新手?没做过多线程实践?来,其实很简单,看完秒会( 二 )
这时多线程就发挥优势了 , 由多个线程分别去读取文件最后汇总结果即可 。
这样实现的过程就变为:
- 读取某个目录下的所有文件 。
- 将文件路径交由不同的线程自行处理 。
- 最终汇总结果 。
简单来说就是怎么保证多线程和单线程统计的总字数是一致的 。
基于我本地的环境先看看单线程运行的结果:
 文章插图
文章插图总计为:414142 字 。
接下来换为多线程的方式:
List allFile = scannerFile.getAllFile(strings[0]);logger.info("allFile size=[{}]",allFile.size());for (String msg : allFile) { executorService.execute(new ScanNumTask(msg,filterProcessManager));}public class ScanNumTask implements Runnable {private static Logger logger = LoggerFactory.getLogger(ScanNumTask.class);private String path;private FilterProcessManager filterProcessManager;public ScanNumTask(String path, FilterProcessManager filterProcessManager) {this.path = path;this.filterProcessManager = filterProcessManager;}@Overridepublic void run() {Stream stringStream = null;try {stringStream = Files.lines(Paths.get(path), StandardCharsets.UTF_8);} catch (Exception e) {logger.error("IOException", e);}List collect = stringStream.collect(Collectors.toList());for (String msg : collect) {filterProcessManager.process(msg);}}}使用线程池管理线程 , 更多线程池相关的内容请看这里:《如何优雅的使用和理解线程池》执行结果:
 文章插图
文章插图我们会发现无论执行多少次 , 这个值都会小于我们的预期值 。
来看看统计那里是怎么实现的 。
@Componentpublic class TotalWords {private long sum = 0 ;public void sum(int count){sum += count;}public long total(){return sum;}}可以看到就是对一个基本类型进行累加而已 。 那导致这个值比预期小的原因是什么呢?我想大部分人都会说:多线程运行时会导致有些线程把其他线程运算的值覆盖 。
但其实这只是导致这个问题的表象 , 根本原因还是没有讲清楚 。
内存可见性核心原因其实是由 Java 内存模型(JMM)的规定导致的 。
这里引用一段之前写的《你应该知道的 volatile 关键字》一段解释:
由于 Java 内存模型(JMM)规定 , 所有的变量都存放在主内存中 , 而每个线程都有着自己的工作内存(高速缓存) 。
线程在工作时 , 需要将主内存中的数据拷贝到工作内存中 。 这样对数据的任何操作都是基于工作内存(效率提高) , 并且不能直接操作主内存以及其他线程工作内存中的数据 , 之后再将更新之后的数据刷新到主内存中 。
这里所提到的主内存可以简单认为是堆内存 , 而工作内存则可以认为是栈内存 。
如下图所示:
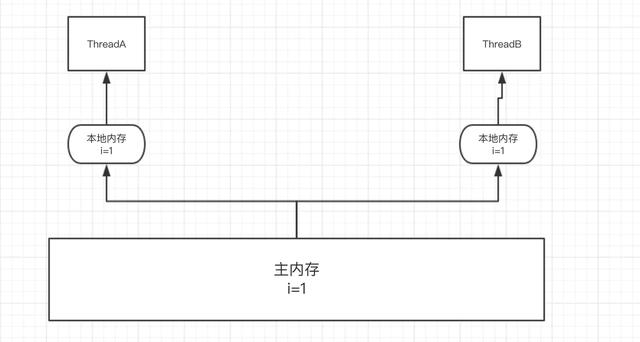 文章插图
文章插图所以在并发运行时可能会出现线程 B 所读取到的数据是线程 A 更新之前的数据 。
更多相关内容就不再展开了 , 感兴趣的朋友可以翻翻以前的博文 。
直接来说如何解决这个问题吧 , JDK 其实已经帮我们想到了这些问题 。
在 java.util.concurrent 并发包下有许多你可能会使用到的并发工具 。
这里就非常适合 AtomicLong , 它可以原子性的对数据进行修改 。
来看看修改后的实现:
@Componentpublic class TotalWords {private AtomicLong sum = new AtomicLong() ;public void sum(int count){sum.addAndGet(count) ;}publiclong total(){return sum.get() ;}}只是使用了它的两个 API 而已 。 再来运行下程序会发现结果居然还是不对 。 文章插图
文章插图甚至为 0 了 。
线程间通信这时又出现了一个新的问题 , 来看看获取总计数据是怎么实现的 。
List allFile = scannerFile.getAllFile(strings[0]);logger.info("allFile size=[{}]",allFile.size());for (String msg : allFile) { executorService.execute(new ScanNumTask(msg,filterProcessManager));}executorService.shutdown();long total = totalWords.total();long end = System.currentTimeMillis();logger.info("total sum=[{}],[{}] ms",total,end-start);不知道大家看出问题没有 , 其实是在最后打印总数时并不知道其他线程是否已经执行完毕了 。因为 executorService.execute() 会直接返回 , 所以当打印获取数据时还没有一个线程执行完毕 , 也就导致了这样的结果 。
关于线程间通信之前我也写过相关的内容:《深入理解线程通信》
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 参数|外行看参数内行看细节,新手能牢记这四点,你也算半个内行了
- 如何在电脑上看4K UHD原盘电影(新手教学)
- 腾讯数据工程师推荐的Python新手入门书籍,还是首发电子版
- 新手陷阱:你在编程时会犯的6种错误
- 年轻|接班人明确自身价值,全新手机定格让自拍更美,年轻真好
- 推出的手机|年底想换新手机?iQOO这几款人气机型值得你考虑
- 白话评说四款苹果新手机,非技术性,仅就适用性讨论
- 小白|新手小白如何开始直播带货?掌握这四点,分分钟成为直播带货大师