内存数据库解析与主流产品对比(二)( 二 )
— 内存数据库系统对比—
接下来从数据组织的角度 , 简要介绍一下4个具有代表性的系统:SQL Server的内存数据库引擎Hekaton、慕尼黑工业大学的内存数据库系统HyPer、SAP的HANA、图灵奖获得者Michael Stonebraker的H-Store/VoltDB 。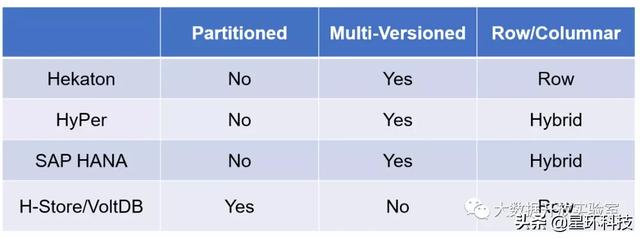 文章插图
文章插图
Hekaton
Hekaton是一个Non-Partition的系统 , 所有线程都可以访问任意数据 。 Hekaton的并发控制不采用基于锁的协议 , 而是利用多版本机制实现 , 每条记录的每个版本都有开始时间戳和结束时间戳 , 用于确定该版本的可见范围 。
Hekaton中每一张表最多有8个索引 , 可以是Hash或者Range索引 。 同时 , 所有记录版本在内存中不要求连续存储 , 可以是非连续存储(No-Clustering) , 通过指针(Pointer Link)将同一记录的不同版本关联起来 。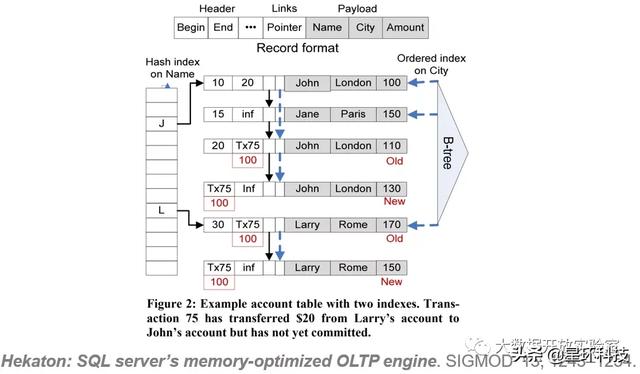 文章插图
文章插图
上图所示 , 图中有一个包含姓名、城市和金额字段的表 , 姓名字段上有一个Hash索引 , 城市字段上有一个B-Tree索引 。 黑色箭头代表姓名索引对应的指针 , 名字John对应的第一条记录 , 指向下一个具有相同开头字母名字的记录 。 每条记录包含有开始和结束时间戳 , 红色表示存在一个事务正在更新记录 , 事务提交后会替换结束的时间戳 。 B-Tree索引也是同理 , 蓝色箭头指针按照城市值串联 。
H-Store/VoltDB
H-Store/VoltDB是Partition System , 每个Partition部署在一个节点 , 每个节点上的任务串行执行 。 H-Store/VoltDB没有并发控制 , 但有简单的锁控制 。 一个Partition对应一把锁 , 如果某事务要在一个Partition上执行 , 需要先拿到这个Partition的锁 , 才能开始执行 。 为了解决跨Partition执行问题 , H-Store/VoltDB要求Transaction必须同时拿到所有相关Partition的锁才能开始执行 , 相当于同时锁住所有与事务相关的Partition 。
H-Store/VoltDB采用两层架构:上层是Transaction Coordinator , 确定Transaction是否需要跨Partition执行;下层是执行引擎负责数据的存储、索引和事务执行 , 采用的是单版本的行存结构 。
H-Store/VoltDB中的数据块分为定长和变长两类:定长数据块的每条记录长度都相同 , 索引中采用8字节地址指向每条记录在定长数据块中的位置;变长属性被保存在变长数据块中 , 在定长数据块的记录中对应一个指针(Non-Inline Data) , 指向其在变长数据块中具体的位置 。 在这种数据组织方式下 , 可以用一个压缩过的Block Look-Up Table来对数据记录进行寻址 。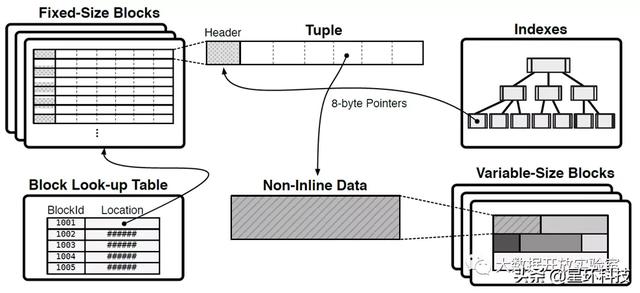 文章插图
