端到端机器学习项目:评论分类
 文章插图
文章插图
在本文中 , 我们将讨论一个分类问题 , 该问题涉及到将评论分为正面或负面 。 这里使用的评论是客户在ABC服务上所做的评论 。
数据收集和预处理在这个项目中使用的数据是从网上爬来的 , 数据清理在这个Notebook上完成 。
在我们抓取数据后被保存到一个.txt文件中 , 下面是一行文件的例子(代表一个数据点)
{'socialShareUrl': '/reviews/5ed0251025e5d20a88a2057d', 'businessUnitId': '5090eace00006400051ded85', 'businessUnitDisplayName': 'ABC', 'consumerId': '5ed0250fdfdf8632f9ee7ab6', 'consumerName': 'May', 'reviewId': '5ed0251025e5d20a88a2057d', 'reviewHeader': 'Wow - Great Service', 'reviewBody': 'Wow. Great Service with no issues.Money was available same day in no time.', 'stars': 5}数据点是一个字典 , 我们对reviewBody和stars感兴趣 。
我们将把评论分类如下
1 and 2 - Negative3 - Neutral4 and 5 - Positive在收集数据时 , 网站上有36456条评论 。 数据高度不平衡:94%的评论是正面的 , 4%是负面的 , 2%是中性的 。 在这个项目中 , 我们将在不平衡的数据和平衡的数据上拟合不同的Sklearn模型(我们去掉一些正面评论 , 这样我们就有相同数量的正面和负面评论 。 )
下图显示了数据的组成: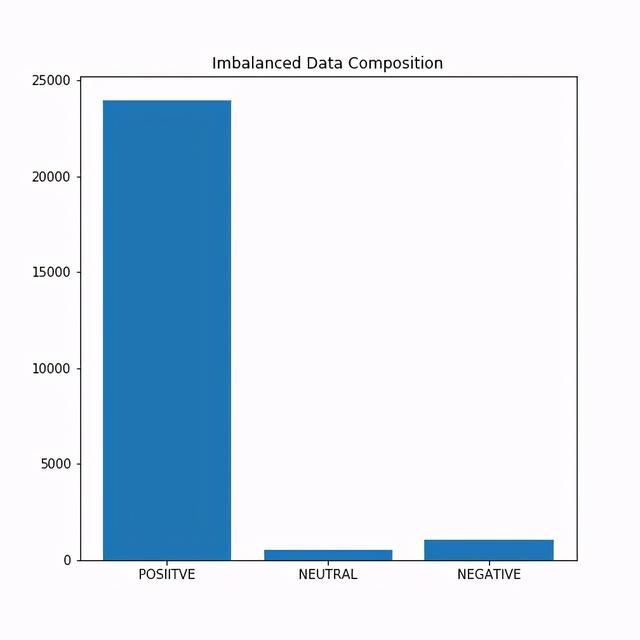 文章插图
文章插图
在上图中 , 我们可以看到数据是高度不平衡的 。
让我们从导入必要的包开始 , 并定义将用于对给定的评论进行分类的类Review
#导入包import numpy as npimport randomimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizerfrom sklearn.metrics import f1_score #f1分数 , 一种评价指标import ast #将字符串转换为字典from IPython.display import clear_outputfrom sklearn import svm #支持向量机分类器from sklearn.metrics import confusion_matrixfrom sklearn.linear_model import LogisticRegression #导入 logistic regressionfrom sklearn.tree import DecisionTreeClassifier #导入 Decision treefrom sklearn.naive_bayes import GaussianNBfrom sklearn.ensemble import RandomForestClassifierimport pandas as pdimport seaborn as sb# 将评论分为正面、负面或中性class Review:def __init__(self, text, score):self.text = textself.score = scoreself.sentiment = self.get_sentiment()def get_sentiment(self):if self.score <= 2:return "NEGATIVE"elif self.score == 3:return "NEUTRAL"else: #4或5分return "POSITIVE"在这里 , 我们将加载数据并使用Review类将评论分类为正面、反面或中性
# 大部分清理是在数据web爬取期间完成的# Notebook 链接reviews = []with open("./data/reviews.txt") as fp:for index,line in enumerate(fp):# 转换为字典review = ast.literal_eval(line)#对评论进行分类并将其附加到reviews中reviews.append(Review(review['reviewBody'], review['stars']))# 打印出reviews[0]的情绪类别和文本print(reviews[0].text)print(reviews[0].sentiment)Wow. Great Service with no issues.Money was available same day in no time.POSITIVE将数据拆分为训练集和测试集# 70%用于训练 , 30%用于测试training, test = train_test_split(reviews, test_size=0.30, random_state=42)# 定义X和Ytrain_x,train_y = [x.text for x in training],[x.sentiment for x in training]test_x,test_y = [x.text for x in test],[x.sentiment for x in test]print("Size of train set: ",len(training))print("Size of train set: ",len(test))Size of train set:25519Size of train set:10937在我们继续下一步之前 , 我们需要理解词袋的概念 。
词袋正如我们所知 , 一台计算机只理解数字 , 因此我们需要使用词袋模型将我们收到的评论信息转换成一个数字列表 。
词袋是一种文本表示形式 。 它包括两个方面:已知单词的词汇与已知单词存在程度的度量 。
词袋模型是一种用于文档分类的支持模型 , 其中每个词的出现频率作为训练分类器的特征 。
例子:考虑这两个评论
- Excellent Services by the ABC remit team.Recommend.
- Bad Services. Transaction delayed for three days.Don’t recommend.
[Excellent, Services, by, the, ABC, remit, team, recommend, bad, transaction, delayed, for, three, days, don’t]
我们现在将这个字典标记化以生成以下两个数据点 , 这些数据点现在可以用来训练分类器
 文章插图
文章插图在python中 , 标记化的实现如下
# 导入用于向量化的库from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer# sklearn上的向量化——简单的例子corpus = ["Excellent Services by the ABC remit team.Recommend.","Bad Services. Transaction delayed for three days.Don't recommend."]vectorizer = CountVectorizer()X = vectorizer.fit_transform(corpus)#print(X) #这是一个矩阵print(vectorizer.get_feature_names()) # 字典print(X.toarray())#显然是一个矩阵 , 每一行都是每个句子的标记值
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 权属|从数据悖论到权属确认,数据共享进路所在