如何在PyTorch和TensorFlow中训练图像分类模型( 二 )
# transformations to be applied on imagestransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)),])现在 , 让我们加载MNIST数据集的训练和测试集:
# defining the training and testing settrainset = datasets.MNIST('./data', download=True, train=True, transform=transform)testset = datasets.MNIST('./', download=True, train=False, transform=transform)接下来 , 我定义了训练和测试加载器 , 这将帮助我们分批加载训练和测试集 。 我将批量大小定义为64:
# defining trainloader and testloadertrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)首先让我们看一下训练集的摘要:
# shape of training datadataiter = iter(trainloader)images, labels = dataiter.next()print(images.shape)print(labels.shape)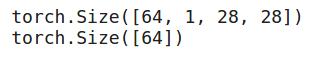 文章插图
文章插图
因此 , 在每个批次中 , 我们有64个图像 , 每个图像的大小为28,28 , 并且对于每个图像 , 我们都有一个相应的标签 。 让我们可视化训练图像并查看其外观:
# visualizing the training imagesplt.imshow(images[0].numpy().squeeze(), cmap='gray')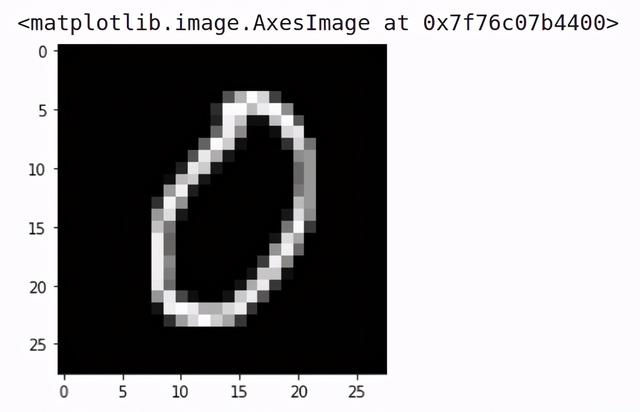 文章插图
文章插图
它是数字0的图像 。 类似地 , 让我们可视化测试集图像:
# shape of validation datadataiter = iter(testloader)images, labels = dataiter.next()print(images.shape)print(labels.shape)在测试集中 , 我们也有大小为64的批次 。 现在让我们定义架构
定义模型架构我们将在这里使用CNN模型 。 因此 , 让我们定义并训练该模型:
# defining the model architectureclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.cnn_layers = nn.Sequential(# Defining a 2D convolution layernn.Conv2d(1, 4, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(4),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Defining another 2D convolution layernn.Conv2d(4, 4, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(4),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.linear_layers = nn.Sequential(nn.Linear(4 * 7 * 7, 10))# Defining the forward passdef forward(self, x):x = self.cnn_layers(x)x = x.view(x.size(0), -1)x = self.linear_layers(x)return x我们还定义优化器和损失函数 , 然后我们将看一下该模型的摘要:
# defining the modelmodel = Net()# defining the optimizeroptimizer = optim.Adam(model.parameters(), lr=0.01)# defining the loss functioncriterion = nn.CrossEntropyLoss()# checking if GPU is availableif torch.cuda.is_available():model = model.cuda()criterion = criterion.cuda()print(model) 文章插图
文章插图
因此 , 我们有2个卷积层 , 这将有助于从图像中提取特征 。 这些卷积层的特征传递到完全连接的层 , 该层将图像分类为各自的类别 。 现在我们的模型架构已准备就绪 , 让我们训练此模型十个时期:
for i in range(10):running_loss = 0for images, labels in trainloader:if torch.cuda.is_available():images = images.cuda()labels = labels.cuda()# Training passoptimizer.zero_grad()output = model(images)loss = criterion(output, labels)#This is where the model learns by backpropagatingloss.backward()#And optimizes its weights hereoptimizer.step()running_loss += loss.item()else:print("Epoch {} - Training loss: {}".format(i+1, running_loss/len(trainloader)))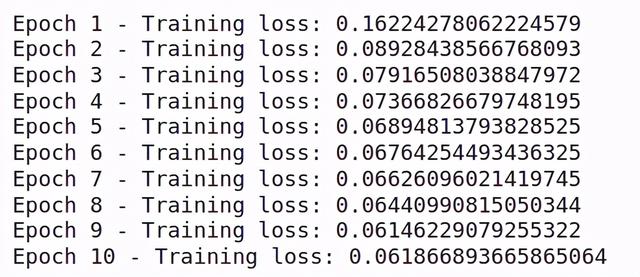 文章插图
文章插图
你会看到训练随着时期的增加而减少 。 这意味着我们的模型是从训练集中学习模式 。 让我们在测试集上检查该模型的性能:
# getting predictions on test set and measuring the performancecorrect_count, all_count = 0, 0for images,labels in testloader:for i in range(len(labels)):if torch.cuda.is_available():images = images.cuda()labels = labels.cuda()img = images[i].view(1, 1, 28, 28)with torch.no_grad():logps = model(img)ps = torch.exp(logps)probab = list(ps.cpu()[0])pred_label = probab.index(max(probab))true_label = labels.cpu()[i]if(true_label == pred_label):correct_count += 1all_count += 1print("Number Of Images Tested =", all_count)print("\nModel Accuracy =", (correct_count/all_count)) 文章插图
文章插图
因此 , 我们总共测试了10000张图片 , 并且该模型在预测测试图片的标签方面的准确率约为96% 。
这是你可以在PyTorch中构建卷积神经网络的方法 。 在下一节中 , 我们将研究如何在TensorFlow中实现相同的体系结构 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