构建 Netflix 分布式追踪(tracing)体系( 三 )
目前 , 我们在 Storage Mantis 工作中使用了一个简单的基于规则的过滤器 , 它可以保留 Edgar 中很少被查看的服务调用路径的有趣跟踪信息 。 该过滤器通过检查一个跟踪的所有缓冲跨度的警告、错误和重试标签 , 将一个跟踪限定为一个有趣的数据点 。 这种基于尾巴的采样方法在不影响用户体验的情况下 , 将跟踪数据量减少了 20% 。
我们有机会使用基于机器学习的分类技术 , 来进一步减少跟踪数据量 。
虽然已经取得了实质性的进展 , 但最近面临构建跟踪数据存储系统的另一个拐点 。 在 Edgar 上增加一些新的功能可能需要我们存储 10 倍于当前数据量的数据 。
因此 , 目前正在试验一种新的数据网关的分层存储方式 。 这个数据网关提供了一个查询接口 , 抽象了从分层数据存储中读取和写入数据的复杂性 。 此外 , 数据网关将摄入的数据路由到 Cassandra 集群 , 并将压缩后的数据文件从 Cassandra 集群传输到 S3 。 我们计划将最近几个小时的数据保留在 Cassandra 集群中 , 其余数据保留在 S3 桶中 , 以便长期保留跟踪信息 。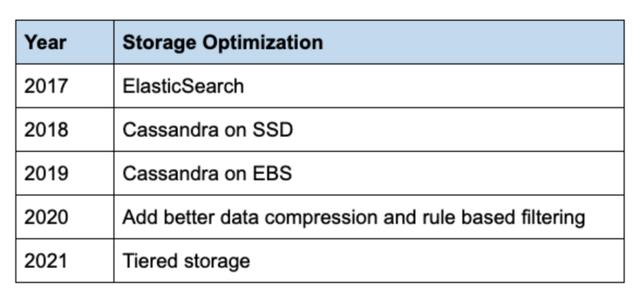 文章插图
文章插图
表格1:存储优化的时间表
【构建 Netflix 分布式追踪(tracing)体系】其他收益
除了支持 Edgar 外 , 跟踪数据还用于以下使用场景 。
应用程序健康监测
Trace 数据是 Telltale 用于监控 Netflix 宏观层面应用健康状况的关键信号 。 Telltale 使用 trace 中的关联信息来推断微服务拓扑 , 并将 trace 与 Atlas 的时间序列数据相关联 。 这种方法可以描绘出更丰富的应用健康状况的可观察性画像 。
容错工程
我们的混沌工程团队使用 trace 来验证故障是否被正确注入 , 同时工程师通过故障注入测试(FIT)平台对其微服务进行压力测试 。
地域容灾
需求工程团队利用跟踪数据来提高地域迁移期间伸缩的正确性 。 追踪提供了与微服务交互的设备类型的可见性 , 这样 , 当 AWS 区域迁移时 , 可以更好地解释这些服务需求的变化 。
评估运行 A/B 测试的基础设施成本
数据科学和产品团队通过分析相关 A/B 测试名称的 trace 信息 , 评估微服务上运行 A/B 测试的效果 。
下一步是什么?
随着 Netflix 的发展 , 系统的范围和复杂性不断增加 。 我们将专注于以下几个方面来扩展 Edgar 。
- 为收集所有运行时环境的 trace 提供良好的开发者体验 。 如果有简单的方法来尝试分布式跟踪 , 将吸引更多工程师用跟踪系统来检测他们的服务 , 并通过标记相关的元数据为每个请求提供额外的上下文 。
- 增强查询跟踪数据的分析能力 , 使公司的一些高阶用户能够针对特定的用例构建自己的仪表盘和系统 。
- 构建通用的能力 , 将来自指标、日志和跟踪系统的数据关联起来 , 为故障排除提供额外的上下文信息 。
英文原文:
本文由高可用架构翻译 , 技术原创及架构实践文章 , 欢迎通过公众号菜单「联系我们」进行投稿 。
高可用架构
改变互联网的构建方式
- 展开|天地在线联合腾讯广告在京展开“附近推” 构建黄金5公里营销体系
- 重庆市工业互联网技术创新战略联盟:构建万物互联智能工厂 助力先进制造发展
- 框架|三种数据分析思维框架的构建方法
- 分布式锁的这三种实现90%的人都不知道
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 「开源资讯」Gradle 6.7 发布,增量构建改进
- 使用机器学习数据集构建销售预测Web应用程序
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 为什么分布式应用程序需要依赖管理?