基于Flink+ClickHouse打造轻量级点击流实时数仓
【基于Flink+ClickHouse打造轻量级点击流实时数仓】Flink 和 ClickHouse 分别是实时计算和(近实时)OLAP 领域的翘楚 , 也是近些年非常火爆的开源框架 , 很多大厂都在将两者结合使用来构建各种用途的实时平台 , 效果很好 。 关于两者的优点就不再赘述 , 本文来简单介绍笔者团队在点击流实时数仓方面的一点实践经验 。
点击流及其维度建模所谓点击流(click stream) , 就是指用户访问网站、App 等 Web 前端时在后端留下的轨迹数据 , 也是流量分析(traffic analysis)和用户行为分析(user behavior analysis)的基础 。 点击流数据一般以访问日志和埋点日志的形式存储 , 其特点是量大、维度丰富 。 以我们一个中等体量的普通电商平台为例 , 每天产生约 200GB 左右、数十亿条的原始日志 , 埋点事件 100+ 个 , 涉及 50+ 个维度 。
按照 Kimball 的维度建模理论 , 点击流数仓遵循典型的星形模型 , 简图如下 。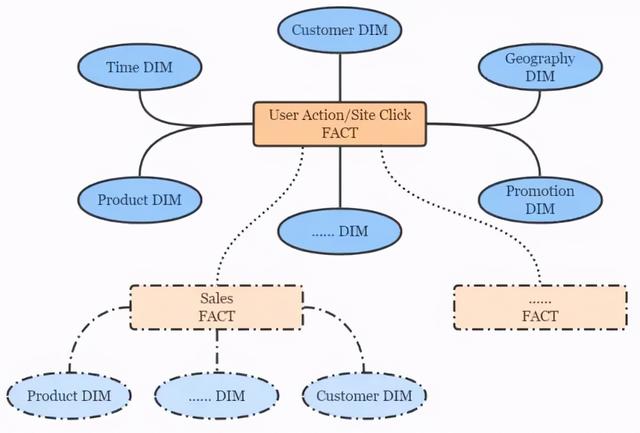 文章插图
文章插图
点击流数仓分层设计点击流实时数仓的分层设计仍然可以借鉴传统数仓的方案 , 以扁平为上策 , 尽量减少数据传输中途的延迟 。 简图如下 。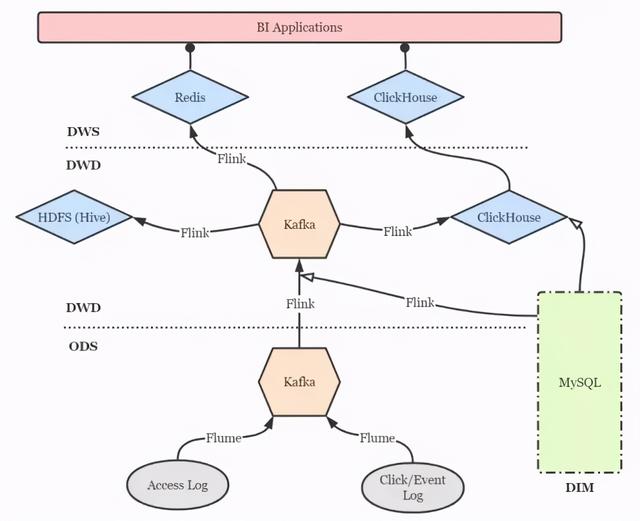 文章插图
文章插图
- DIM 层:维度层 , MySQL 镜像库 , 存储所有维度数据 。
- ODS 层:贴源层 , 原始数据由 Flume 直接进入 Kafka 的对应 topic 。
- DWD 层:明细层 , 通过 Flink 将 Kafka 中数据进行必要的 ETL 与实时维度 join 操作 , 形成规范的明细数据 , 并写回 Kafka 以便下游与其他业务使用 。 再通过 Flink 将明细数据分别写入 ClickHouse 和 Hive 打成大宽表 , 前者作为查询与分析的核心 , 后者作为备份和数据质量保证(对数、补数等) 。
- DWS 层:服务层 , 部分指标通过 Flink 实时汇总至 Redis , 供大屏类业务使用 。 更多的指标则通过 ClickHouse 物化视图等机制周期性汇总 , 形成报表与页面热力图 。 特别地 , 部分明细数据也在此层开放 , 方便高级 BI 人员进行漏斗、留存、用户路径等灵活的 ad-hoc 查询 , 这些也是 ClickHouse 远超过其他 OLAP 引擎的强大之处 。
Flink 框架的异步 I/O 机制为用户在流式作业中访问外部存储提供了很大的便利 。 针对我们的情况 , 有以下三点需要注意:
- 使用异步 MySQL 客户端 , 如 Vert.x MySQL Client 。
- AsyncFunction 内添加内存缓存(如 Guava Cache、Caffeine 等) , 并设定合理的缓存驱逐机制 , 避免频繁请求 MySQL 库 。
