Python爬虫之Requests 库的介绍和操作实例
一、什么是爬虫?网络爬虫(又被称为网页蜘蛛 , 网络机器人 , 在FOAF社区中间 , 更经常的称为网页追逐者) , 是一种按照一定的规则 , 自动地抓取万维网信息的程序或者脚本 。 另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫 。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据 , 也就是自动抓取数据 。
你可以爬去妹子的图片 , 爬取自己想看看的视频 。。 等等你想要爬取的数据 , 只要你能通过浏览器访问的数据都可以通过爬虫获取
二、爬虫的本质模拟浏览器打开网页 , 获取网页中我们想要的那部分数据
浏览器打开网页的过程:当你在浏览器中输入地址后 , 经过DNS服务器找到服务器主机 , 向服务器发送一个请求 , 服务器经过解析后发送给用户浏览器结果 , 包括html,js,css等文件内容 , 浏览器解析出来最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果就是由HTML代码构成的 , 我们爬虫就是为了获取这些内容 , 通过分析和过滤html代码 , 从中获取我们想要资源(文本 , 图片 , 视频…)
三、爬虫的基本流程发起请求通过HTTP库向目标站点发起请求 , 也就是发送一个Request , 请求可以包含额外的header等信息 , 等待服务器响应
获取响应内容如果服务器能正常响应 , 会得到一个Response , Response的内容便是所要获取的页面内容 , 类型可能是HTML,Json字符串 , 二进制数据(图片或者视频)等类型
解析内容得到的内容可能是HTML,可以用正则表达式 , 页面解析库进行解析 , 可能是Json,可以直接转换为Json对象解析 , 可能是二进制数据 , 可以做保存或者进一步的处理
保存数据保存形式多样 , 可以存为文本 , 也可以保存到数据库 , 或者保存特定格式的文件
四、什么是RequestsRequests是用python语言基于urllib编写的 , 采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用 , 你会发现 , 其实urllib还是非常不方便的 , 而Requests它会比urllib更加方便 , 可以节约我们大量的工作 。 (用了requests之后 , 你基本都不愿意用urllib了)一句话 , requests是python实现的最简单易用的HTTP库 , 建议爬虫使用requests库 。
默认安装好python之后 , 是没有安装requests模块的 , 需要单独通过pip安装
五、Requests 库的基础知识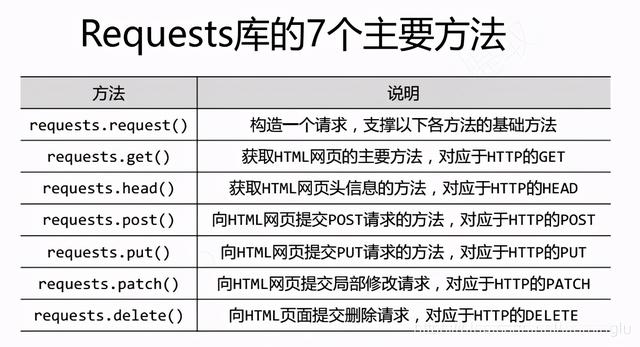 文章插图
文章插图
我们通过调用Request库中的方法 , 得到返回的对象 。 其中包括两个对象 , request对象和response对象 。
【Python爬虫之Requests 库的介绍和操作实例】request对象就是我们要请求的url , response对象是返回的内容 , 如图: 文章插图
文章插图
六、Requests的安装1.强烈建议大家使用pip进行安装:pip insrall requests
2.Pycharm安装:file-》default settings-》project interpreter-》搜索requests-》install package-》ok
七、Requests库实的操作例1、京东商品的爬取–普通爬取框架
import requestsurl = ""try:r = requests.get(url)r.raise_for_status()r.encoding = r.apparent_encodingprint(r.text[:1000])except:print("爬取失败!")2、亚马逊商品的爬取–通过修改headers字段 , 模拟浏览器向网站发起请求
import requestsurl=""try:kv = {'user-agent':'Mozilla/5.0'}r=requests.get(url,headers=kv)r.raise_for_status()r.encoding=r.apparent_encodingprint(r.status_code)print(r.text[:1000])except:print("爬取失败")3、百度/360搜索关键词提交–修改params参数提交关键词
百度的关键词接口:360的关键词接口:
import requestsurl=""try:kv={'wd':'Python'}r=requests.get(url,params=kv)print(r.request.url)r.raise_for_status()print(len(r.text))print(r.text[500:5000])except:print("爬取失败")4、网络图片的爬取和存储–结合os库和文件操作的使用
import requestsimport osurl=""root="D://pics//"path=root + url.split('/')[-1]try:if not os.path.exists(root):os.mkdir(root)if not os.path.exists(path):r = requests.get(url)with open(path, 'wb') as f:f.write(r.content)f.close()print("文件保存成功")else:print("文件已存在")except:print("爬取失败")最后:异常处理
在你不确定会发生什么错误时 , 尽量使用try…except来捕获异常所有的requests exception:
import requestsfrom requests.exceptions import ReadTimeout,HTTPError,RequestExceptiontry:response = requests.get('',timeout=0.5)print(response.status_code)except ReadTimeout:print('timeout')except HTTPError:print('httperror')except RequestException:print('reqerror')
- 纠结|硬杠红米Note9Pro?iQOO Z1跌至1575,对比之后纠结了!
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 蛋壳公寓|官媒发声:绝不能让“割韭菜者”一跑了之!
- 看过明年的iPhone之后,现在下手的都哭了
- 直播销售员|石家庄桥西区插上“互联网+”智慧发展之翼
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 报名啦!宿迁开展第五届“十大科技之星”评选