原图像分辨率 ,为每个图像patch的分辨率 。为Transformer输入序列的长度 。
ViT舍弃了CNN的归纳偏好问题 , 更加有利于在超大规模数据上学习知识 , 即大规模训练优归纳偏好 , 在众多图像分类任务上直逼SOTA 。
3 DETR
DETR使用set loss function作为监督信号来进行端到端训练 , 然后同时预测所有目标 , 其中set loss function使用bipartite matching算法将pred目标和gt目标匹配起来 。
直接将目标检测任务看成set prediction问题 , 使训练过程变的简洁 , 并且避免了anchor、NMS等复杂处理 。
- 计算机学科|机器视觉系统是什么
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 吉林大学TARS-GO战队视觉代码
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 京东另类科学实验室之"5G来了"