使用selenium库做基本的反反爬虫,这都不会还说会爬虫?
现在很多网站为防止爬虫 , 加载的数据都使用js的方式加载 , 如果使用python的request库爬取的话就爬不到数据 , selenium库能模拟打开浏览器 , 浏览器打开网页并加载js数据后 , 再获取数据 , 这样就达到反反爬虫 , selenium的功能不止这一个 , 还能做很多 , 比如定位到某一个标签(可根据classname、id、html标签等) , 点击 , 上滑 , js语句操作等等操作 。
首先下载chrome驱动:
如果chrome的版本和驱动的版本差别大的话 , 打开网址和获取html标签不会报错, 但操作js语句时会报错
版本问题:打开chrome浏览器的安装位置 , 在哪里的第一个文件夹的名字就是她的版本 , 如我的是84.0.4147.105,然后在上面的网址中安装的是84.0.4147.30这个版本的Windows 32位驱动(即使我电脑是64位)
然后将下载下来的驱动解压后放到python解释器的安装目录(和python.exe同一个目录) , 然后将python的安装目录路径添加到系统变量的Path变量中 , 这样python才能找到这个驱动
然后安装 selenium 库:pip install selenium
我下面使用的链接是B站的排行版页面 , 随时可能改变链接地址
# 最基本的打开和关闭操作from selenium import webdriverbrowser = webdriver.Chrome()# 打开浏览器browser.get('')# 打开一个网址print(browser.page_source)# 输出获取的htmlbrowser.quit()# 关闭浏览器的页面 , 并退出进程# 进一步操作页面from selenium import webdriverimport timebrowser = webdriver.Chrome()# 打开浏览器browser.get('')# 打开一个网址browser.execute_script('window.scrollTo(300,1000)')# 向右移动300像素 , 向下滑动1000像素time.sleep(2)browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')# 到页面最底部time.sleep(2)element = browser.find_element_by_link_text('【师生对线】这宿舍住得就离谱!')# 查找某个标签browser.execute_script("arguments[0].scrollIntoView();", element)# 定位到element的标签time.sleep(2)print(browser.page_source)# 输出获取的htmlbrowser.quit()# 关闭浏览器的页面 , 并退出进程里面的 browser.find_element_by_xxx(xxx) 函数可以获取查找到某个位置 , 可以通过很多种方式 , 如id , class等 , 我这里使用了一个链接文本来查找 。
该selenium库也提供了查找到某个html标签的函数 , 但我认为 , 一个页面中相同的html标签会出现不止一次 , 查找效果就不好 , 本人建议使用正则库 re 库来查找某个具体文本
# 使用re库提取html内容import refrom selenium import webdriverbrowser = webdriver.Chrome()# 打开浏览器browser.get('')# 打开一个网址number = re.findall(r'(.*?)',browser.page_source, re.S)# 排名编号title = re.findall(r'target="_blank" class="title">(.*?)',browser.page_source, re.S)# 作品标题view = re.findall(r'''(.*?)''', browser.page_source, re.S)# 观看人数danmu = view = re.findall(r'''(.*?)''', browser.page_source, re.S)# 弹幕数量user = re.findall(r'''(.*?)''', browser.page_source, re.S)# 用户名称pingfen = re.findall(r'(.*?)',browser.page_source, re.S)# 综合评分for i in zip(number, title, view, danmu, user, pingfen): print(i)browser.quit()# 关闭浏览器的页面 , 并退出进程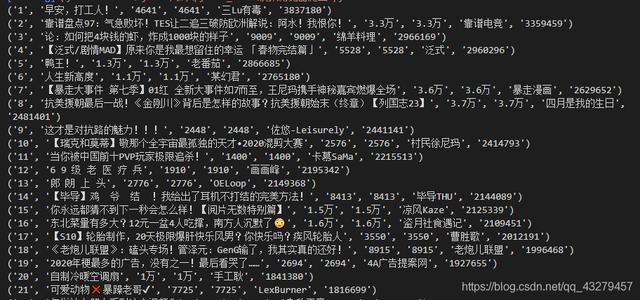 文章插图
文章插图
能爬取到数据了 , 把他录入MySQL数据库 。 如果使用我的代码录入 , 你得先创建一个 bilibili 的数据库 , 然后创建一个 20201025day 的表 , 表的结构如下: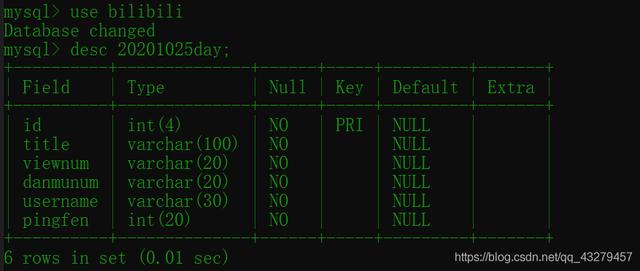 文章插图
文章插图
from selenium import webdriverimport reimport pymysqlclass Write_sql():def __init__(self, database):self.database = databaseprint('设置数据库完成 , 你已选择', self.database, '数据库')def writeValue(self, insert_sql):db = pymysql.connect('127.0.0.1', 'root', 'xxxx', self.database)cursor1 = db.cursor()# 获取操作的游标cursor1.execute(insert_sql)# 执行sql语句db.commit()# 提交到数据库browser = webdriver.Chrome()browser.get('')number = re.findall(r'(.*?)',browser.page_source, re.S)# 排名编号title = re.findall(r'target="_blank" class="title">(.*?)',browser.page_source, re.S)# 作品标题view = re.findall(r'''(.*?)''', browser.page_source, re.S)# 观看人数danmu = view = re.findall(r'''(.*?)''', browser.page_source, re.S)# 弹幕数量user = re.findall(r'''(.*?)''', browser.page_source, re.S)# 用户名称pingfen = re.findall(r'(.*?)',browser.page_source, re.S)# 综合评分write_sql = Write_sql('bilibili')# 实例化写入数据库对象for i in zip(number, title, view, danmu, user, pingfen):insertsql = 'insert into 20201025day values' + str(i)# 构造插入语句 , 由于i是元组类型 , 要转为字符串类型write_sql.writeValue(insertsql)# 调用对象的插入方法browser.quit()
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验
- 屏幕|一台realmeq2的两天使用体验