Java即时编译器原理解析及实践( 二 )
无论是否进行全局优化 , Ideal Graph都会被转化为一种更接近机器层面的MachNode Graph , 最后编译的机器码就是从MachNode Graph中得的 , 生成机器码前还会有一些包括寄存器分配、窥孔优化等操作 。 关于Ideal Graph和各种全局的优化手段会在后面的章节详细介绍 。 Server Compiler编译优化的过程如下图所示: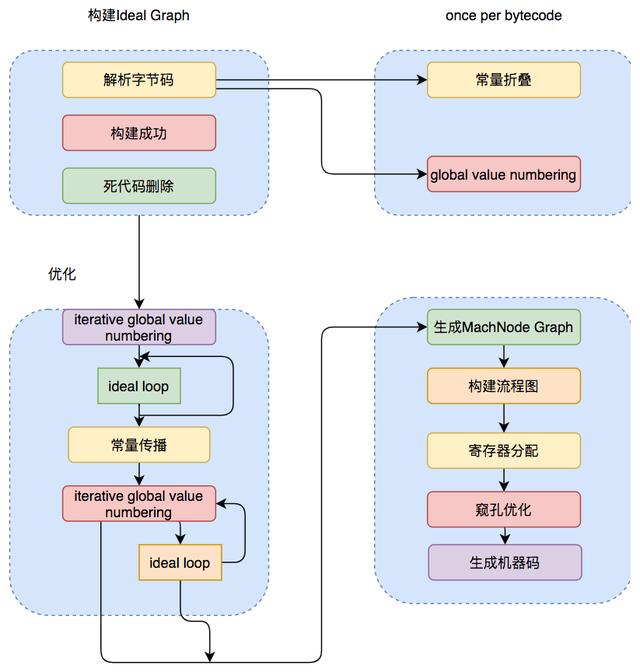 文章插图
文章插图
Graal Compiler
从JDK 9开始 , Hotspot VM中集成了一种新的Server Compiler , Graal编译器 。 相比C2编译器 , Graal有这样几种关键特性:
- 前文有提到 , JVM会在解释执行的时候收集程序运行的各种信息 , 然后编译器会根据这些信息进行一些基于预测的激进优化 , 比如分支预测 , 根据程序不同分支的运行概率 , 选择性地编译一些概率较大的分支 。 Graal比C2更加青睐这种优化 , 所以Graal的峰值性能通常要比C2更好 。
- 使用Java编写 , 对于Java语言 , 尤其是新特性 , 比如Lambda、Stream等更加友好 。
- 更深层次的优化 , 比如虚函数的内联、部分逃逸分析等 。
2. 分层编译
在Java 7以前 , 需要研发人员根据服务的性质去选择编译器 。 对于需要快速启动的 , 或者一些不会长期运行的服务 , 可以采用编译效率较高的C1 , 对应参数-client 。 长期运行的服务 , 或者对峰值性能有要求的后台服务 , 可以采用峰值性能更好的C2 , 对应参数-server 。 Java 7开始引入了分层编译的概念 , 它结合了C1和C2的优势 , 追求启动速度和峰值性能的一个平衡 。 分层编译将JVM的执行状态分为了五个层次 。 五个层级分别是:
- 解释执行 。
- 执行不带profiling的C1代码 。
- 执行仅带方法调用次数以及循环回边执行次数profiling的C1代码 。
- 执行带所有profiling的C1代码 。
- 执行C2代码 。
通常情况下 , C2代码的执行效率要比C1代码的高出30%以上 。 C1层执行的代码 , 按执行效率排序从高至低则是1层>2层>3层 。 这5个层次中 , 1层和4层都是终止状态 , 当一个方法到达终止状态后 , 只要编译后的代码并没有失效 , 那么JVM就不会再次发出该方法的编译请求的 。 服务实际运行时 , JVM会根据服务运行情况 , 从解释执行开始 , 选择不同的编译路径 , 直到到达终止状态 。 下图中就列举了几种常见的编译路径:
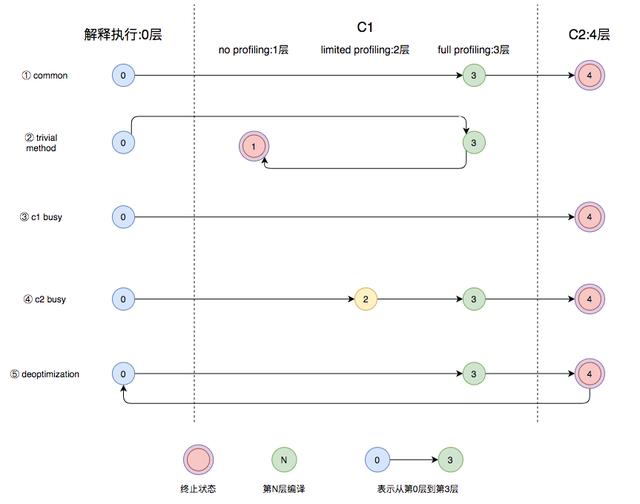 文章插图
文章插图- 图中第①条路径 , 代表编译的一般情况 , 热点方法从解释执行到被3层的C1编译 , 最后被4层的C2编译 。
- 如果方法比较小(比如Java服务中常见的getter/setter方法) , 3层的profiling没有收集到有价值的数据 , JVM就会断定该方法对于C1代码和C2代码的执行效率相同 , 就会执行图中第②条路径 。 在这种情况下 , JVM会在3层编译之后 , 放弃进入C2编译 , 直接选择用1层的C1编译运行 。
- 在C1忙碌的情况下 , 执行图中第③条路径 , 在解释执行过程中对程序进行profiling, 根据信息直接由第4层的C2编译 。
- 前文提到C1中的执行效率是1层>2层>3层 , 第3层一般要比第2层慢35%以上 , 所以在C2忙碌的情况下 , 执行图中第④条路径 。 这时方法会被2层的C1编译 , 然后再被3层的C1编译 , 以减少方法在3层的执行时间 。
- 如果编译器做了一些比较激进的优化 , 比如分支预测 , 在实际运行时发现预测出错 , 这时就会进行反优化 , 重新进入解释执行 , 图中第⑤条执行路径代表的就是反优化 。
3. 即时编译的触发
Java虚拟机根据方法的调用次数以及循环回边的执行次数来触发即时编译 。 循环回边是一个控制流图中的概念 , 程序中可以简单理解为往回跳转的指令 , 比如下面这段代码:
循环回边
public void nlp(Object obj) {int sum = 0;for (int i = 0; i < 200; i++) {sum += i;}}上面这段代码经过编译生成下面的字节码 。 其中 , 偏移量为18的字节码将往回跳至偏移量为4的字节码中 。 在解释执行时 , 每当运行一次该指令 , Java虚拟机便会将该方法的循环回边计数器加1 。
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 三年Java开发,刚从美团、京东、阿里面试归来,分享个人面经
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- java面试题整理
- Kotlin集合vs Kotlin序列与Java流
- Java安全之Javassist动态编程
- 推荐Java工程师必看,12个Hadoop领域的上手项目
- 震惊!京东T4大佬面试整整三个月,才写了两份java面试笔记