CodeBERT: 面向编程语言和自然语言的预训练模型( 二 )
 文章插图
文章插图
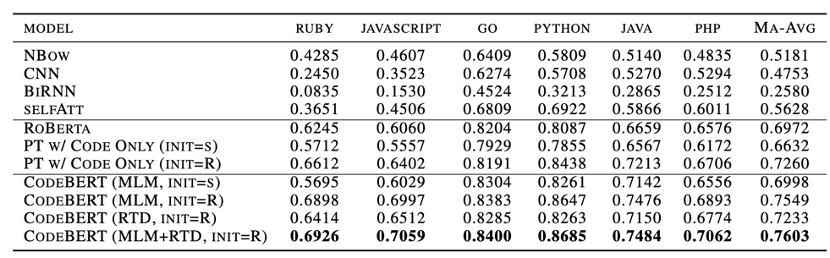
表3 自然语言代码检索结果
NL-PL Probing 这部分实验主要研究在固定模型参数的情况下 , 研究CodeBERT学习到了哪些类型的知识 。 目前学界还没有针对NL-PL Probing的工作 , 所以在这部分实验中 , 我们首先创建了数据集 。 具体地 , 我们将其构造成了多项选择题任务 , 给定输入 , 让模型选择正确的结果 。 根据输入和选项的不同 , 数据集又分为三个部分 。 模型比较结果如表4所示 , 结果显示 , 我们的模型在三个不同的设置下都能够达到最好的结果 。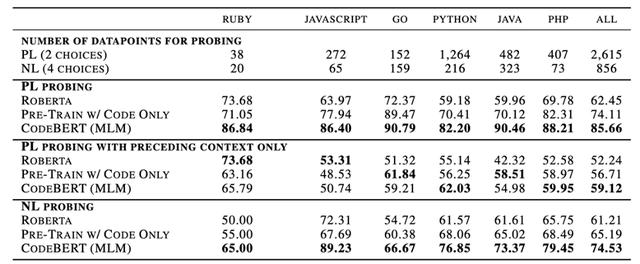 文章插图
文章插图
表4 NL-PL Probing结果
代码文档生成 我们研究了在预训练的六种编程语言上 , 代码到文档的生成问题 。 为了证明CodeBERT在代码到文档生成任务中的有效性 , 我们采用了各种预训练的模型作为编码器 , 并保持了超参数的一致性 。 实验结果如表5所示 , 我们的模型在所有编程语言类别上均获得最好的效果 。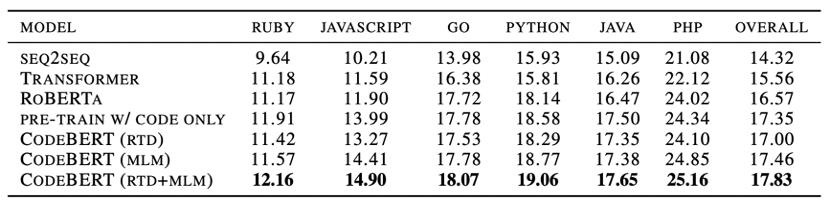 文章插图
文章插图
表5 代码文档生成结果
泛化能力 为了进一步研究模型的泛化性 , 我们在代码文档生成任务中 , 在C#编程语言上进行了测试 。 我们选择了Codenn数据集 , 这是一个包含Stack Overflow自动收集的66015对问题和答案的数据集 , 并采取了和原论文同样的设置进行实验 。 结果如表6所示 , 相比RoBERTa , 我们的模型能够取得更好的结果 。 但是 , 我们的模型效果略低于Code2Seq , 这可能是因为该模型有效使用了代码中的AST信息 。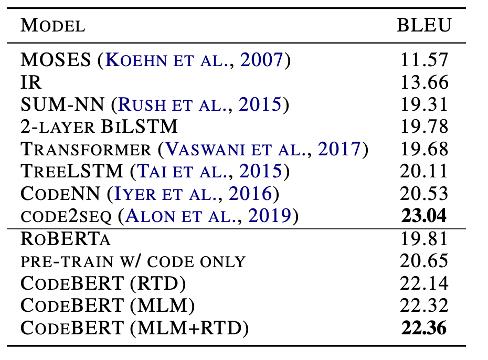 文章插图
文章插图
表6 C#生成结果
4 总结
在本工作中 , 我们提出了第一个面向编程语言和自然语言的预训练模型 , 并且在下游的自然语言代码检索 , 代码文档生成任务上 , 我们的模型均取得了SOTA的效果 。 另外 , 我们构造了第一个NL-PL Probing数据集来研究预训练模型学到了哪种类型的知识 。 虽然我们的模型已经取得了很好的效果 , 但也有很多潜在的方向值得进一步研究 , 比如在预训练过程加入与生成相关的目标函数 , 加入编程语言的AST结构信息等 。
[赠书福利]
AI科技评论联合【机械工业出版社华章公司】为大家带来15本“新版蜥蜴书”正版新书 。
在10月24号头条文章《1024快乐!最受欢迎的AI好书《蜥蜴书第2版》送给大家!》留言区留言 , 谈一谈你对本书内容相关的看法和期待 , 或你对机器学习/深度学习的理解 。
AI 科技评论将会在留言区选出 15名读者 , 每人送出《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》一本(在其他公号已获赠本书者重复参加无效) 。
活动规则:
1. 在留言区留言 , 留言点赞最高的前 15 位读者将获得赠书 。 获得赠书的读者请联系 AI 科技评论客服(aitechreview) 。
2. 留言内容会有筛选 , 例如“选我上去”等内容将不会被筛选 , 亦不会中奖 。
【CodeBERT: 面向编程语言和自然语言的预训练模型】3. 本活动时间为2020年10月24日 - 2020年10月31日(23:00) , 活动推送内仅允许中奖一次 。 文章插图
文章插图
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 面向工业化量产,GE粘结剂喷射金属3D打印发起合作伙伴计划
- 盘点:2020年5种流行的 AI 编程语言,就业高薪不是梦
- 零基础学习编程语言将面临哪几道门槛,以及该如何解决
- Java高级特性:循序渐进地培养面向对象的思维方式
- Rust的不足之处,让它无法成为一门成熟的编程语言
- 如何学好一门计算机编程语言?
- 在学习编程语言之前,可以先学习哪些知识
- 第8天 | 12天搞定Python,面向对象
- 2020年及以后的10种最受欢迎的编程语言