一个复杂系统的拆分改造实践( 二 )
2.6 放松心情 , 缓解压力收拾下心情 , 开干!
3 实践3.1 db拆分实践DB拆分在整个应用拆分环节里最复杂 , 分为垂直拆分和水平拆分两种场景 , 我们都遇到了 。 垂直拆分是将库里的各个表拆分到合适的数据库中 。 比如一个库中既有消息表 , 又有人员组织结构表 , 那么将这两个表拆分到独立的数据库中更合适 。
水平拆分:以消息表为例好了 , 单表突破了千万行记录 , 查询效率较低 , 这时候就要将其分库分表 。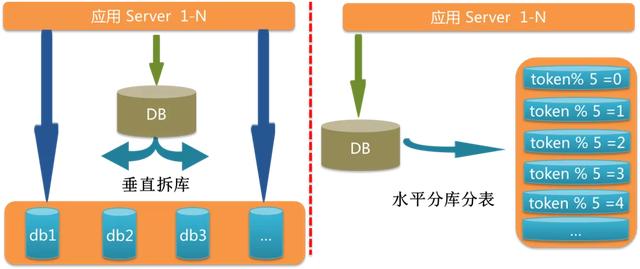 文章插图
文章插图
3.1.1 主键id接入全局id发生器DB拆分的第一件事情就是使用全局id发生器来生成各个表的主键id 。 为什么?
举个例子 , 假如我们有一张表 , 两个字段id和token , id是自增主键生成 , 要以token维度来分库分表 , 这时继续使用自增主键会出现问题 。 文章插图
文章插图
正向迁移扩容中 , 通过自增的主键 , 到了新的分库分表里一定是唯一的 , 但是 , 我们要考虑迁移失败的场景 , 如下图所示 , 新的表里假设已经插入了一条新的记录 , 主键id也是2 , 这个时候假设开始回滚 , 需要将两张表的数据合并成一张表(逆向回流) , 就会产生主间冲突!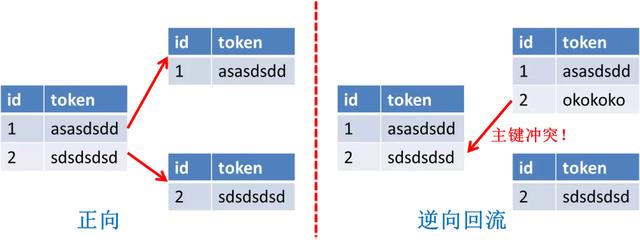 文章插图
文章插图
因此在迁移之前 , 先要用全局唯一id发生器生成的id来替代主键自增id 。 这里有几种全局唯一id生成方法可以选择 。
1)snowflake:;(非全局递增)
2) mysql新建一张表用来专门生成全局唯一id(利用auto_increment功能)(全局递增);
3)有人说只有一张表怎么保证高可用?那两张表好了(在两个不同db) , 一张表产生奇数 , 一张表产生偶数 。 或者是n张表 , 每张表的负责的步长区间不同(非全局递增)
4)……
我们使用的是阿里巴巴内部的tddl-sequence(mysql+内存) , 保证全局唯一但非递增 , 在使用上遇到一些坑:
1)对按主键id排序的sql要提前改造 。 因为id已经不保证递增 , 可能会出现乱序场景 , 这时候可以改造为按gmt_create排序;
2)报主键冲突问题 。 这里往往是代码改造不彻底或者改错造成的 , 比如忘记给某一insert sql的id添加#{} , 导致继续使用自增 , 从而造成冲突; 文章插图
文章插图
3.1.2 建新表&迁移数据&binlog同步1) 新表字符集建议是utf8mb4 , 支持表情符 。 新表建好后索引不要漏掉 , 否则可能会导致慢sql!从经验来看索引被漏掉时有发生 , 建议事先列计划的时候将这些要点记下 , 后面逐条检查;
2) 使用全量同步工具或者自己写job来进行全量迁移;全量数据迁移务必要在业务低峰期时操作 , 并根据系统情况调整并发数;
3) 增量同步 。 全量迁移完成后可使用binlog增量同步工具来追数据 , 比如阿里内部使用精卫 , 其它企业可能有自己的增量系统 , 或者使用阿里开源的cannal/otter:
增量同步起始获取的binlog位点必须在全量迁移之前 , 否则会丢数据 , 比如我中午12点整开始全量同步 , 13点整全量迁移完毕 , 那么增量同步的binlog的位点一定要选在12点之前 。
位点在前会不会导致重复记录?不会!线上的MySQL binlog是row 模式 , 如一个delete语句删除了100条记录 , binlog记录的不是一条delete的逻辑sql , 而是会有100条binlog记录 。 insert语句插入一条记录 , 如果主键冲突 , 插入不进去 。
3.1.3 联表查询sql改造现在主键已经接入全局唯一id , 新的库表、索引已经建立 , 且数据也在实时追平 , 现在可以开始切库了吗?no!
考虑以下非常简单的联表查询sql , 如果将B表拆分到另一个库里的话 , 这个sql怎么办?毕竟跨库联表查询是不支持的! 文章插图
文章插图
因此 , 在切库之前 , 需要将系统中上百个联表查询的sql改造完毕 。
如何改造呢?
1) 业务避免
业务上松耦合后技术才能松耦合 , 继而避免联表sql 。 但短期内不现实 , 需要时间沉淀;
2) 全局表
每个应用的库里都冗余一份表 , 缺点:等于没有拆分 , 而且很多场景不现实 , 表结构变更麻烦;
3) 冗余字段
就像订单表一样 , 冗余商品id字段 , 但是我们需要冗余的字段太多 , 而且要考虑字段变更后数据更新问题;
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 车企|华为不造车!但任正非加了一个有效期,3年
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get