基于学习转换的一次性医学图像分割中的数据扩增( 四 )
耦合采样:为了突出本文的独立变换模型的有效性 , 本文将本文的方法与本文的方法的一个变体进行比较 , 其中本文从相同的目标图像中对每个空间和外观变换进行采样 。这导致了 100 个可能的合成例子 。与本文的方法一样 , 本文在每个训练迭代中合成了一个随机样本 。
在训练分段器时 , 本文使用 ours-indep 合成的例子和使用 rand-aug 合成的例子进行交替 。在本文的合成扩增中加入手工调谐扩增可以引入额外的方差(即使在未标记的集合中也是看不见的)从而提高分割器的鲁棒性 。
4.4 评价指标
本文用 Dice 评分[23]来评估每种分割方法的准确性 , 它量化了两个解剖区域之间的重叠程度 。骰子得分为 1 表示完全重叠的区域 , 而 0 表示没有重叠 。预测的分割标签是相对于使用 FreeSurfer[27]生成的解剖标签进行评估的 。
4.5 结果
图 4:与 SAS 基线相比 , 平均基线相比 , 平均 Dice 评分(在所有 30 个解剖标签上计算的平均值)的配对改善 。 文章插图
文章插图
图 5:与 SAS 基线相比 , 平均 Dice 评分(在所有 30 个解剖标签上计算的平均值)的配对改善 , 显示为每个测试对象 。受试者按 Dicei 排序 本文在 SAS 上的进步 。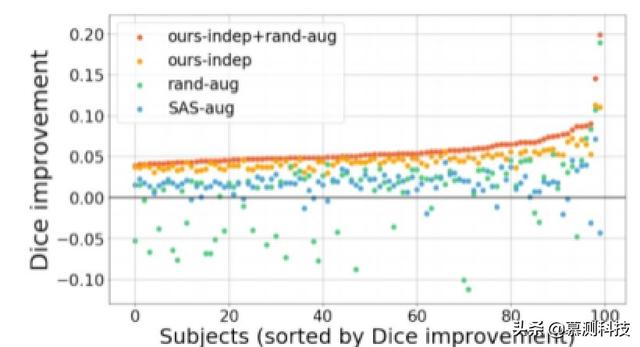 文章插图
文章插图
图 6:每种方法在不同脑结构中的分割精度 。标签按图册中各结构所占体积进行排序(括号中显示) , 标签由 o 组成 左、右结构(如海马)结合在一起 。本文缩写标签:白质(WM)、皮层(CX)、心室(通风口)和脑脊液(CSF) 。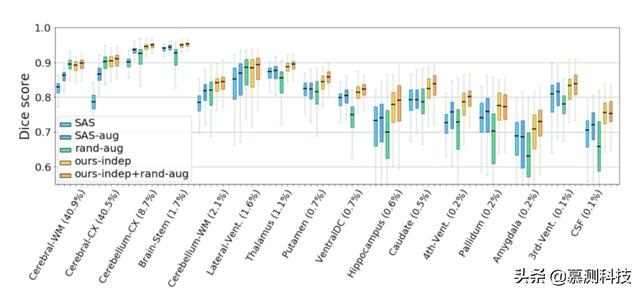 文章插图
文章插图
图 7:两个测试对象(行)的海马分割预测) 。本文的方法(第 2 栏)比基线(第 3 和第 4 栏)产生更精确的分段) 。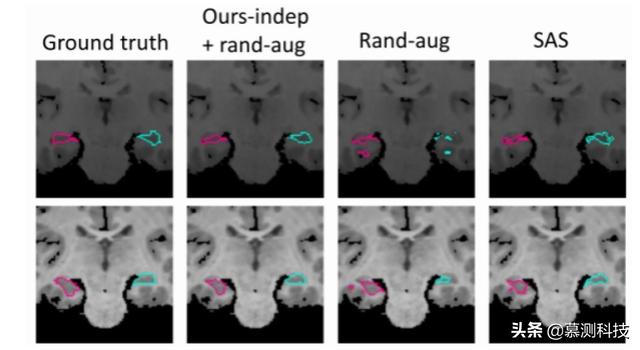 文章插图
文章插图
图 8:由于本文独立地对空间和外观转换进行建模 , 本文能够合成各种组合效果 。本文展示了一些使用所学转换合成的示例 从训练集;这些转换构成了本文的扩增模型的基础 。上面一行显示了一个合成图像 , 其中外观变换产生了变暗的效果 , 以及水疗中心 蒂尔转化缩小了心室 , 扩大了整个大脑 。第二排 , 图谱变亮 , 脑室扩大 。 文章插图
文章插图
图 9:由 SAS-Aug(第 2 栏)和本文的耦合(第 3 栏)生成的综合训练示例) 。当空间模型(两种方法都使用)产生不完全扭曲的标签时 , SAS-Aug 对战争进行配对 带有不正确图像纹理的 PED 标签 。本文的方法仍然通过将合成的图像纹理与标签匹配来生成一个有用的训练示例 。 文章插图
文章插图
4.5.1 分割性能
表 1 显示了每种方法的分割精度 。本文的方法优于所有基线 。
在图 4 图 5 中 , 本文比较了每种方法与单岩分割基线 。
图 4 表明 , 本文的方法得到了最大的改进 , 并且比手工调整的随机扩增更一致 。
图 5 表明 ours-indep+rand-aug 在每个测试主题上始终优于每个基线 。ours-indep 总是比 SAS-aug 和 SAS 更好 , 并且在 100 次测试扫描中的 95 次中优于 rand-aug 。
图 6 表明 rand-aug 在大的解剖结构上改善了 Dice 而不是 SAS , 但对较小的结构是有害的 。相反 , 本文的方法在所有结构中对 SAS 和 SAS-aug 进行了一致的改进 。本文在图 7 中展示了几个的例子 。
4.5.2 合成的图像
本文独立的空间和外观模型能够合成各种各样的大脑外观图像 。图 8 展示的一些例子中表示组合转换会产生真实的结果和准确的标签 。
5.讨论为什么本文优于单 atlas 分割? 本文的方法依赖于相同的空间配准模型 , 用于 SAS 和 SAS-aug 。Ours-coupled 和 SAS-aug 都增加了 100 个新图像的分割器训练集 。
为了理解为什么本文的方法产生更好的分割 , 本文检查了扩增图像 。本文的方法以与标签相同的方式扭曲图像 , 确保扭曲的标签与转换后的图像相匹配 。另一方面 , SAS-aug 将扭曲的标签应用于原始图像 , 因此注册中的任何错误或噪声都会导致分割器标记错误的新训练样本 。图 9 突出了本文的方法在海马标签中合成图像纹理的例子 , 这些图像纹理与地面真实的纹理更一致 , 从而形成了一个更有用的合成训练样本 。
扩展 本文的框架适合于几个可能的未来扩展 。在第 3.1 节中 , 本文讨论了在图集参考框架中使用近似反变形函数来学习外观变换 。而不是学习一个单独的逆空间变换模型 , 在未来 , 本文会将现有的工作应用于不同的配准[3,5,10,20,81] 。
- wmv|怎么把mp4转wmv?转换视频格式,这样操作很掂
- 用于|用于半监督学习的图随机神经网络
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 今日|“舜网”学习强国号今日上线 济南报业全媒体矩阵再添新成员
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 效果|这个让你相见恨晚的技巧,能让PPT排版更加有设计感,推荐学习
- 如何基于Python实现自动化控制鼠标和键盘操作
- 学习C语言的软件,就突然被我绿了?
- 学习python第二弹
- 喵喵机错题打印机P1:随时打印,随时学习,快速整理错题