端到端机器学习项目:评论分类( 二 )
['abc', 'bad', 'by', 'days', 'delayed', 'don', 'excellent', 'for', 'recommend', 'remit', 'services', 'team', 'the', 'three', 'transaction'][[1 0 1 0 0 0 1 0 1 1 1 1 1 0 0] [0 1 0 1 1 1 0 1 1 0 1 0 0 1 1]]现在我们已经理解了词袋的概念 , 现在让我们将这些知识应用到我们的训练和测试中
vectorizer = TfidfVectorizer()train_x_vectors = vectorizer.fit_transform(train_x)test_x_vectors = vectorizer.transform(test_x)在不平衡数据中训练模型现在 , 我们拥有了向量 , 我们可以用来拟合模型 , 我们可以这样做
支持向量机#训练支持向量机分类器clf_svm = svm.SVC(kernel='linear')clf_svm.fit(train_x_vectors, train_y)#基于SVM的随机预测i = np.random.randint(0,len(test_x))print("Review Message: ",test_x[i])print("Actual: ",test_y[i])print("Prediction: ",clf_svm.predict(test_x_vectors[i]))#支持向量机的混淆矩阵——你可以有其他分类器的混淆矩阵labels = ["NEGATIVE","NEUTRAL","POSITIVE"]pred_svm = clf_svm.predict(test_x_vectors)cm =confusion_matrix(test_y,pred_svm)df_cm = pd.DataFrame(cm, index=labels, columns=labels)sb.heatmap(df_cm, annot=True, fmt='d')plt.title("Confusion