数据扩增技术如何实现正 margin 距离?( 三 )
 文章插图
文章插图
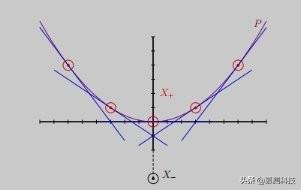
2.2 随机扰动我们的结果表明 , 在扰动的大小 , 扰动的数量 , margin 距离以及是否保持线性可分离性之间存在着一种权衡关系 。 如果我们构造许多大的扰动 , 就可能会违反线性可分离性 , 但是如果我们使用的扰动太小 , 则只能获得较小的 margin 距离 。
三 结论数据扩增是在模型训练过程中的常用方法 , 因为它可以显著提高模型的鲁棒性 。 本文中 , 我们从 margin 距离的角度分析了数据扩增技术的性能 。 我们已经展示了数据扩增如何在经验风险最小化方法中去保证正的 margin 距离 。 对于线性分类器 , 我们提供了确保正 margin 距离所需的点数下限 , 并分析了附加球面数据扩充所获得的 margin 距离标准 。 我们计划在将来解决一些开放问题 。 首先 , 最新的数据扩增方法(例如随机裁剪 , 翻转和旋转)需要通过理论分析去证明其有效性 。 这种扰动通常不在我们的算法框架之内 , 因为它们不受任何规范的限制 。 另一个研究方向是分析自适应数据扩增技术的性能 , 比如对抗性训练就是自适应数据扩增的一种形式 。 我们希望可以利用领域知识来训练出具有更优鲁棒性和可泛化特性的模型 。
致谢【数据扩增技术如何实现正 margin 距离?】本论文由 iSE 实验室 2019 级硕士生邓靖琦转述 。
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 中国|浅谈5G移动通信技术的前世和今生
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 视频社会生产力报告|视频社会雏形已成,绿厂或凭这技术抢占先机
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在