文章插图
HyPer
HyPer是多版本的Non-Partition System , 每个Transaction可以访问任何数据 。 同时HyPer是针对于HTAP业务建立的TP和AP混合处理系统 。 HyPer通过Copy on Write机制实现TP和AP混合处理 。 假设当前系统正在对数据集做事务处理 , 此时如果出现AP请求 , HyPer会通过操作系统的Fork功能对数据集做Snapshot , 随后在快照上面做分析 。 Copy on Write机制并不会对内存中的所有数据进行复制 , 只有因OLTP业务导致数据发生变化时 , 快照才会真正拷贝出原数据 , 而没有变化的数据则通过虚拟地址引用到相同的物理内存地址 。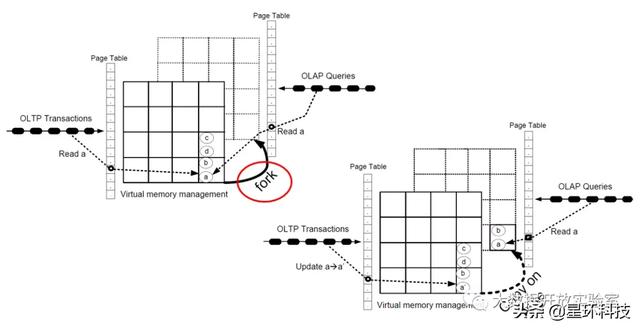 文章插图
文章插图
此外 , Hyper采用多版本控制 , 所有更新都是基于原记录的 , 每条记录都会维护一个Undo Buffer存储增量更新数据 , 并通过Version Vector指出当前最新版本 。 因此 , 可以通过Transaction找到被修改过的记录 , 同时可以通过反向应用增量数据来找回修改前的版本 , 当然也可以对数据版本进行定期融合或恢复等操作 。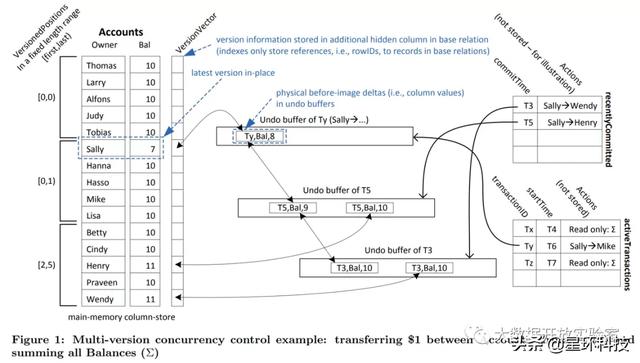 文章插图
文章插图
SAP HANA
SAP HANA是一个Non-Partition的混合存储系统 , 物理记录在存储介质中会经过三个阶段:1. 事务处理的记录存储在L1-Delta(行存方式);2. 随后记录转化为列式并存储在L2-Delta(列式存储、未排序字典编码);3. SAP HANA的主存是列存(高度压缩并采用排序字典编码) 。 每条记录经历着从行存到列存的映射合并 , 相当于一个多版本设计 。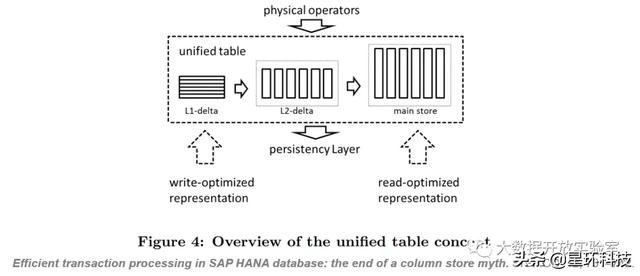 文章插图
文章插图
— 数据库管理系统中的索引技术—
内存数据库领域在设计索引时 , 主要是从面向缓存的索引技术(Cache-Awareness)和多核多CPU的并行处理(Multi-Core and Multi-Socket Parallelism)两方面进行考虑 。
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 值得|千元价位,大容量电池,大内存,双模5G,你值得拥有!
- 想象|半导体厂商警告:明年处理器内存缺货到无法想象
- 手机|手机文件夹都是英文,占空间还不敢删除,教你一招省下10G内存
- DDR5内存曝光:16GB 4800MHz快速更省电
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 详解mysql执行计划
- 第一次买这么贵的内存卡,索尼A7S3 Type-A很坑吗?