matrix from SVM [Imbalanced]")plt.savefig("./plots/confusion.png")Review Message:easy efficientfirst classActual:POSITIVEPrediction:['POSITIVE']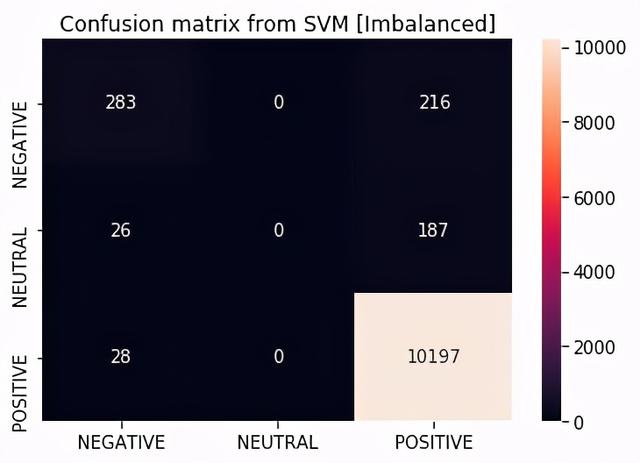 文章插图
文章插图
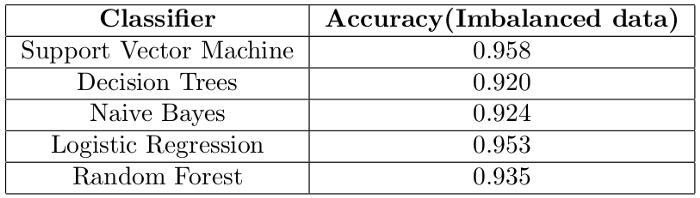
训练的其他模型包括随机森林、朴素贝叶斯、决策树和Logistic回归 。
基于不平衡数据的模型性能评估
- 准确度
 文章插图
文章插图我们得到了90%的准确率 , 是正确还是有问题?答案是 , 出了点问题 。
数据是不平衡的 , 使用准确度作为评估指标不是一个好主意 。 以下是各类别的分布情况
----------TRAIN SET ---------------Positive reviews on train set: 23961 (93.89%)Negative reviews on train set: 1055 (4.13%)Neutral reviews on train set: 503 (1.97%)----------TEST SET ---------------Positive reviews on test set: 10225 (93.48%)Negative reviews on test set: 499 (4.56%)Neutral reviews on test set: 213 (1.95%)如果分类器正确地预测了测试集中所有的正面评价 , 而没有预测到负面和中性评论 , 会发生什么?该分类器的准确率可达93.48%!!!!!!这意味着我们的模型将是93.48%的准确率 , 我们会认为模型是好的 , 但实际上 , 模型“只知道”如何预测一类(正面评价) 。 事实上 , 根据我们的结果 , 我们的支持向量机预测根本没有中性评论
