CodeBERT: 面向编程语言和自然语言的预训练模型
来自哈工大SCIR的冯掌印及其团队提出了面向编程语言和自然语言的预训练模型CodeBERT 。
CodeBERT通过预训练的方式学习一个通用表示来支持下游和编程语言相关的应用 , 比如自然语言代码检索 , 代码文档生成等 。
CodeBERT使用Transformer作为基本的网络结构 , 采用了混合目标函数:掩码语言模型(MLM)和替换词检测(RTD) 。
实验结果表明 , CodeBERT在下游的自然语言代码检索和代码文档生成任务上都取得了SOTA效果 。
为了进一步研究CodeBERT学到了哪些类型的知识 , 他们构造了第一个probing数据集 , 然后固定预训练好的参数来对模型进行检测 。 实验结果显示 , CodeBERT比其他预训练模型在probing上表现更好 。
论文名称:CodeBERT: A Pre-Trained Model for Programming and Natural Languages
论文作者:冯掌印 , 郭达雅 , 唐都钰 , 段楠 , 冯骁骋 , 公明 , 寿林钧 , 秦兵 , 刘挺 , 姜大昕 , 周明
原创作者:冯掌印
论文链接:
代码地址::
1 简介
大规模预训练模型在自然语言处理领域取得了重要的进展 。 这些预训练模型通过在没有标注的语料上进行自监督训练 , 可以学习到有效的上下文表示 。 自然语言处理领域预训练模型的成功 , 也推动了多模态预训练的发展 , 比如ViLBERT (Lu et al., 2019), VideoBERT (Sun et al., 2019)等 。 在本文中 , 我们提出了CodeBERT , 通过学习自然语言和编程语言之间的语义联系 , 能够支撑众多NL-PL相关的任务 。
2 模型
我们采用了Transformer作为模型的基本网络结构 。 具体地 , 我们使用了和RoBERTa-base完全一样的结构 , 即都有12层 , 每层有12个自注意头 , 每个头的大小是64 , 隐层维度为768 。 模型参数的总数为125M 。
在预训练阶段 , 将自然语言文本和编程语言的代码拼接起来作为输入 , 两部分内容均使用和RoBERTa-base一样的tokenizer 。 数据样例如图1所示 。 文章插图
文章插图
图1 NL-PL数据对样例
预训练数据集方面 , 我们使用了Husain等人在2019年提供的最新数据集CodeSearchNet , 里面包括 2.1M双模数据和6.4M 单模数据 , 其中双模数据是指自然语言-代码对的并行数据 , 单模是指只有代码的数据 。 数据集中包括六种编程语言 , 具体数据统计结果见表1 。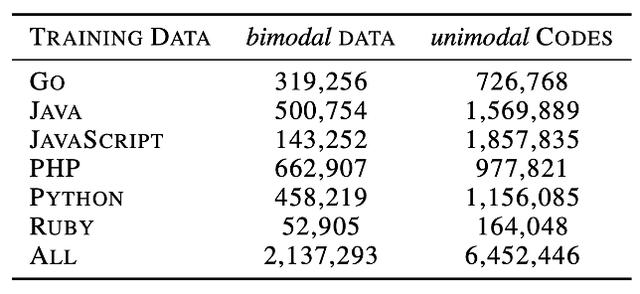 文章插图
文章插图
表1 预训练CodeBERT数据统计
为了同时利用双模数据和大规模的单模数据 , 我们提出了混合预训练目标:掩码语言模型(MLM) 和替换词检测(RTD) 。
目标1:掩码语言模型 。 将NL-PL对作为输入 , 随机为NL和PL选择位置进行掩码 , 然后用特殊的掩码Token进行替换 。 掩码语言模型的目标是预测出原始的token 。 目标2:替换词检测 。 先分别用单模的自然语言和代码数据各自训练一个数据生成器 , 用于为随机掩码位置生成合理的备选方案 。 另外 , 还有一个判别器学习自然语言和代码之间的融合表示 , 来检测一个词是否为原词 。 判别器实际上一个二元分类器 , 如果生成器产生正确的Token , 则该Token的标签为真 , 否则为假 。 模型架构如图2所示 。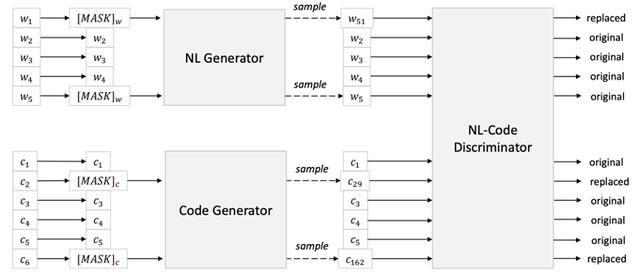 文章插图
文章插图
图2 替换词检测目标模型架构
最终 , 模型预训练目标为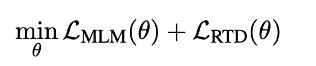 文章插图
文章插图
CodeBERT经过预训练之后 , 在下游任务使用时需要微调 。 例如在自然语言代码搜索中 , 会使用与预训练阶段相同的输入方式 。 而在代码到文本的生成中 , 使用编码器-解码器框架 , 并使用CodeBERT初始化生成模型的编码器 。
3 实验
我们选了四个不同的设置来验证模型的有效性 , 分别是自然语言代码检索 , NL-PL的probing , 代码文档生成 , 在未经过预训练编程语言上模型的泛化性 。
自然语言代码检索 给定一段自然语言作为输入 , 代码搜索的目标是从一组代码中找到语义上最相关的代码 。 为了进行比较 , 我们选择了Husain 等人在2019年发布的 CodeSearchNet 语料库进行训练 , 数据集中包括六种编程语言 , 各种语言的数据统计如表2所示 。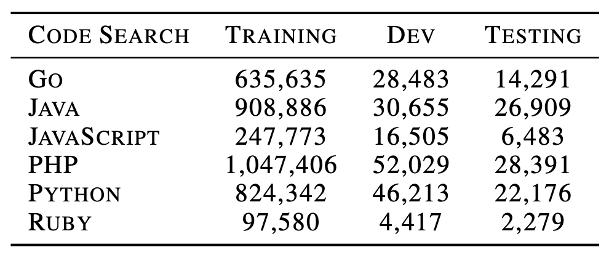 文章插图
文章插图
表2 自然语言代码检索数据集统计
我们保持和官方一致 , 使用MRR作为评价指标 。 另外 , 我们计算了六种编程语言上的宏平均作为整体的评价指标 。 结果如表3所示 , 相比之前的模型 , 我们的模型取得了明显的提升 。
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 面向工业化量产,GE粘结剂喷射金属3D打印发起合作伙伴计划
- 盘点:2020年5种流行的 AI 编程语言,就业高薪不是梦
- 零基础学习编程语言将面临哪几道门槛,以及该如何解决
- Java高级特性:循序渐进地培养面向对象的思维方式
- Rust的不足之处,让它无法成为一门成熟的编程语言
- 如何学好一门计算机编程语言?
- 在学习编程语言之前,可以先学习哪些知识
- 第8天 | 12天搞定Python,面向对象
- 2020年及以后的10种最受欢迎的编程语言