- 实时维度关联仅适用于缓慢变化维度 , 如地理位置信息、商品及分类信息等 。 快速变化维度(如用户信息)则不太适合打进宽表 , 我们采用 MySQL 表引擎将快变维度表直接映射到 ClickHouse 中 , 而 ClickHouse 支持异构查询 , 也能够支撑规模较小的维表 join 场景 。 未来则考虑使用 MaterializedMySQL 引擎(当前仍未正式发布)将部分维度表通过 binlog 镜像到 ClickHouse 。
可以通过 JDBC(flink-connector-jdbc)方式来直接写入 ClickHouse , 但灵活性欠佳 。 好在 clickhouse-jdbc 项目提供了适配 ClickHouse 集群的 BalancedClickhouseDataSource 组件 , 我们基于它设计了 Flink-ClickHouse Sink , 要点有三:
- 写入本地表 , 而非分布式表 , 老生常谈了 。
- 按数据批次大小以及批次间隔两个条件控制写入频率 , 在 part merge 压力和数据实时性两方面取得平衡 。 目前我们采用 10000 条的批次大小与 15 秒的间隔 , 只要满足其一则触发写入 。
- BalancedClickhouseDataSource 通过随机路由保证了各 ClickHouse 实例的负载均衡 , 但是只是通过周期性 ping 来探活 , 并屏蔽掉当前不能访问的实例 , 而没有故障转移——亦即一旦试图写入已经失败的节点 , 就会丢失数据 。 为此我们设计了重试机制 , 重试次数和间隔均可配置 , 如果当重试机会耗尽后仍然无法成功写入 , 就将该批次数据转存至配置好的路径下 , 并报警要求及时检查与回填 。
还有一点就是 , ClickHouse 并不支持事务 , 所以也不必费心考虑 2PC Sink 等保证 exactly once 语义的操作 。 如果 Flink 到 ClickHouse 的链路出现问题导致作业重启 , 作业会直接从最新的位点(即 Kafka 的 latest offset)开始消费 , 丢失的数据再经由 Hive 进行回填即可 。
- 注册|阿里申请注册“爆改吧!小店”商标,打造线下特色实体小店
- 中国|中国软件国际与深圳市政府达成战略合作协议 助力打造“创新之都“
- 流量|蔡林记总经理张绪明:电商、外卖弥补实体店损失,将打造私域流量
- 广州国际创新节|大咖谈新基建:打造新经济时代的数字引擎
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 搜违禁词将出现公益宣导页 看“绿网计划”如何打造安全网
- 搭档|台湾、东北小伙搭档 打造用工领域“滴滴打车”
- 打造|广西移动5G为打造“数字丝绸之路”提档加速
- 深度|专为年轻人打造的高端机 Redmi K30S至尊纪念版深度实测
- 如何基于Python实现自动化控制鼠标和键盘操作