高性能解决线程饥饿的利器 StampedLock( 二 )
上面的使用例子中 , 需要引起注意的是 get()和 putIfNotExist() 方法 , 第一个使用了乐观读 , 使得读写可以并发执行 , 第二个则是使用了读锁转换成写锁的编程模型 , 先查询缓存 , 当不存在的时候从数据库读取数据并添加到缓存中 。
在使用乐观读的时候一定要按照固定模板编写 , 否则很容易出 bug , 我们总结下乐观读编程模型的模板:
public void optimisticRead() {// 1. 非阻塞乐观读模式获取版本信息long stamp = lock.tryOptimisticRead();// 2. 拷贝共享数据到线程本地栈中copyVaraibale2ThreadMemory();// 3. 校验乐观读模式读取的数据是否被修改过if (!lock.validate(stamp)) {// 3.1 校验未通过 , 上读锁stamp = lock.readLock();try {// 3.2 拷贝共享变量数据到局部变量copyVaraibale2ThreadMemory();} finally {// 释放读锁lock.unlockRead(stamp);}}// 3.3 校验通过 , 使用线程本地栈的数据进行逻辑操作useThreadMemoryVarables();}使用场景和注意事项对于读多写少的高并发场景 StampedLock的性能很好 , 通过乐观读模式很好的解决了写线程“饥饿”的问题 , 我们可以使用StampedLock 来代替ReentrantReadWriteLock, 但是需要注意的是 StampedLock 的功能仅仅是 ReadWriteLock 的子集 , 在使用的时候 , 还是有几个地方需要注意一下 。
- StampedLock是不可重入锁 , 使用过程中一定要注意;
- 悲观读、写锁都不支持条件变量 Conditon, 当需要这个特性的时候需要注意;
- 如果线程阻塞在 StampedLock 的 readLock() 或者 writeLock() 上时 , 此时调用该阻塞线程的 interrupt() 方法 , 会导致 CPU 飙升 。 所以 , 使用 StampedLock 一定不要调用中断操作 , 如果需要支持中断功能 , 一定使用可中断的悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly() 。 这个规则一定要记清楚 。
 文章插图
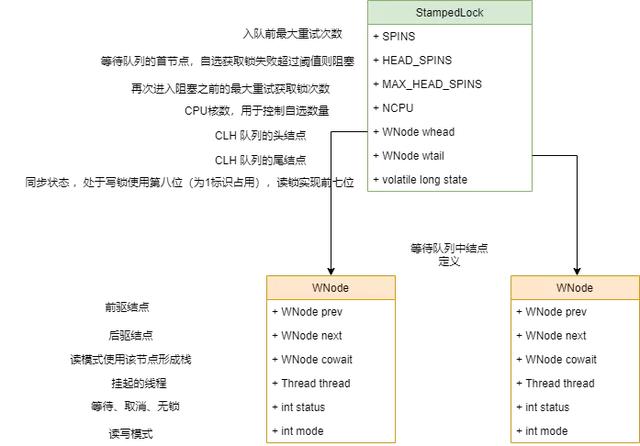
文章插图我们发现它并不像其他锁一样通过定义内部类继承 AbstractQueuedSynchronizer抽象类然后子类实现模板方法实现同步逻辑 。 但是实现思路还是有类似 , 依然使用了 CLH 队列来管理线程 , 通过同步状态值 state 来标识锁的状态 。
其内部定义了很多变量 , 这些变量的目的还是跟 ReentrantReadWriteLock 一样 , 将状态为按位切分 , 通过位运算对 state 变量操作用来区分同步状态 。
比如写锁使用的是第八位为 1 则表示写锁 , 读锁使用 0-7 位 , 所以一般情况下获取读锁的线程数量为 1-126 , 超过以后 , 会使用 readerOverflow int 变量保存超出的线程数 。
自旋优化
对多核 CPU 也进行一定优化 , NCPU 获取核数 , 当核数目超过 1 的时候 , 线程获取锁的重试、入队钱的重试都有自旋操作 。 主要就是通过内部定义的一些变量来判断 , 如图所示 。
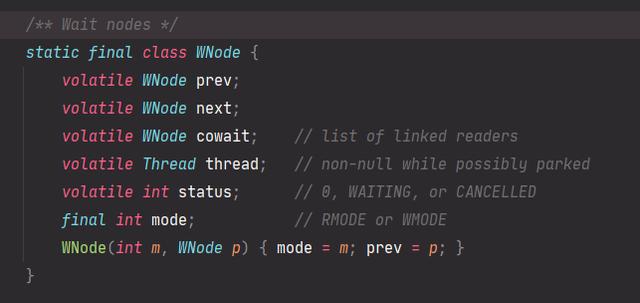
等待队列队列的节点通过 WNode 定义 , 如上图所示 。 等待队列的节点相比 AQS 更简单 , 只有三种状态分别是:
- 0:初始状态;
- -1:等待中;
- 取消;
 文章插图
文章插图同时定义了两个变量分别指向头结点与尾节点 。
/** Head of CLH queue */private transient volatile WNode whead;/** Tail (last) of CLH queue */private transient volatile WNode wtail;另外有一个需要注意点就是 cowait ,保存所有的读节点数据 , 使用的是头插法 。当读写线程竞争形成等待队列的数据如下图所示:
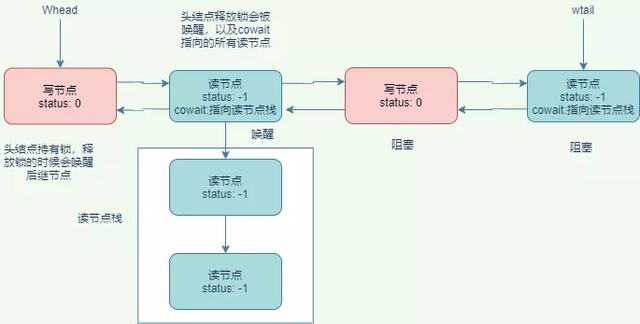 文章插图
文章插图获取写锁
public long writeLock() {long s, next;// bypass acquireWrite in fully unlocked case onlyreturn ((((s = state) }获取写锁 , 如果获取失败则构建节点放入队列 , 同时阻塞线程 , 需要注意的时候该方法不响应中断 , 如需中断需要调用 writeLockInterruptibly() 。 否则会造成高 CPU 占用的问题 。(s = state)// bypass acquireRead on common uncontended casereturn ((whead == wtail }获取读锁关键步骤
(whead == wtail && (s & ABITS) < RFULL如果队列为空并且读锁线程数未超过限制 , 则通过 U.compareAndSwapLong(this, STATE, s, next = s + RUNIT))CAS 方式修改 state 标识获取读锁成功 。
否则调用 acquireRead(false, 0L) 尝试使用自旋获取读锁 , 获取不到则进入等待队列 。
acquireRead
当 A 线程获取了写锁 , B 线程去获取读锁的时候 , 调用 acquireRead 方法 , 则会加入阻塞队列 , 并阻塞 B 线程 。 方法内部依然很复杂 , 大致流程梳理后如下:
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 恢复|电脑文件不小心被删除了怎么恢复?文件恢复可以用这招解决!
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 手机|手机发热怎么办?手机发烫的解决办法及原因
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 业务|社会化用工行业报告:社会化用工潜力大 解决方案服务供应商迎机遇
- 解决问题|新业态应成为劳动权益保护高地
- 驱动|开源之系统:Ubuntu20.04电脑安装无线网卡驱动并解决包依赖关系