应用在大规模推荐系统,Facebook提出组合embedding方法 | KDD 2020( 三 )
优化器adagrad和amsgrad , batch128 , 无正则 , embedding size 16 , 损失交叉熵 。 实施了4个哈希冲突 , 使模型大小减少了约4倍 。 每条曲线显示了5次试验中验证损失的平均值和标准差 。
3.3.基本效果: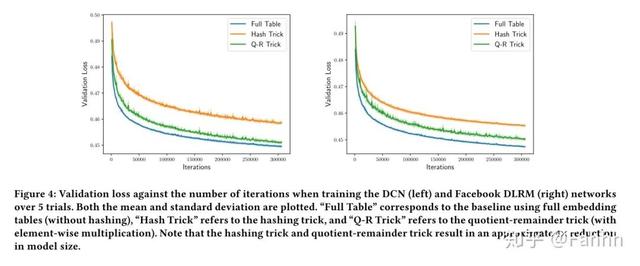 文章插图
文章插图
可以看到Q-R方法的loss比hash方法小很多 , 比FULL table的大一些 , hash方法和Q-R方法的模型比FULL TABLE小了4倍 。
3.4.不同组合embedding的效果:
为了更全面的比较 , 在每个特征中强制加入了很多hash冲突 , 得到的结果是5次试验的平均值 。 总体来说乘法运算的效果最好 。
3.5.不同组合embedding的效果2:
因为不同特征 , 取值数量差别大 , 所以hash方法的阈值(hash的最大维度)对于效果也有影响 , 这里分不同阈值测试了效果: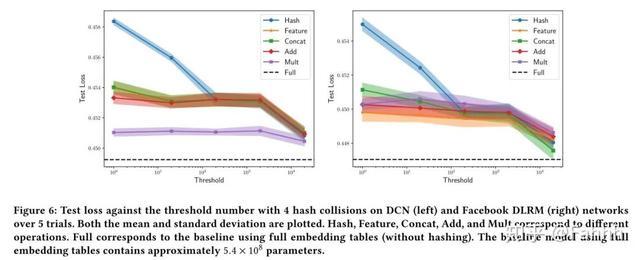 文章插图
文章插图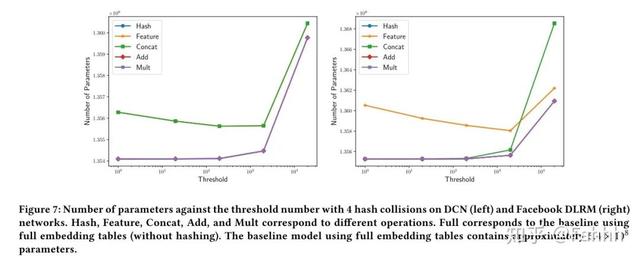 文章插图
文章插图
3.6.Path-Based Compositional Embeddings效果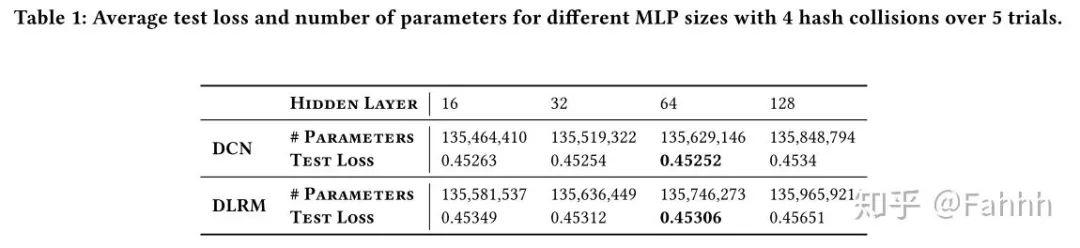 文章插图
文章插图
(效果好像一般哈 。 看来学习的方法不是万能的 。 )作者最后也提到了这个path based的方法 , 这种方法是计算密集型模型 , 模型复杂度低 , 但效果不太能取代操作base的方法 , 还需要深入的研究 。
读后感:
方法还是很惊艳的 , 但是没有讨论时间复杂度 , 只讨论了模型的大小 , 我感觉时间复杂度还是要高了一些 。 但是整个思路还是非常好的 , 特别是最后的path based的方法 , 虽然效果不好 , 但是总感觉大有可为 。
来源:
论文地址: 文章插图
文章插图
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 职工组一等|全国人工智能应用技术技能大赛落幕 青岛四名选手获一等奖
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 智能手机市|外部大环境回暖,供应链产能恢复,绿厂猛“加单”!
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口
- Play|Google Play公布2020年度最佳应用和游戏排行榜
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序