Java即时编译器原理解析及实践( 四 )
字节码构造HIR
字节码Local Valueoperand stackHIR5: iload_1[i1,i2][i1]6: iload_2[i1,i2][i1,i2]................................................i3: i1 * i27: imul8: istore_3[i1,i2 , i3][i3]可以看出 , 当执行iload_1时 , 操作数栈压入变量i1 , 执行iload_2时 , 操作数栈压入变量i2 , 执行相乘指令imul时弹出栈顶两个值 , 构造出HIR i3 : i1 * i2 , 生成的i3入栈 。
C1编译器优化大部分都是在HIR之上完成的 。 当优化完成之后它会将HIR转化为LIR , LIR和HIR类似 , 也是一种编译器内部用到的IR , HIR通过优化消除一些中间节点就可以生成LIR , 形式上更加简化 。
Sea-of-Nodes IR
C2编译器中的Ideal Graph采用的是一种名为Sea-of-Nodes中间表达形式 , 同样也是SSA形式的 。 它最大特点是去除了变量的概念 , 直接采用值来进行运算 。 为了方便理解 , 可以利用IR可视化工具Ideal Graph Visualizer(IGV) , 来展示具体的IR图 。 比如下面这段代码:
example
public static int foo(int count) {int sum = 0;for (int i = 0; i < count; i++) {sum += i;}return sum;}对应的IR图如下所示: 文章插图
文章插图
图中若干个顺序执行的节点将被包含在同一个基本块之中 , 如图中的B0、B1等 。 B0基本块中0号Start节点是方法入口 , B3中21号Return节点是方法出口 。 红色加粗线条为控制流 , 蓝色线条为数据流 , 而其他颜色的线条则是特殊的控制流或数据流 。 被控制流边所连接的是固定节点 , 其他的则是浮动节点(浮动节点指只要能满足数据依赖关系 , 可以放在不同位置的节点 , 浮动节点变动的这个过程称为Schedule) 。
这种图具有轻量级的边结构 。 图中的边仅由指向另一个节点的指针表示 。 节点是Node子类的实例 , 带有指定输入边的指针数组 。 这种表示的优点是改变节点的输入边很快 , 如果想要改变输入边 , 只要将指针指向Node , 然后存入Node的指针数组就可以了 。
依赖于这种图结构 , 通过收集程序运行的信息 , JVM可以通过Schedule那些浮动节点 , 从而获得最好的编译效果 。
Phi And Region Nodes
Ideal Graph是SSA IR 。 由于没有变量的概念 , 这会带来一个问题 , 就是不同执行路径可能会对同一变量设置不同的值 。 例如下面这段代码if语句的两个分支中 , 分别返回5和6 。 此时 , 根据不同的执行路径 , 所读取到的值很有可能不同 。
example
int test(int x) {int a = 0;if(x == 1) {a = 5;} else {a = 6;}return a;}为了解决这个问题 , 就引入一个Phi Nodes的概念 , 能够根据不同的执行路径选择不同的值 。 于是 , 上面这段代码可以表示为下面这张图: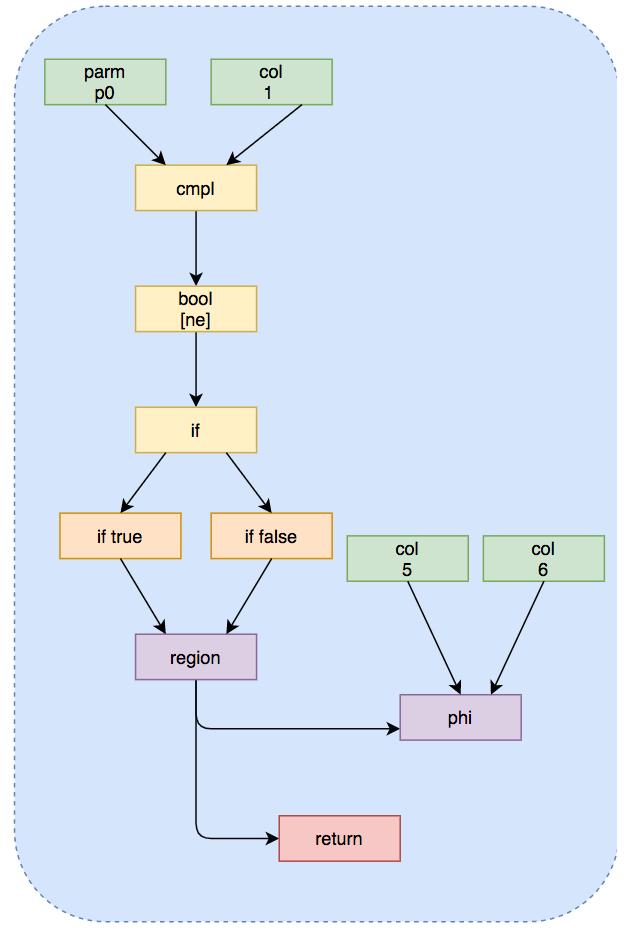 文章插图
文章插图
Phi Nodes中保存不同路径上包含的所有值 , Region Nodes根据不同路径的判断条件 , 从Phi Nodes取得当前执行路径中变量应该赋予的值 , 带有Phi节点的SSA形式的伪代码如下:
【Java即时编译器原理解析及实践】Phi Nodes
int test(int x) {a_1 = 0;if(x == 1){a_2 = 5;}else {a_3 = 6;}a_4 = Phi(a_2,a_3);return a_4;}Global Value Numbering
Global Value Numbering(GVN) 是一种因为Sea-of-Nodes变得非常容易的优化技术。
GVN是指为每一个计算得到的值分配一个独一无二的编号 , 然后遍历指令寻找优化的机会 , 它可以发现并消除等价计算的优化技术 。 如果一段程序中出现了多次操作数相同的乘法 , 那么即时编译器可以将这些乘法合并为一个 , 从而降低输出机器码的大小 。 如果这些乘法出现在同一执行路径上 , 那么GVN还将省下冗余的乘法操作 。 在Sea-of-Nodes中 , 由于只存在值的概念 , 因此GVN算法将非常简单:即时编译器只需判断该浮动节点是否与已存在的浮动节点的编号相同 , 所输入的IR节点是否一致 , 便可以将这两个浮动节点归并成一个 。 比如下面这段代码:
GVN
a = 1;b = 2;c = a + b;d = a + b;e = d;GVN会利用Hash算法编号 , 计算a = 1时 , 得到编号1 , 计算b = 2时得到编号2 , 计算c = a + b时得到编号3 , 这些编号都会放入Hash表中保存 , 在计算d = a + b时 , 会发现a + b已经存在Hash表中 , 就不会再进行计算 , 直接从Hash表中取出计算过的值 。 最后的e = d也可以由Hash表中查到而进行复用 。
可以将GVN理解为在IR图上的公共子表达式消除(Common Subexpression Elimination , CSE) 。 两者区别在于 , GVN直接比较值的相同与否 , 而CSE是借助词法分析器来判断两个表达式相同与否 。
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 三年Java开发,刚从美团、京东、阿里面试归来,分享个人面经
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- java面试题整理
- Kotlin集合vs Kotlin序列与Java流
- Java安全之Javassist动态编程
- 推荐Java工程师必看,12个Hadoop领域的上手项目
- 震惊!京东T4大佬面试整整三个月,才写了两份java面试笔记