内存数据库解析与主流产品对比(二)( 三 )
由于内存数据库不再有磁盘的I/O限制 , 因此索引目的转变为加速CPU和内存之间的访问速度 。 虽然现在内存价格较低 , 但是内存速度的增速与CPU主频的增速相差依然较多 , 因此对于内存数据库 , 索引技术的目的是及时给CPU供数 , 以尽量快的速度将所需数据放入CPU的Cache中 。
对于多核多CPU的并行处理 , 80年代就开始考虑如果数据结构和数据都放在内存中 , 应该如何合理的构造索引 。 其中 , 1986年威斯康星大学的MM-DBMS项目提出了自平衡的二叉搜索树T-Tree索引 , 每个二叉节点中存储取值范围内的数据记录 , 同时有两个指针指向它的两个子节点 。 T-Tree索引结构内存开销较小 , 因为在80年代内存昂贵 , 所以主要的度量不在于性能是否最优 , 而是是否占用最小内存空间 。 T-Tree的缺点是性能问题 , 需要定期地做负载平衡 , 并且扫描和指针也会对其性能产生影响 。 早期商业系统如Times Ten中 , 采用的便是T-Tree的数据结构 。
那么索引的设计为什么需要考虑Cache-Awareness呢?1999年有研究发现内存访问中的Cache Stall或者Cache Miss是内存系统最主要的性能瓶颈 。 该研究进行了一项性能测试 , 通过对A/B/C/D 4个系统评测 , 测试以下过程的时间占比:Computation、Memory Stalls、Branch Mispredicitons和Resource Stalls 。 Computation表示真正用于计算的时间;Memory Stall是等待内存访问的时间;Branch Mispredicitons是指CPU指令分支预测失败的开销;Resource Stalls是指等待其他资源的时间开源 , 如网络、磁盘等 。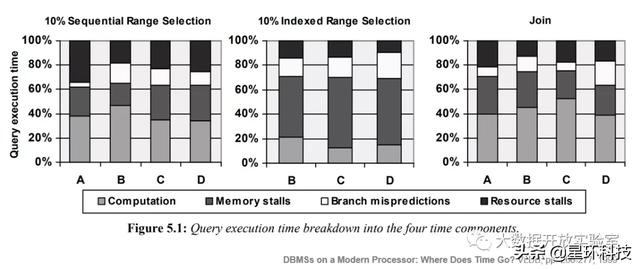 文章插图
文章插图
可以看到Memory Stall在不同的测试场景都会占据较大比例开销 。 因此对于内存索引结构来说 , 发展面向缓存的索引的主要目的就是为了减少Memory Stall的开销 。
CSB+-Tree
这里介绍几个典型的内存索引结构例子 。 第一个是CSB+-Tree , 它在逻辑上仍然是B+-Tree , 但是做了一些变化 。 首先每个Node的大小是一个Cache Line长度的倍数;同时CSB+-Tree将一个节点的所有的子节点组织成Children Group , 一个父节点通过一个指针指向它的Children Group , 目的是减少数据结构中的指针数量 。 因为CSB+-Tree的节点与Cache Line长度相匹配 , 只要依序读取 , 就可以达到较好的pre-fetche性能 。 当树分裂时 , CSB+-Tree会对内存中的Group重新分配位置 , 因为CSB+-Tree节点在内存中不需要连续 , 排好后再创建新的指针链接就可以 。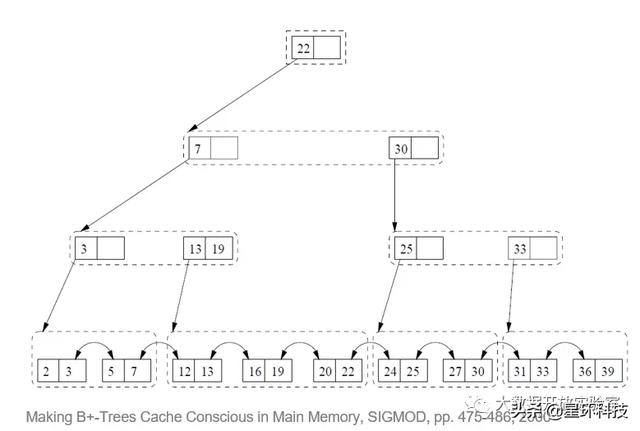 文章插图
文章插图
PB+-Trees
