构建 Netflix 分布式追踪(tracing)体系
“为什么我的手机不能播放 Tiger King?”
— 一位 Twitter 网友留言
这是 Netflix on-call 工程师面临问题的一个例子:解决用户碰到的各种问题 。 排除这种分布式系统的故障非常困难 。 调查视频流故障需要检查用户账户的所有方面 。 在上一篇博文(1)中介绍了 Edgar , 我们的流 sesion 故障排除工具 。 本文主要看我们是如何设计 Edgar 的追踪 (tracing) 基础设施 。
(1)
分布式跟踪:提供大规模服务中故障排查的上下文
在使用 Edgar 之前 , 工程师必须从 Netflix 的各种微服务中筛选出大量的元数据和日志 , 以了解我们任何用户所经历的特定流媒体故障 。 重建流 session 是一个繁琐而耗时的过程 , 其中涉及到追踪 Netflix 应用、CDN 网络和后端微服务之间的所有交互(请求) 。
这个过程从手动拉取作 session 的用户账户信息开始 , 并将所有的拼图碎片放在一起 , 希望由此产生的全景能够帮助解决用户问题 。 因此需要通过分布式请求追踪系统来提高生产力 。
如果我们为每个流 session 提供一个ID , 那么分布式追踪就可以通过提供服务拓扑、重试和错误标签以及所有服务调用的延迟测量来轻松重建会话失败 。 我们还可以通过将相关的跟踪与账户元数据和服务日志结合起来 , 获得有关流 session 的上下文信息 。 这种需求促使我们建立了 Edgar:一个分布式跟踪基础设施以及用户体验 。
Edgar: a distributed tracing infrastructure and user experience.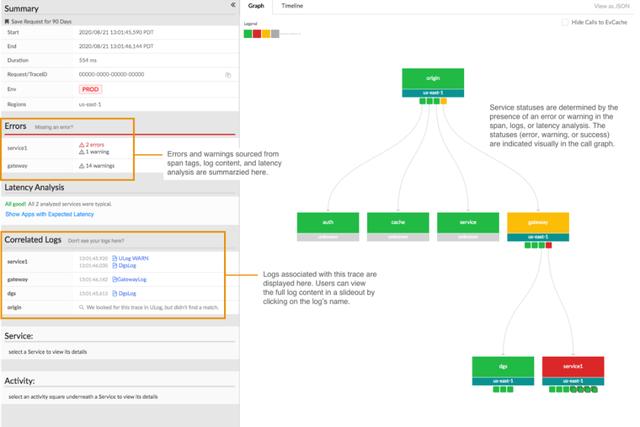 文章插图
文章插图
图 1. 通过 Edgar 排查一个会话
4 年前 , 当开始构建 Edgar 时 , 能够满足我们需求的开源分布式追踪系统非常少 。 我们的策略是 , 在开源 trace 库成熟之前 , 使用 Netflix 专用工具来收集基于 Java 的流媒体服务的 trace 信息 。
到 2017 年 , Open-Tracing(1) 和Open-Zipkin(2) 等开源项目已经足够成熟 , 可以在 Netflix 的混合运行环境中使用 。 我们选择了 Open-Zipkin 。 因为它能与我们基于 Spring Boot 的 Java 运行时环境有更好的集成 。
我们使用 Mantis(3) 来处理收集到的数据 , 使用Cassandra来存储数据 。 分布式跟踪基础设施分为三个部分:跟踪工具库、 流式处理和存储 。 从各种微服务收集到的 trace 数据以流处理的方式进入数据存储中 。 下面的章节描述了构建这些组件的历程 。
(1)
(2)
(3)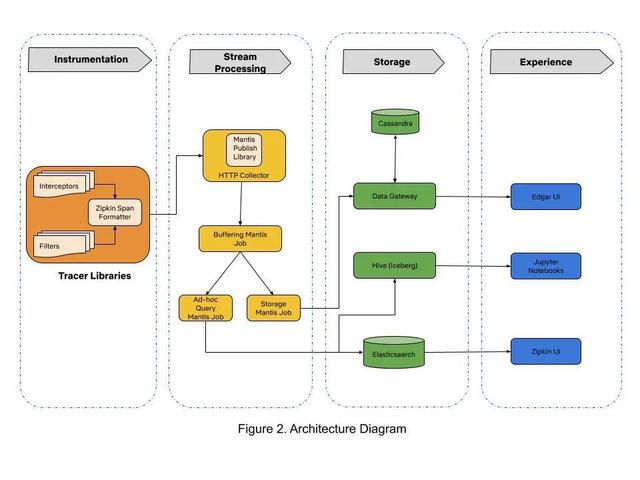 文章插图
文章插图
跟踪 Instrumentation:它将如何影响我们的服务?
这是我们工程团队在集成 tracer 库时提到的第一个问题 。 这是一个重要的问题 , 因为 tracer 库拦截了流经关键任务流服务的所有请求 。 对于 polyglot 运行时 , 安全集成和部署 tracer 库是我们的首要任务 。 我们理解工程师的运维负担 , 并专注于在运行时环境中提供高效的跟踪库集成 , 并赢得了工程师的信任 。
分布式跟踪依赖于为本地进程间调用(IPC)和客户端调用远程微服务的任何任意请求传递的上下文 。 传递请求上下文 , 可以捕获运行时微服务之间调用的因果关系 。
我们采用了 Open-Zipkin 的基于 B3 HTTP (1) 头的上下文传播机制 。 我们确保在各种集成的 Java 和 Node 运行时环境中 , 微服务之间正确传递了上下文传包头 , 这些环境既包括具有传统代码库的旧环境 , 也包括 Spring Boot 等新环境 。
在面对 Python、NodeJS 和 Ruby on Rails 等环境的跟踪库时 , 执行我们文化中的自由与责任原则 (2), 这些环境不属于集成的范围 , 我们松耦合但高内聚的工程团队 , 可以自由选择适合其运行时环境的跟踪库 , 并有责任确保正确的上下文传播和网络调用拦截器的集成 。
(1) /b3-propagation
(2)
我们的运行时环境集成注入了基础设施标签 , 如服务名称、自动伸缩组(ASG)和容器实例标识符 。 Edgar 使用这种基础设施标签模式来查询和加入带有日志数据的 trace 信息 , 以便对流 session 进行故障排除 。
此外 , 由于标签的一致性 , 在 Edgar 中为不同的监控和部署系统提供深度链接变得很容易 。 在运行时环境集成到位后 , 我们必须设置一个合适的 trace 数据采样策略 , 以构建故障诊断功能 。
流处理:采样 , 还是不采样?
这是我们在构建基础设施时考虑的最重要的问题 , 因为数据采样策略决定了记录、传输和存储的 trace 数量 。 宽松的跟踪数据采样策略 , 会在每个服务容器中产生大量的跟踪数据 , 并且会导致流服务的性能下降 , 因为跟踪库会消耗更多的 CPU、内存和网络资源 。
- 展开|天地在线联合腾讯广告在京展开“附近推” 构建黄金5公里营销体系
- 重庆市工业互联网技术创新战略联盟:构建万物互联智能工厂 助力先进制造发展
- 框架|三种数据分析思维框架的构建方法
- 分布式锁的这三种实现90%的人都不知道
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 「开源资讯」Gradle 6.7 发布,增量构建改进
- 使用机器学习数据集构建销售预测Web应用程序
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 为什么分布式应用程序需要依赖管理?