在python中使用KNN算法处理缺失的数据( 二 )
现在 , 我们可以使用修改后的数据集(在3列中缺少值)调用optimize_k函数 , 并传入目标变量(MEDV):
k_errors = optimize_k(data=http://kandian.youth.cn/index/df, target='MEDV')就是这样! k_errors数组如下所示: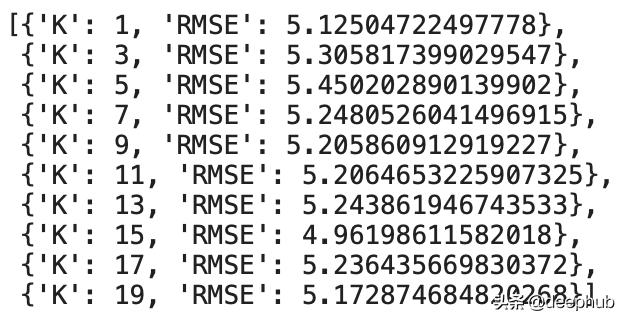 文章插图
文章插图
以视觉方式表示: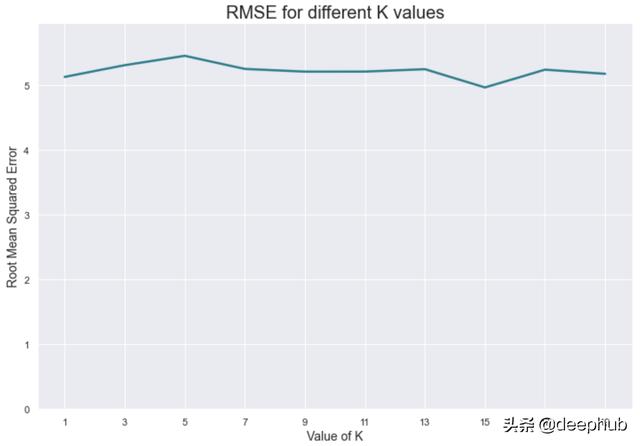 文章插图
文章插图
看起来K = 15是给定范围内的最佳值 , 因为它导致最小的误差 。我们不会涵盖该错误的解释 , 因为它超出了本文的范围 。让我们在下一节中总结一下 。
总结编写处理缺少数据归因的代码很容易 , 因为有很多现有的算法可以让我们直接使用 。但是我们很难理解里面原因-了解应该推定哪些属性 , 不应该推算哪些属性 。例如 , 可能由于客户未使用该类型的服务而缺失了某些值 , 因此没有必要执行估算 。
最终确定是否需要进行缺失数据的处理 , 还需要有领域的专业知识 , 与领域专家进行咨询并研究领域是一种很好的方法 。
作者:Dario Rade?i?
deephub翻译组
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 行业|现在行业内客服托管费用是怎么算的
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 中国|浅谈5G移动通信技术的前世和今生
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!