OLAP大数据查询引擎( 三 )
· Apache Druid:这是最著名的实时OLAP引擎 。 它专注于时间序列数据 , 但可用于任何类型的数据 。 它使用自己的列式格式 , 可以大量压缩数据 , 并且具有很多内置的优化功能 , 例如倒排索引 , 文本编码 , 自动数据汇总等等 。 使用具有极低延迟的Tranquility或Kafka实时摄取数据 , 数据以针对写入进行优化的行格式保存在内存中 , 但是一旦到达 , 就可以像以前摄取的数据一样查询 。 后台任务 , 负责将数据异步移动到深度存储系统(例如HDFS) 。 当数据移至深层存储时 , 它会转换为较小的块 , 这些块按时间段划分为段 , 这些段针对低延迟查询进行了高度优化 。 它具有一个时间戳记和多个维度 , 可用于过滤和执行汇总;和指标是预先计算的汇总 。 对于批量提取 , 它将数据直接保存到细分中 。 它支持推拉式摄取 。 它与Hive , Spark甚至NiFi集成在一起 。 它可以使用Hive Metastore , 并且支持Hive SQL查询 , 然后将其转换为Druid使用的JSON查询 。Hive集成支持JDBC , 因此您可以连接任何BI工具 。 它还有自己的元数据存储 , 通常是MySQL 。 它可以吸收大量数据并很好地扩展 。 主要问题是它具有许多组件 , 并且难以管理和部署 。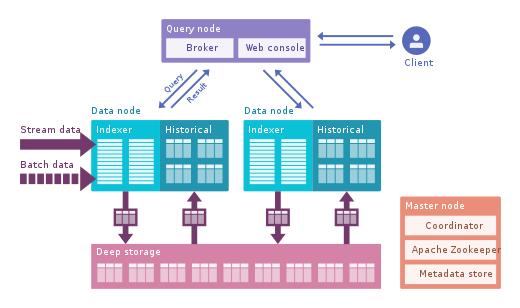 文章插图
文章插图
> Druid architecture
· Apache Pinot:它是LinkedIn开源的Druid的更新替代品 。与Druid相比 , 由于Startree索引提供了部分预计算 , 因此它提供了更低的延迟 , 因此它可以用于面向用户的应用程序(用于获取LinkedIn提要) 。它使用排序索引而不是倒排索引 , 索引速度更快 。它具有可扩展的插件体系结构 , 还具有许多集成 , 但不支持Hive 。它还统一了批处理和实时功能 , 提供快速接收 , 智能索引并将数据分段存储 。与Druid相比 , 它更容易部署且速度更快 , 但目前还不成熟 。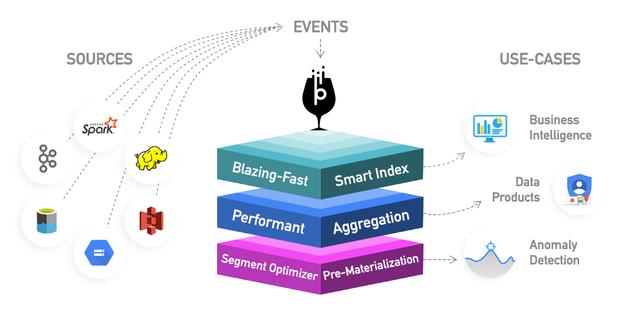 文章插图
文章插图
> Apache Pinot
· ClickHouse:用C ++编写 , 此引擎为OLAP查询(尤其是聚合)提供了令人难以置信的性能 。它看起来像一个关系数据库 , 因此您可以非常轻松地对数据建模 。它非常容易设置 , 并且具有许多集成 。 文章插图
文章插图
> ClickHouse
查看这篇文章 , 其中详细比较了3个引擎 。同样 , 从小处着手并在做出决定之前了解您的数据 , 这些新引擎功能强大 , 但难以使用 。如果您可以等待几个小时 , 则使用批处理和Hive或Tajo之类的数据库; 然后使用Kylin加快OLAP查询的速度 , 使其更具交互性 。如果这还不够 , 并且您需要更低的延迟和实时数据 , 请考虑使用OLAP引擎 。德鲁伊更适合实时分析 。麒麟更专注于OLAP案件 。Druid与Kafka的实时流媒体集成良好 。Kylin分批从Hive或Kafka获取数据; 尽管计划实时摄取 。
最后 , Greenplum是另一个更专注于AI的OLAP引擎 。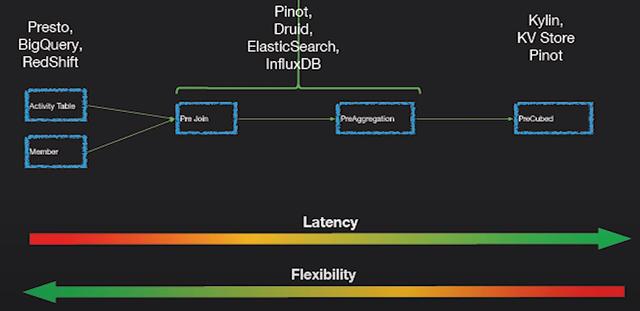 文章插图
文章插图
> Presto/Drill provide more flexibility, Kylin great latency, Druid and Pinot, the best of both worl
数据可视化最后 , 对于可视化 , 您可以使用多种商业工具 , 例如Qlik , Looker或Tableau 。
对于开放源代码 , 请检查SuperSet , 它是支持我们提到的所有工具的出色工具 , 具有出色的编辑器 , 而且速度非常快 , 它在后台使用SQLAlchemy来支持许多数据库 。
Metabase或Falcon是其他不错的选择 。
结论我们似乎有各种各样的工具可用于查询您的数据 。从诸如Presto之类的灵活查询引擎到诸如Kylin之类的高性能数据仓库 。没有单一的解决方案 , 我的建议是了解您的数据并从小处着手 。查询引擎具有灵活性 , 因此是一个不错的起点 。然后 , 对于不同的用例 , 您可能需要添加更多工具来满足您的SLA 。
要特别注意像Druid或Pinot这样的新工具 , 它们提供了一种简便的方法来以极低的延迟分析大量数据 , 从而在性能方面缩小了OLTP和OLAP之间的差距 。您可能很想考虑处理 , 预计算聚合等问题 , 但是如果您想简化管道 , 请考虑使用这些工具 。
希望您喜欢这篇文章 。随时发表评论或分享这篇文章 。跟我来以后的帖子 。
【OLAP大数据查询引擎】(本文翻译自Daan的文章《OLAP Query Engines for Big Data》 , 参考:)
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