一张图搞懂 Redis 缓存雪崩、缓存穿透、缓存击穿
 文章插图
文章插图
作者 | 雷架
文章来源 | 爱笑的架构师 (id :DancingOnYourCode) 文章插图
文章插图
缓存异常场景分类
在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景 , 为了避免异常带来巨大损失 , 我们需要了解每种异常发生的原因以及解决方案 , 帮助提升系统可靠性和高可用 。 文章插图
文章插图
缓存穿透
什么是缓存穿透?缓存穿透是指用户请求的数据在缓存中不存在即没有命中 , 同时在数据库中也不存在 , 导致用户每次请求该数据都要去数据库中查询一遍 , 然后返回空 。
如果有恶意攻击者不断请求系统中不存在的数据 , 会导致短时间大量请求落在数据库上 , 造成数据库压力过大 , 甚至击垮数据库系统 。
缓存穿透常用的解决方案(1)布隆过滤器(推荐)
布隆过滤器(Bloom Filter , 简称BF)由Burton Howard Bloom在1970年提出 , 是一种空间效率高的概率型数据结构 。
布隆过滤器专门用来检测集合中是否存在特定的元素 。
如果在平时我们要判断一个元素是否在一个集合中 , 通常会采用查找比较的方法 , 下面分析不同的数据结构查找效率:
- 采用线性表存储 , 查找时间复杂度为O(N)
- 采用平衡二叉排序树(AVL、红黑树)存储 , 查找时间复杂度为O(logN)
- 采用哈希表存储 , 考虑到哈希碰撞 , 整体时间复杂度也要O[log(n/m)]
布隆过滤器设计思想
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构 。 位数组初始化均为0 , 所有的哈希函数都可以分别把输入数据尽量均匀地散列 。
当要向布隆过滤器中插入一个元素时 , 该元素经过k个哈希函数计算产生k个哈希值 , 以哈希值作为位数组中的下标 , 将所有k个对应的比特值由0置为1 。
当要查询一个元素时 , 同样将其经过哈希函数计算产生哈希值 , 然后检查对应的k个比特值:如果有任意一个比特为0 , 表明该元素一定不在集合中;如果所有比特均为1 , 表明该集合有可能性在集合中 。 为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样 , 会出现哈希碰撞 , 导致一个不存在的元素有可能对应的比特位为1 , 这就是所谓“假阳性”(false positive) 。 相对地 , “假阴性”(false negative)在BF中是绝不会出现的 。
总结一下:布隆过滤器认为不在的 , 一定不会在集合中;布隆过滤器认为在的 , 可能在也可能不在集合中 。
举个例子:下图是一个布隆过滤器 , 共有18个比特位 , 3个哈希函数 。 集合中三个元素x , y , z通过三个哈希函数散列到不同的比特位 , 并将比特位置为1 。 当查询元素w时 , 通过三个哈希函数计算 , 发现有一个比特位的值为0 , 可以肯定认为该元素不在集合中 。
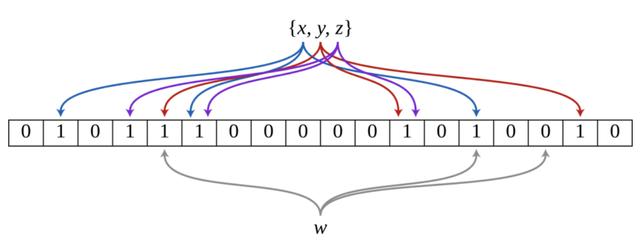 文章插图
文章插图布隆过滤器优缺点
优点:
- 节省空间:不需要存储数据本身 , 只需要存储数据对应hash比特位
- 时间复杂度低:插入和查找的时间复杂度都为O(k) , k为哈希函数的个数
- 存在假阳性:布隆过滤器判断存在 , 可能出现元素不在集合中;判断准确率取决于哈希函数的个数
- 不能删除元素:如果一个元素被删除 , 但是却不能从布隆过滤器中删除 , 这也是造成假阳性的原因了
- 爬虫系统url去重
- 垃圾邮件过滤
- 黑名单
当缓存未命中 , 查询持久层也为空 , 可以将返回的空对象写到缓存中 , 这样下次请求该key时直接从缓存中查询返回空对象 , 请求不会落到持久层数据库 。 为了避免存储过多空对象 , 通常会给空对象设置一个过期时间 。
这种方法会存在两个问题:
- 如果有大量的key穿透 , 缓存空对象会占用宝贵的内存空间 。
- 空对象的key设置了过期时间 , 在这段时间可能会存在缓存和持久层数据不一致的场景 。
- 一图看懂!数字日照、新型智慧城市这样建(上篇)|政策解读 | 新型
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 风波|杀貂风波致商户疯抢进口貂皮:一张皮涨200元,一件大衣成本增千元
- 海淀区|海淀城市大脑“时空一张图”上线
- 塑料颗粒|别不信!你每天吃的塑料量,一周后可能等于一张信用卡!
- 工艺|食用油你懂了吗?篇二谈谈加工工艺
- 读懂|一图读懂冷链食品物流防控
- 纸条|女子网购买了一双鞋,收货后发现一张纸条,看完她怒了
- 为了赚钱费尽心思,iPhone12的3个小心思,你看懂了吗?
- 现在入手苹果11值吗,它跟12相比到底好在哪?看完算搞懂了