内存数据库解析与主流产品对比(二)( 四 )
Adaptive Radix Tree
Hyper的索引树的设计采用了Adaptive Radix Tree 。 传统Radix Tree是一个前缀树 , 其优势是树的深度不依赖于被索引的值的个数 , 而是靠Search Key的长度来决定 。 它的缺点是每一个节点都要维护可能取值的子节点的信息 , 导致每个节点的存储开销较大 。
而在Adaptive Radix Tree中 , 为每个节点提供了不同类型长度的格式 , 分别可以保存4/16/48/256等不同个数的子节点 。 Node4为最小的节点类型 , 最多可存储4个子节点指针 ,Key用来表示节点所存储的值 , 指针可以指向叶子节点 , 也可以指向下一层内部节点 。 Node16 和Node4 结构上一致 , 但 Node16 可以存放16个 unsigned char 和16个指针 , 在存放第17个key时则需要将其扩大为 Node48 。 Node48结构上和 Node4/16 有所不同 , 有256个索引槽和48个指针 , 这256个索引槽对应 unsigned char 的0-255 , 每个索引槽的值对应指针的位置 , 分别为 1-48 , 如果某个字节不存在的话 , 那么它的索引槽的值就是0 。 当存放第49个key byte 时需要将其扩大为 Node256 。 Node256结果较为简单 , 直接存放256个指针 , 每个指针对应 unsigned char 的0-255 区间 。
比如说在这个例子里 , 我们要索引一个整数(+218237439) , 整数的二进制表示形式为32位 , 随后将32位bit转换为4个Byte , 这4个byte十进制表示为13、2、9、255 , 这就是它的Search Key 。 在索引树中 , 第一层为Node 4 , 13符合这一层的存储要求 , 于是就保留在第一层节点上 , 后面的位数则进入下一层存储 , 下一层为Node 48 , 用来存储2;接下来的每一位都存储到下面的每一层 。 由于本例子中整数为4个字节表示 , 故共有4层 。 可以看到 , 每个节点的结构是不一样的 , 根据字节位数和顺序逐一存储 , 数值在这一层目前有多少个不同的值 , 就选择什么类型的节点 。 如果当前类型的不够用 , 可以再增加个数 , 每个节点可以容纳的 key 是动态变化的 , 这样既可以节省空间 , 又可以提高缓存局部性 。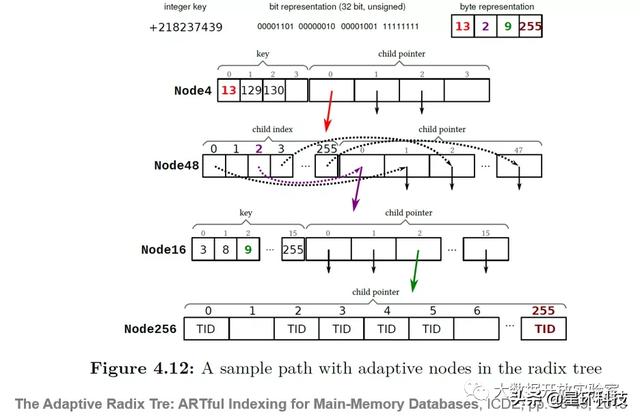 文章插图
文章插图
另外Adaptive Radix还采用了路径压缩机制 , 如果一条路径的父节点只有一个子节点就会将之压缩合并 。 Adaptive Radix之所以采用这样的索引结构 , 是因为每个节点的大小都等于一个Cache Line , 所有操作可以在一个Cache Line的基础上实现 。
OLFIT on B+-Trees
OLFIT on B+-Trees(Optimistic Latch Free Index Access Protocol)是HANAP*Time采用的索引技术 , 能够在多核数据库上保证CPU的Cache Coherence 。 在多处理器计算机的体系结构中 , 多个CPU的Cache会缓存同一内存的数据 。 在内存数据库中 , 存储的数据会先读到对应Cache再处理;如果缓存数据处理过程中内存数据发生变化 , 那Cache的数据会因与内存数据不一致而失效 , Cache Coherence就是解决这个不同步的问题 。
考虑这样一个场景:如下图所示 , 内存中有一个树形数据结构 , 由4个CPU处理 , 每个CPU有自己的Cache 。 假设CPU-P1先读了n1、n2、n4 , Cache中便有了n1、n2、n4 。 随后CPU-P2读n1、n2和n5时 , 假设这个数据结构不是Latch-Free , 如果在读的同时且允许修改 , 就需要一个Latch来在读的时候上锁 , 读完再释放 。 因为内存数据库中Latch和数据放在一起 , 数据虽然没有变化 , 但是Latch的状态发生了改变 , 计算机的硬件结构会认为内存发生了变化 。 所以 , 当多个CPU读同样的数据时 , 只有最后一次读取状态是有效的 , 前序的读取会被认为失效 。 这就会出现即使都是进行读操作 , 但是因为Latch状态改变导致CPU的Cache失效 。 因此OLFIT设计了一套机制 , 要求写操作申请Latch , 读操作不需要 。 OLFIT通过版号维护读写事务 , 每个CPU读前先把版本号拷贝到本地寄存器 , 然后等读完数据后 , 再判断此时版本号跟读前的是否一样 。 如果一样就继续正常执行 , 不一样就说明Cache失效 。 因此 , 读请求不会引起其他CPU的Cache失效 。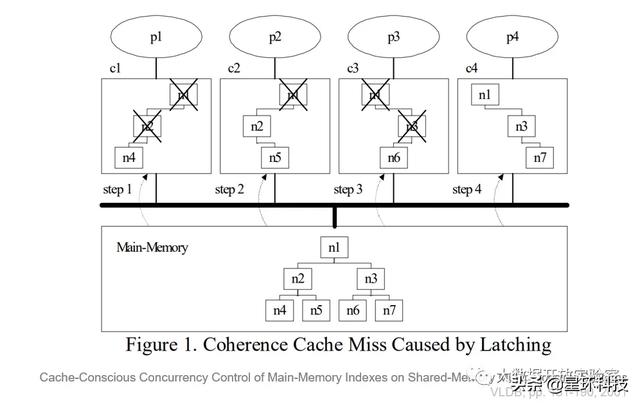 文章插图
文章插图
通过这个例子可以看到 , 内存数据库考虑的问题和基于磁盘的数据库是不一样的 , 没有了磁盘I/O的因素 , 就需要考虑其他方面对性能的限制 。
Skiplists
Skiplists是MemSQL的数据处理引擎所用到的技术 , 它的最底层是一个有序的列表 , 上层按照一定的概率(P-value)抽取数据 , 再做一层列表 。 进行大列表搜索时 , 从最上层开始一层层递进 , 类似于二分查找 , 粒度可以根据实际情况自定义 。 之所以这样设计是因为所有对列表的插入操作 , 都是可以通过Compare-and-Swap原子操作完成 , 从而省去了锁的开销 。
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 值得|千元价位,大容量电池,大内存,双模5G,你值得拥有!
- 想象|半导体厂商警告:明年处理器内存缺货到无法想象
- 手机|手机文件夹都是英文,占空间还不敢删除,教你一招省下10G内存
- DDR5内存曝光:16GB 4800MHz快速更省电
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 详解mysql执行计划
- 第一次买这么贵的内存卡,索尼A7S3 Type-A很坑吗?