新手?没做过多线程实践?来,其实很简单,看完秒会
前言前段时间在某个第三方平台看到我写作字数居然突破了 10W 字 , 难以想象高中 800 字作文我都得巧妙的利用换行来完成(懂的人肯定也干过) 。
干了这行养成了一个习惯:能撸码验证的事情都自己验证一遍 。
于是在上周五通宵加班的空余时间写了一个工具:
利用 SpringBoot 只需要一行命令即可统计自己写了多少个字 。
java -jar nows-0.0.1-SNAPSHOT.jar /xx/Hexo/source/_posts传入需要扫描的文章目录即可输出结果(目前只支持 .md 结尾 Markdown 文件) 文章插图
文章插图
当然结果看个乐就行(40 几万字) , 因为早期的博客我喜欢大篇的贴代码 , 还有一些英文单词也没有过滤 , 所以导致结果相差较大 。
如果仅仅只是中文文字统计肯定是准的 , 并且该工具内置灵活的扩展方式 , 使用者可以自定义统计策略 , 具体请看后文 。
其实这个工具挺简单的 , 代码量也少 , 没有多少可以值得拿出来讲的 。 但经过我回忆不管是面试还是和网友们交流都发现一个普遍的现象:
大部分新手开发都会去看多线程、但几乎都没有相关的实践 。 甚至有些都不知道多线程拿来在实际开发中有什么用 。
为此我想基于这个简单的工具为这类朋友带来一个可实践、易理解的多线程案例 。
至少可以让你知道:
- 为什么需要多线程?
- 怎么实现一个多线程程序?
- 多线程带来的问题及解决方案?
本次的需求也很简单 , 只是需要扫描一个目录读取下面的所有文件即可 。
所以我们的实现有以下几步:
- 读取某个目录下的所有文件 。
- 将所有文件的路径保持到内存 。
- 遍历所有的文件挨个读取文本记录字数即可 。
这样的场景就非常适合递归:
public List getAllFile(String path){File f = new File(path) ;File[] files = f.listFiles();for (File file : files) {if (file.isDirectory()){String directoryPath = file.getPath();getAllFile(directoryPath);}else {String filePath = file.getPath();if (!filePath.endsWith(".md")){continue;}allFile.add(filePath) ;}}return allFile ;}}读取之后将文件的路径保持到一个集合中 。需要注意的是这个递归次数需要控制下 , 避免出现栈溢出(StackOverflow) 。
最后读取文件内容则是使用 Java8 中的流来进行读取 , 这样代码可以更简洁:
Stream stringStream = Files.lines(Paths.get(path), StandardCharsets.UTF_8);List collect = stringStream.collect(Collectors.toList());接下来便是读取字数 , 同时要过滤一些特殊文本(比如我想过滤掉所有的空格、换行、超链接等) 。扩展能力简单处理可在上面的代码中遍历 collect 然后把其中需要过滤的内容替换为空就行 。
【新手?没做过多线程实践?来,其实很简单,看完秒会】但每个人的想法可能都不一样 。 比如我只想过滤掉空格、换行、超链接就行了 , 但有些人需要去掉其中所有的英文单词 , 甚至换行还得留着(就像写作文一样可以充字数) 。
所以这就需要一个比较灵活的处理方式 。
看过上文《利用责任链模式设计一个拦截器》应该很容易想到这样的场景责任链模式再合适不过了 。
关于责任链模式具体的内容就不再详述了 , 感兴趣的可以查看上文 。
这里直接看实现吧:
定义责任链的抽象接口及处理方法:
public interface FilterProcess {/*** 处理文本* @param msg* @return*/String process(String msg) ;}处理空格和换行的实现:public class WrapFilterProcess implements FilterProcess{@Overridepublic String process(String msg) {msg = msg.replaceAll("\\s*", "");return msg ;}}处理超链接的实现:public class HttpFilterProcess implements FilterProcess{@Overridepublic String process(String msg) {msg = msg.replaceAll("^((https|http|ftp|rtsp|mms)?:\\/\\/)[^\\s]+","");return msg ;}}这样在初始化时需要将这些处理 handle 都加入责任链中 , 同时提供一个 API 供客户端执行即可 。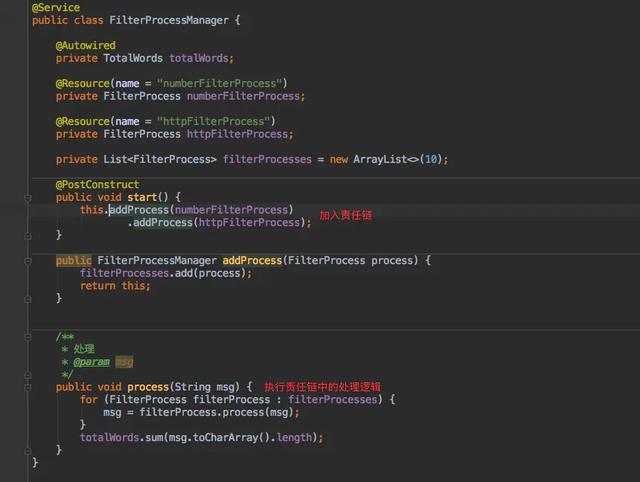 文章插图
文章插图这样一个简单的统计字数的工具就完成了 。
多线程模式在我本地一共就几十篇博客的条件下执行一次还是很快的 , 但如果我们的文件是几万、几十万甚至上百万呢 。
虽然功能可以实现 , 但可以想象这样的耗时绝对是成倍的增加 。
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 参数|外行看参数内行看细节,新手能牢记这四点,你也算半个内行了
- 如何在电脑上看4K UHD原盘电影(新手教学)
- 腾讯数据工程师推荐的Python新手入门书籍,还是首发电子版
- 新手陷阱:你在编程时会犯的6种错误
- 年轻|接班人明确自身价值,全新手机定格让自拍更美,年轻真好
- 推出的手机|年底想换新手机?iQOO这几款人气机型值得你考虑
- 白话评说四款苹果新手机,非技术性,仅就适用性讨论
- 小白|新手小白如何开始直播带货?掌握这四点,分分钟成为直播带货大师