Databricks入门:分析COVID-19( 二 )
我们将尝试预测Minas Gerais(MG)未来的死亡人数 。 所以第一步是收集我们的数据 。
也许你需要清除你Notebook的状态
import pandas as pdimport logginglogger = spark._jvm.org.apache.log4jlogging.getLogger("py4j").setLevel(logging.ERROR)query = """ SELECT string(date) as ds, int(deaths) as y FROM covid WHERE state = "MG" and place_type = "state" order by date"""df = spark.sql(query)df = df.toPandas()display(df)接下来 , 我们将使用Prophet拟合模型并最终绘制预测
from fbprophet import Prophetm = Prophet()m.fit(df)future = m.make_future_dataframe(periods=30)forecast = m.predict(future)fig1 = m.plot(forecast)你应该看到下面的图表和预测: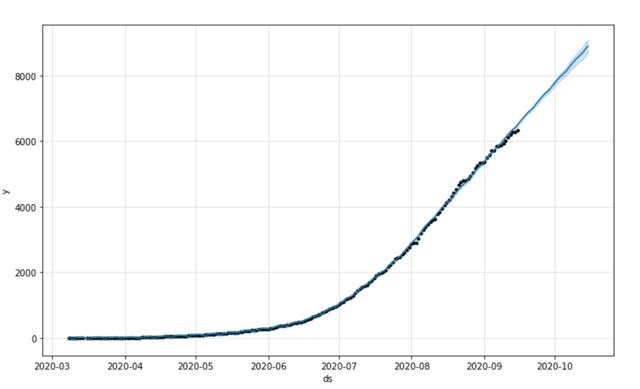 文章插图
文章插图
结论我们的目标是演示数据科学工作流的所有步骤 。 这就是为什么我们没有描述时间序列模型是如何工作的 。 如果你遵循本教程 , 你应该对Databricks平台有一个很好的了解 。
GitHub:
- 资本|2020年中国人工智能医疗行业发展现状分析 处于成长期且资本热度高
- 用户|密室逃脱行业发展及用户分析报告:哪些人在沉迷密室逃脱?
- 框架|三种数据分析思维框架的构建方法
- 分析师|真香定律或再被验证,iPhone12将大卖,分析师给出两个原因
- 文章|局座张召忠:分析局座历年的文章发现,我发现这些秘密
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 市场|2020年全球智能手机行业市场竞争格局分析 中国品牌在北美市场缺乏一定优势
- 开发人员|ER(实体关系)建模入门指引
- 时间|19824.66美元!比特币突破近三年高价 分析师:创新高不代表行情将持续上升