自然语言处理的演变
NLP过去十年的直观直观解释 文章插图
文章插图
> Photo by Thyla Jane on Unsplash
注意就是您所需要的 。这就是2017年论文的名称 , 该论文将注意力作为一种独立的学习模型进行了介绍 , 这是我们如今在自然语言处理(NLP)中处于主导地位的世界的先驱 。
变压器是NLP中的新前沿技术 , 它们似乎有些抽象-但是 , 当我们回顾NLP的过去十年发展时 , 它们开始变得有意义 。
我们将介绍这些开发情况 , 并研究它们如何导致今天的变压器使用 。在您已经了解这些概念的情况下 , 本文不做任何假设-我们将在不过度掌握技术的情况下建立直观的理解 。
我们将介绍:
Natural Language Neural Nets - Recurrence - Vanishing Gradients - Long-Short Term Memory - AttentionAttention is All You Need - Self-Attention - Multi-Head Attention - Positional Encoding - Transformers
自然语言神经网络NLP在Mikolov等人[2]于2013年发表的word2vec论文中确实引起了轰动 。这引入了一种通过使用词向量来表示词之间的相似性和关系的方法 。 文章插图
文章插图
这些初始单词向量包含50–100个值的维数 。这些向量的编码机制意味着将相似的单词组合在一起(星期一 , 星期二等) , 并且在向量空间上进行的计算可能会产生真正有洞察力的关系 。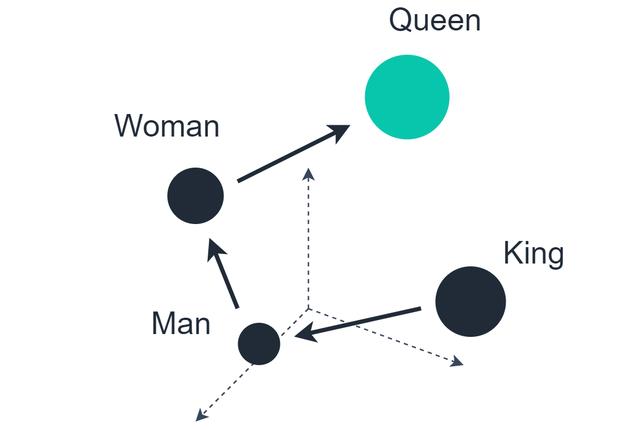 文章插图
文章插图
一个著名的例子是将向量用作King , 减去向量Man , 然后加上向量Woman , 导致最近的数据点是Queen 。
再发在NLP的繁荣时期 , 递归神经网络(RNN)迅速成为大多数语言应用程序的最爱 。由于RNN的重复出现 , 它们非常适合语言 。 文章插图
文章插图
> A recurrent neural network unit will consume the first time-step 'the', pass on its output state to the next time-step 'quick' — this recurrent process continues for a specified length of time-steps (the sequence length).
这种重复使神经网络可以考虑单词的顺序及其对前后单词的影响 , 从而可以更好地表达人类语言的细微差别 。
尽管我们直到2013年才看到它们的流行用法 , 但在80年代[2] , [3]的几篇论文中都讨论了RNN的概念和方法 。
消失的渐变RNN伴随着他们的问题 , 主要是消失的梯度问题 。这些网络的重现意味着它们本质上是非常深的网络 , 其中许多点包含传入数据和神经元权重之间的运算 。
在计算网络误差并使用它来更新网络权重时 , 我们将逐步浏览网络以权重依次更新权重 。
如果更新梯度很小 , 我们将乘以越来越小的数字-这意味着整个网络需要花费很长时间进行训练 , 或者根本无法工作 。
另一方面 , 如果我们的体重重复值太高 , 我们将遭受爆炸梯度问题的困扰 。在这里 , 网络权重将在不学习任何有意义的表示的情况下振荡 。
长期记忆解决梯度消失问题的方法是引入长短期记忆(LSTM)单元 。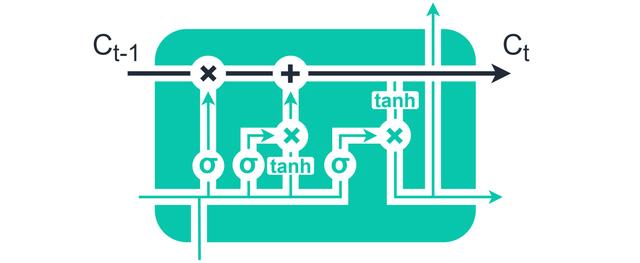 文章插图
文章插图
> LSTM units introduced a more stable passage of information — the cell state, shown in black above
LSTM在时间状态链的下游引入了额外的信息流 , 并通过"门"控制了最少的转换 。 文章插图
文章插图
> The cell state allowed information to pass from earlier states to later states with fewer transfor 文章插图
文章插图
通过允许保留序列中更早的信息并将其应用于序列中更晚的状态 , 可以学习长期依赖性 。
注意循环编码器/解码器模型非常快速地补充了其他隐藏状态和神经网络层-这些产生了注意力机制 。 文章插图
文章插图
> Encoder-decoder LSTMs with attention.
添加编码器/解码器网络后 , 模型的输出层不仅可以接收RNN单元的最终状态 , 而且还可以从输入层的每个状态接收信息 , 从而创建了一种"注意力"机制 。 文章插图
文章插图
> Attention between encoder and decoder neurons during an English-French translation task. Image sou
使用这种方法 , 我们发现编码器和解码器状态之间的相似性将导致更高的权重-产生与上面的法语翻译图像类似的结果 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面