【端到端机器学习项目:评论分类】为了进一步理解这个问题 , 让我们引入另一个指标:F1分数 , 并用它来评估我们的模型 。
- F1分数
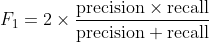 文章插图
文章插图精确性和召回率衡量模型正确区分正面案例和负面案例的程度 。
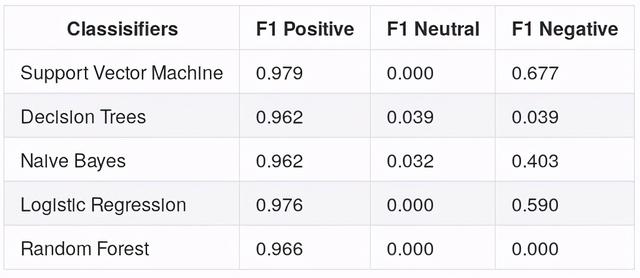
当我们根据这个指标评估我们的模型时 , 结果如下
 文章插图
文章插图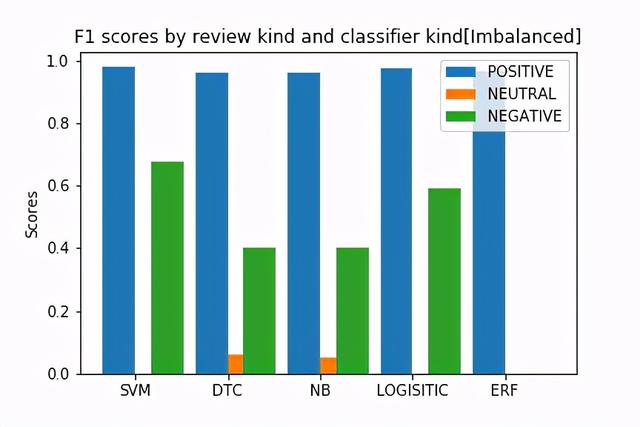 文章插图
文章插图从图中 , 我们现在知道这些模型在对正面评论进行分类时非常好 , 而在预测负面评论和中性评论方面则很差 。
使用平衡数据作为平衡数据的一种方法 , 我们决定随机删除一些正面评论 , 以便我们在训练模型时使用均匀分布的评论 。 这一次 , 我们正在训练1055个正面评论和1055个负面评论的模型 。 我们放弃中性评论 。
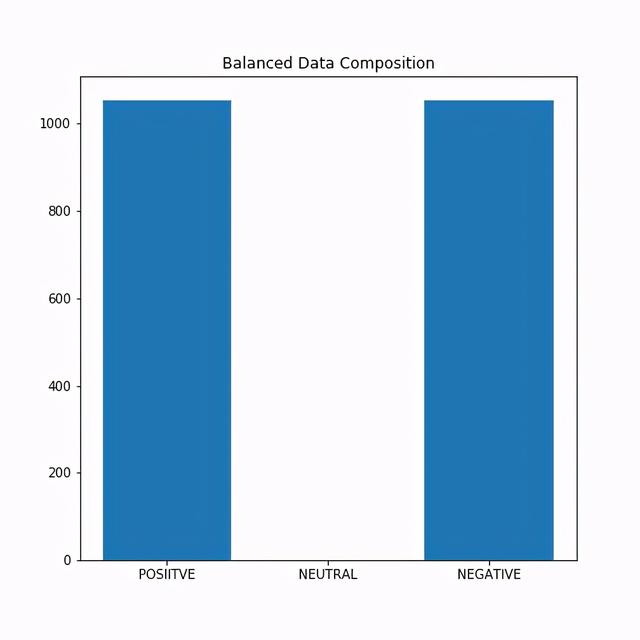 文章插图
文章插图(你也可以考虑使用过采样技术来解决数据不平衡的问题)
在训练了模型之后 , 我们得到了以下结果
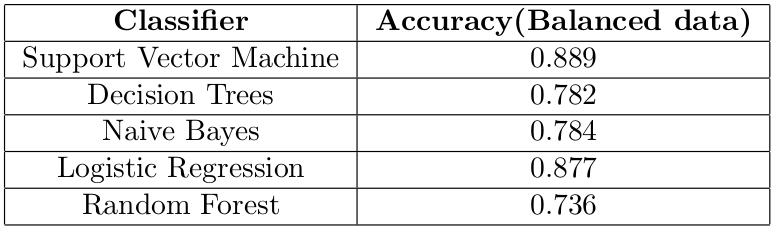 文章插图
文章插图支持向量机的最佳结果是88.9%的准确率 , 在检查F1分数(如下)后 , 我们现在可以意识到模型预测负面评价和正面评价一样好 。
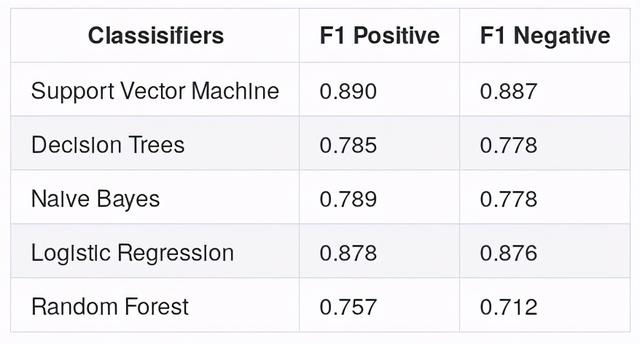 文章插图
文章插图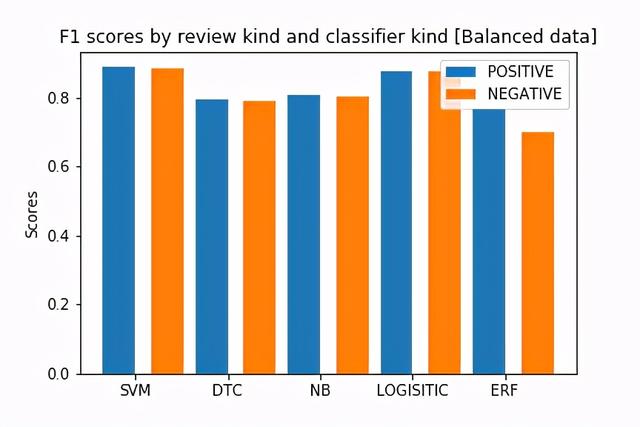 文章插图
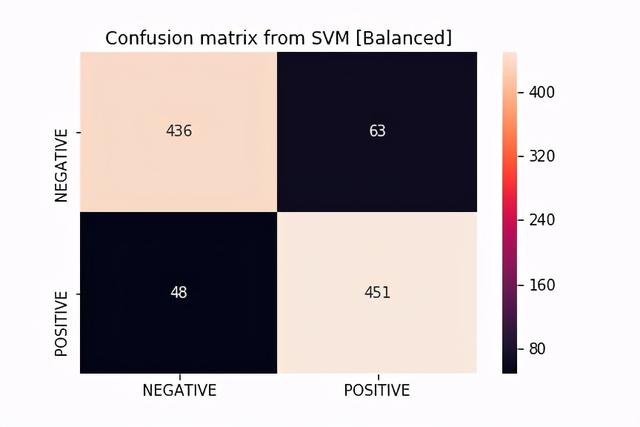
文章插图如果我们看一下显示支持向量机结果的混淆矩阵 , 我们会注意到该模型在预测两个类方面都很好
 文章插图
文章插图结论在完成这个项目后 , 我希望你能够了解到:
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 权属|从数据悖论到权属确认,数据共享进路所在