Python3正则表达式——小白初学!最完整的教程没有之一
前言hello!这是我的第一篇博客 , 当然是是因为作业啊!在通过查阅文档 , 阅读别人所写的博客 , 和最重要的当然是自己上手操作的过程中 , 我已经初步知道正则表达式的基本语法以及如何使用了 , 就来写一篇学习笔记总结一下哦 。 作为初学者 , 错误难免有哦 , 欢迎指出来鸭 。
简介1.引入老师在引入正则表达式的时候 , 举出了这样一个例子:我们用world中写好了一篇论文 , 可是发现某个字全篇都是错误的 , 这时候是要找到一个改一个吗?肯定不是!查找替换功能轻松解决 。 文章插图
文章插图
2.正则表达式是什么这种查找替换的功能就类似于正则表达式 。 正则表达式 , 实际上是一个字符串 , 通过给定一个正则表达式和另一个字符串 , 我们可以达到如下的目的:①. 给定的字符串是否可以和正则表达式符合 。 ②. 可以通过正则表达式 , 从字符串中获取我们想要的特定部分 。 正则表达式是字符串处理的有力工具 , 但是并不是Python独有的 , 其他语言也有 。
下面我们就开始从基本语法开始学习正则表达式
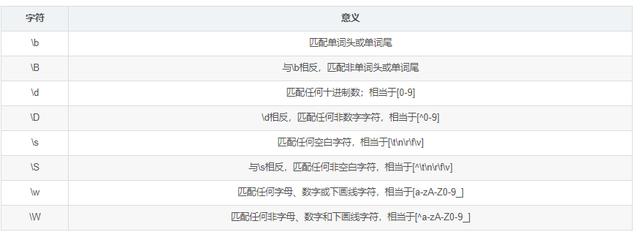
正则表达式语法1.基础知识-元字符
- 元字符有一些字符比较特殊 , 它们和自身并不匹配 , 而是表明应和一些特殊的东西匹配 , 或者会影响重复次数 。 这些特殊的字符我们称之为元字符 。
- 原始字符串在字符串前面加上字母r或R表示原始字符串 , 所有的字符都是原始的本义而不会进行任何转义 。 这个功能的实现就很像正则表达式了
代码如下(示例):
import res='hi,i am a student.my name is Tom'print(re.findall(r'.',s))12运行结果['h', 'i', ',', 'i', ' ', 'a', 'm', ' ', 'a', ' ', 's', 't', 'u', 'd', 'e', 'n', 't', '.', 'm', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'T', 'o', 'm']② " / "反斜杠后面可以加不同的字符表示不同的特殊意义“^”表示补集 , 匹配不在区间范围内的字符 , 例如:[^3]表示除3以外的字符 。
 文章插图
文章插图也可以用于取消所有的元字符:这些特殊字符都可以包含在[]中.
③ “^”:匹配行首 , 匹配以^后面的字符开头的字符串
代码如下(示例):
import res='helloTom BabyhelloMary helo'print(re.findall(r'hello',s))运行结果['hello', 'hello']④ “$”:匹配行尾 , 匹配以它之前的字符结束的字符串代码如下(示例):
s='helloTom BabyhelloMary helo'print(re.findall(r'lo',s))运行结果['lo', 'lo', 'lo']⑤ “[ ]”:常用来指定一个字符集 , 例如:[abc]、[a-z]、[0-9];元字符在方括号中不起作用 , 例如:[akm$]和[m.]中元字符都不起作用.代码如下(示例):
s='abc acd abc'print(re.findall(r'a[bc]\D*',s))print(re.findall(r'a[^b]',s))运行结果['abc acd abc']['ac']2.2指定重复次数的字符① “*”:匹配位于*之前的字符或子模式的0次或多次出现代码如下(示例):
s='aab abb abbbb b a'print(re.findall(r'ab*',s))1运行结果['a', 'ab', 'abb', 'abbbb', 'a']② “+”:匹配位于+之前的字符或子模式的1次或多次出现代码如下(示例):
s='aab abb abbbb b a'print(re.findall(r'ab+',s))12运行结果['ab', 'abb', 'abbbb']③ “?”:匹配位于?之前的0个或1个字符当“?”紧随其他限定符(*、+、{n}、{n,}、{n,m})之后时 , 匹配模式是“非贪心的” 。 “非贪心的”模式匹配搜索到尽可能短的字符串 , 而默认的“贪心的”模式匹配搜索到的、尽可能长的字符串 。 代码如下(示例):s='a ab abbbbb abbbbbxa'print(re.findall(r'ab+',s))print(re.findall(r'ab+?',s))12运行结果['ab', 'abbbbb', 'abbbbb']['ab', 'ab', 'ab']1④ “{m,n}”表示至少有m个重复 , 至多有n个重复 。 m,n均为十进制数 。 忽略m表示0个重复 , 忽略n表示无穷多个重复 。
代码如下(示例):
s1='12345 123567's2='a b baaa baaaa'print(re.findall(r'123\d{2}',s1))print(re.findall(r'a{1,3}',s2))1234运行结果['12345', '12356']['a', 'aaa', 'aaa', 'a']1re模块中常量