OLAP大数据查询引擎
介绍本文摘自我之前的文章《大数据管道食谱》 。在本文中 , 我将仅关注用于数据分析的大数据查询引擎 。
如果在这里 , 是因为您已经摄取了原始数据 , 对其进行了处理 , 并且现在可供下游系统使用 。
有多种工具可用于查询数据 , 每种工具都有其优点和缺点 。它们中的大多数都集中在OLAP上 , 但是也很少针对OLTP进行过优化 。有些使用标准格式 , 仅专注于运行查询 , 而另一些使用自己的格式/存储将处理推送到源 , 以提高性能 。有些使用星型或雪花模式针对数据仓库进行了优化 , 而另一些则更为灵活 。总而言之 , 这些是不同的注意事项:
· 数据仓库与数据湖
· Hadoop与独立
· OLAP与OLTP
· 查询引擎与OLAP引擎
我们还应该考虑具有查询功能的处理引擎 。
处理引擎我们在上一节中描述的大多数引擎都可以连接到元数据服务器 , 例如Hive并运行查询 , 创建视图等 。 这是创建精细报表层的常见用例 。
Spark SQL提供了一种将SQL查询与Spark程序无缝混合的方法 , 因此您可以将DataFrame API与SQL混合 。它具有Hive集成和通过JDBC或ODBC的标准连接; 因此您可以通过Spark将Tableau , Looker或任何BI工具连接到数据 。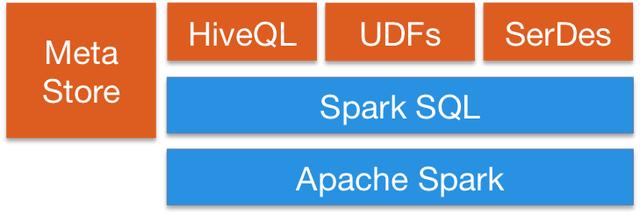 文章插图
文章插图
Apache Flink还提供SQL API 。Flink的SQL支持基于实现SQL标准的Apache Calcite 。它还通过HiveCatalog与Hive集成 。例如 , 用户可以使用HiveCatalog将其Kafka或ElasticSearch表存储在Hive Metastore中 , 并稍后在SQL查询中重新使用它们 。
Kafka还提供SQL功能 , 通常 , 大多数处理引擎都提供SQL接口 。
查询引擎这类工具专注于以统一的方式查询不同的数据源和格式 。这个想法是使用SQL查询来查询您的数据湖 , 就像它是一个关系数据库一样 , 尽管它有一些限制 。其中一些工具还可以查询NoSQL数据库等等 。这些工具为外部工具(如Tableau或Looker)提供JDBC接口 , 以安全方式连接到您的数据湖 。查询引擎是最慢的选择 , 但提供最大的灵活性 。
· Apache Pig:它是Hive最早使用的查询语言之一 。它有自己的语言 , 不同于SQL 。Pig程序的显着特性是它们的结构适合于实质性的并行化 , 从而使它们能够处理非常大的数据集 。它并不排斥基于更新的基于SQL的引擎 。
· Presto:由Facebook发布为开源 , 它是一个开源的分布式SQL查询引擎 , 用于对各种规模的数据源运行交互式分析查询 。Presto允许查询数据所在的位置 , 包括Hive , Cassandra , 关系数据库和文件系统 。它可以在几秒钟内对大型数据集执行查询 。它独立于Hadoop , 但与大多数工具集成在一起 , 尤其是Hive以运行SQL查询 。
· Apache Drill:为Hadoop , NoSQL甚至云存储提供无模式的SQL查询引擎 。它独立于Hadoop , 但与Hive等生态系统工具集成了许多功能 。单个查询可以联接来自多个数据存储的数据 , 从而执行特定于每个数据存储的优化 。即使分析人员在后台读取文件 , 它也非常擅长让分析人员将任何数据视为表 。Drill支持完全标准的SQL 。商业用户 , 分析人员和数据科学家可以使用标准的BI /分析工具(例如Tableau , Qlik和Excel)来利用Drill的JDBC和ODBC驱动程序与非关系数据存储进行交互 。此外 , 开发人员可以在其自定义应用程序中利用Drill的简单REST API来创建精美的可视化效果 。 文章插图
文章插图
> Drill model
OLTP数据库尽管Hadoop已针对OLAP进行了优化 , 但是如果您要为交互式应用程序执行OLTP查询 , 仍然有一些选择 。
HBase在设计上具有非常有限的ACID属性 , 因为它是按比例扩展的 , 并且不提供现成的ACID功能 , 但可以用于某些OLTP场景 。
Apache Phoenix建立在HBase之上 , 并提供了一种在Hadoop生态系统中执行OTLP查询的方法 。Apache Phoenix与其他Hadoop产品(例如Spark , Hive , Pig , Flume和Map Reduce)完全集成 。它还可以存储元数据 , 并支持通过DDL命令创建表和版本化的增量更改 。它非常快 , 比使用Drill或其他查询引擎要快 。
您可以使用Hadoop生态系统以外的任何大规模数据库 , 例如Cassandra , YugaByteDB , SyllaDB for OTLP 。
最后 , 在任何类型的快速数据库(例如MongoDB或MySQL)中拥有数据的子集(通常是最新数据)是很常见的 。上面提到的查询引擎可以在单个查询中在慢速和快速数据存储之间加入数据 。
分布式搜索索引这些工具提供了一种存储和搜索非结构化文本数据的方法 , 并且由于它们需要特殊的结构来存储数据 , 因此它们位于Hadoop生态系统之外 。这个想法是使用倒排索引来执行快速查找 。除了文本搜索外 , 该技术还可以用于各种用例 , 例如存储日志 , 事件等 。 有两个主要选项:
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