Apache Hudi 与 Apache Flink 集成
Apache Hudi 是由 Uber 开发并开源的数据湖框架 , 它于 2019 年 1 月进入 Apache 孵化器孵化 , 次年 5 月份顺利毕业晋升为 Apache 顶级项目 。 是当前最为热门的数据湖框架之一 。
1. 为何要解耦Hudi 自诞生至今一直使用 Spark 作为其数据处理引擎 。 如果用户想使用 Hudi 作为其数据湖框架 , 就必须在其平台技术栈中引入 Spark 。 放在几年前 , 使用 Spark 作为大数据处理引擎可以说是很平常甚至是理所当然的事 。 因为 Spark 既可以进行批处理也可以使用微批模拟流 , 流批一体 , 一套引擎解决流、批问题 。 然而 , 近年来 , 随着大数据技术的发展 , 同为大数据处理引擎的 Flink 逐渐进入人们的视野 , 并在计算引擎领域获占据了一定的市场 , 大数据处理引擎不再是一家独大 。 在大数据技术社区、论坛等领域 , Hudi 是否支持使用 Flink 计算引擎的的声音开始逐渐出现 , 并日渐频繁 。 所以使 Hudi 支持 Flink 引擎是个有价值的事情 , 而集成 Flink 引擎的前提是 Hudi 与 Spark 解耦 。
同时 , 纵观大数据领域成熟、活跃、有生命力的框架 , 无一不是设计优雅 , 能与其他框架相互融合 , 彼此借力 , 各专所长 。 因此将 Hudi 与 Spark 解耦 , 将其变成一个引擎无关的数据湖框架 , 无疑是给 Hudi 与其他组件的融合创造了更多的可能 , 使得 Hudi 能更好的融入大数据生态圈 。
2. 解耦难点Hudi 内部使用 Spark API 像我们平时开发使用 List 一样稀松平常 。 自从数据源读取数据 , 到最终写出数据列表 , 无处不是使用 Spark RDD 作为主要数据结构 , 甚至连普通的工具类 , 都使用 Spark API 实现 , 可以说 Hudi 就是用 Spark 实现的一个通用数据湖框架 , 它与 Spark 的绑定可谓是深入骨髓 。
此外 , 此次解耦后集成的首要引擎是 Flink 。 而 Flink 与 Spark 在核心抽象上差异很大 。 Spark 认为数据是有限的 , 其核心抽象是一个有限的数据集合 。 而 Flink 则认为数据的本质是流 , 其核心抽象 DataStream 中包含的是各种对数据的操作 。 同时 , Hudi 内部还存在多处同时操作多个 RDD,以及将一个 RDD 的处理结果与另一个 RDD 联合处理的情况 , 这种抽象上的区别以及实现时对于中间结果的复用 , 使得 Hudi 在解耦抽象上难以使用统一的 API 同时操作 RDD 和 DataStream 。
3. 解耦思路理论上 , Hudi 使用 Spark 作为其计算引擎无非是为了使用 Spark 的分布式计算能力以及 RDD 丰富的算子能力 。 抛开分布式计算能力外 , Hudi 更多是把 RDD 作为一个数据结构抽象 , 而 RDD 本质上又是一个有界数据集 , 因此 , 把 RDD 换成 List,在理论上完全可行(当然 , 可能会牺牲些性能) 。 为了尽可能保证 Hudi Spark 版本的性能和稳定性 。 我们可以保留将有界数据集作为基本操作单位的设定 , Hudi 主要操作 API 不变 , 将 RDD 抽取为一个泛型 , Spark 引擎实现仍旧使用 RDD , 其他引擎则根据实际情况使用 List 或者其他有界数据集 。
解耦原则:
1)统一泛型 。 Spark API 用到的 JavaRDD,JavaRDD,JavaRDD 统一使用泛型 I,K,O 代替;
【Apache Hudi 与 Apache Flink 集成】2)去 Spark 化 。 抽象层所有 API 必须与 Spark 无关 。 涉及到具体操作难以在抽象层实现的 , 改写为抽象方法 , 引入 Spark 子类实现 。
例如:Hudi 内部多处使用到了 JavaSparkContext#map() 方法 , 去 Spark 化 , 则需要将 JavaSparkContext 隐藏 , 针对该问题我们引入了 HoodieEngineContext#map() 方法 , 该方法会屏蔽 map 的具体实现细节 , 从而在抽象成实现去 Spark 化 。
3)抽象层尽量减少改动 , 保证 Hudi 原版功能和性能;
4)使用 HoodieEngineContext 抽象类替换 JavaSparkContext , 提供运行环境上下文 。
4.Flink 集成设计Hudi 的写操作在本质上是批处理 , DeltaStreamer 的连续模式是通过循环进行批处理实现的 。 为使用统一 API , Hudi 集成 Flink 时选择攒一批数据后再进行处理 , 最后统一进行提交(这里 Flink 我们使用 List 来攒批数据) 。
这批操作最容易想到的是通过使用时间窗口来实现 , 然而 , 使用窗口 , 在某个窗口没有数据流入时 , 将没有输出数据 , Sink 端难以判断同一批数据是否已经处理完 。 因此我们使用 Flink 的检查点机制来攒批 , 每两个 Barrier 之间的数据为一个批次 , 当某个子任务中没有数据时 , mock 结果数据凑数 。 这样在 Sink 端 , 当每个子任务都有结果数据下发时即可认为一批数据已经处理完成 , 可以执行 commit 。
DAG 如下: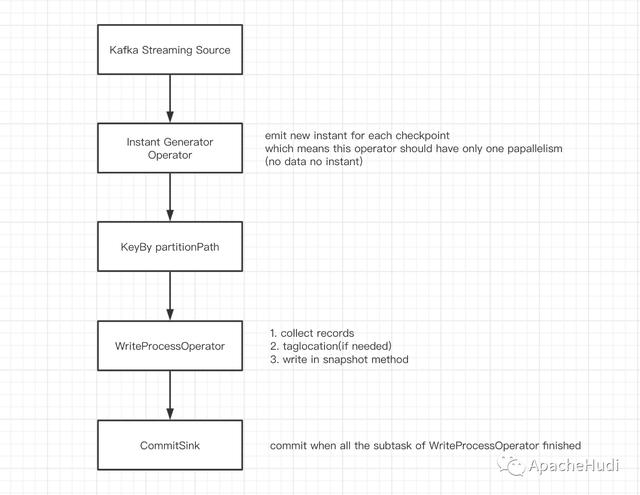 文章插图
文章插图
- 创意|wacom one万与创意数位屏测评
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- YFI正式宣布与Sushiswap合作|金色DeFi日报 | 合作
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 迁徙|网红迁徙记:哪里才是奶与蜜之地?
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 按键|苹果与宜家合作智能家居快捷按键,定价9.99美元