应用在大规模推荐系统,Facebook提出组合embedding方法 | KDD 2020( 二 )
定义1:
给定集合S的k个分区 P1,P2….PK , 这些分区是互补的 。 即对于集合S中任意两个元素a和b , 总是存在一个分区 , 在这个分区关系下的a和b的等价类集合不同 。 关于等价类可以参考知乎:离散数学中的等价类是什么意思?- laogan的回答 - 知乎
举个例子: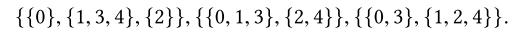 文章插图
文章插图
(我理解就是对于每两个不同元素比如1和4 , 总有一种分区关系 , 让1和4存在两个子集中 , 像1和4在第二种分区关系下 , 它们就在两个分区子集里)
给定分区的每个等价类都指定一个映射到embedding向量的“bucket” 。 因此 , 每个分区P对应于一个embedding table 。 在互补分区下 , 在每个分区产生的每个嵌入通过某种操作组合之后 , 每个索引被映射到一个不同的embedding向量 。 (上面那个例子就是三个embedding table , 第一个embedding table 有三行 , 后两个embedding table是两行)
2.3.互补分区的例子
【应用在大规模推荐系统,Facebook提出组合embedding方法 | KDD 2020】a.朴素互补分区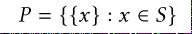 文章插图
文章插图
b.商余互补分区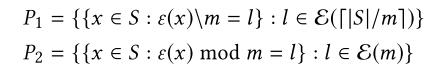 文章插图
文章插图
c.一般商余互补分区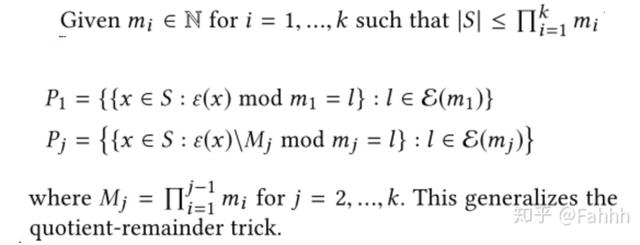 文章插图
文章插图
d.中国的余数分区
考虑一个大于或等于S的两两互质因式分解 文章插图
文章插图
(我理解就是任意两个不同分区size的最大公约数等于 1 )
这种分区可以根据需要自由定义 , 可以根据年份、品牌、类型等定义不同的分区 。 假设这些属性的唯一规范生成一辆独特的汽车 , 这些分区确实是互补的
2.4.COMPOSITIONAL EMBEDDINGS USING COMPLEMENTARY PARTITIONS
为每个分区创建一个embedding table: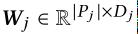 文章插图
文章插图
分区中每个等价类中的元素映射到同一个embedding 向量上 。
对于某个特征取值x , 它的embedding为: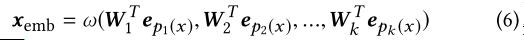 文章插图
文章插图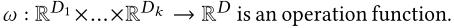 文章插图
文章插图
可以有很多整合方法:
- 拼接
- 相加
- 追元素相乘(hadamard积)
 文章插图
文章插图这很简单了 , (只要创建互补分区的时候 , 别让任意两个不同的特征取值在所有分区中的索引都相同就好了)
空间复杂度:
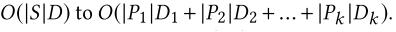 文章插图
文章插图就是:
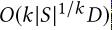 文章插图
文章插图这里有个图很形象了:
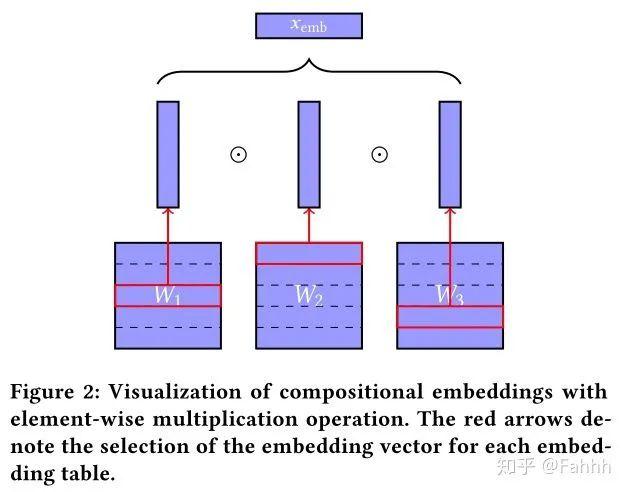 文章插图
文章插图2.5.Path-Based Compositional Embeddings
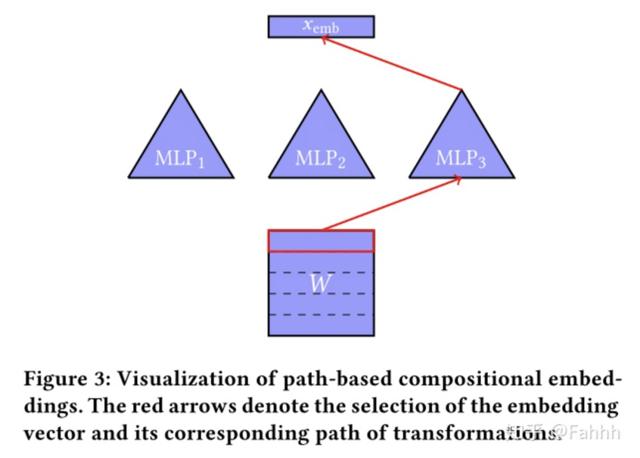 文章插图
文章插图生成embedding的另一种方法是为每个分区定义一组不同的转换(第一个embedding table除外) 。 特别是 , 可以使用一个单独的分区来定义一个初始嵌入表 , 然后通过其他分区确定的函数组合来传递初始嵌入向量 。
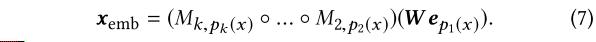 文章插图
文章插图W是embedding table,M是传递函数 。 这里的传递函数 , 也一起训练 。
这样的M可以是:
a.线性的
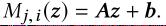 文章插图
文章插图b.MLP
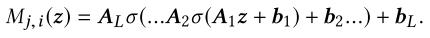 文章插图
文章插图与基于操作的组合embedding不同 , 基于路径的组合embedding需要学习函数中的非embedding参数 , 这可能会使训练复杂化 。 内存复杂性的降低还取决于如何定义这些函数以及它们添加了多少附加参数 。 较小的参数情况下可以与基于操作的组合的空间复杂度相同 。
 文章插图
文章插图结果
3.1.实验设置:
选择两个模型 , DCN和Facebook内部的推荐模型 。
3.2.数据集:
Kaggle 的 Criteo Ad Kaggle Competition , 前6天训练 , 第7天预测 。
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 职工组一等|全国人工智能应用技术技能大赛落幕 青岛四名选手获一等奖
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 智能手机市|外部大环境回暖,供应链产能恢复,绿厂猛“加单”!
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口
- Play|Google Play公布2020年度最佳应用和游戏排行榜
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序