另一个例子是PB+-Trees(Pre-fetching B+-Tree) 。 它并不是新的结构 , 只是在内存中实现了B+-Tree , 每个节点的大小等于Cache Line的长度倍数 。 PB+-Trees比较特殊的是在整个系统实现过程中 , 引入了Pre-fetching , 通过加入一些额外信息帮助系统预取数据 。
PB+-Trees倾向于采用扁平的树来组织数据 , 论文中给出了它Search和Scan的性能 , 其中Search性能提高1.5倍 , Scan上提高了6倍 。 处理Search时的性能相比CSB+-Tree , PB+-Trees的Data Cache Stalls占比更小 。
另外一个性能对比是 , 当没有采用预取时 , 读取一个Node大小等于两个Cache Line的三级索引需要900个时钟周期 , 而加了预取后仅需要480个周期 。 PB+-Trees还有一个实现是 , 它会在每个节点加上Jump Pointer Array , 用来判断做扫描时要跳过多少Cache Line以预取下一个值 。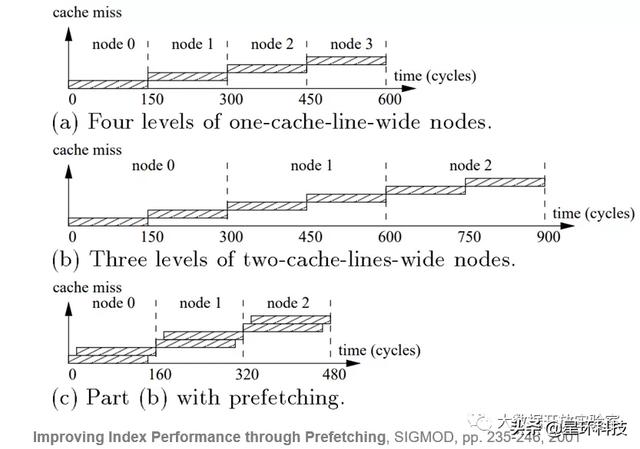 文章插图
文章插图
Bw-Tree
Bw-Tree是Hekaton系统中使用的索引 , 基本思想是通过Compare-and-Swap指令级原子操作比较内存值 , 如果新旧值相等就更新 , 如果不等则不更新 。 比如原值为20(存储在磁盘) , 而内存地址对应30 , 那么要是把30更新成40就不会成功 。 这是一个原子操作 , 可用于在多线程编程中实现不被打断的数据交换操作 。
Bw-Tree中存在Mapping Table , 每一个节点都在Mapping Table中有一个存储位置 , Mapping Table会存储节点在内存中的地址 。 对于Bw-Tree来讲 , 从父节点到子节点的指针并不是物理指针 , 而是逻辑指针 , 也就是记录在Mapping Table中的位置并不是真正的内存位置 。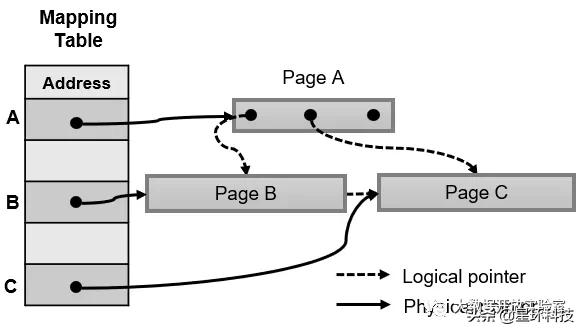 文章插图
文章插图
Bw-Tree采用的设计是节点的更新并不是直接修改节点 , 而是通过增加Delta Record(增量记录)来保存修改的内容 , 然后在Mapping Table中指向Delta Record , 如果有新的更新就继续指向新的Delta Record 。 在读取一个节点的内容时 , 实际上是合并所有的Delta Record 。 因为对Bw-Tree的更新是通过一个原子操作来实现的 , 发生竞争时只有一个改动能成功 , 因此是一种Latch-Free结构 , 只需要靠Compare-and-Swap就能够解决竞争问题 , 不再需要依赖锁机制 。
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 值得|千元价位,大容量电池,大内存,双模5G,你值得拥有!
- 想象|半导体厂商警告:明年处理器内存缺货到无法想象
- 手机|手机文件夹都是英文,占空间还不敢删除,教你一招省下10G内存
- DDR5内存曝光:16GB 4800MHz快速更省电
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 详解mysql执行计划
- 第一次买这么贵的内存卡,索尼A7S3 Type-A很坑吗?