dotNET 5中的gRPC性能改进,超Golang和C++
还有一个月 , 下个月微软.NET 5将会正式发布 , 在大家都关注新型语言 。 不知道有对.NET 5有没有什么期待 。 文章插图
文章插图
日前官方发布了一些针对.net 5特性说明的 , 其中gRPC性能上的表现令人瞩目 。 在不同gRPC服务器实现的社区运行基准测试中 , .NET的QPS超越C++和Go , 排在Rust之后夺得亚军 。
gRPC是现代的开源远程过程调用框架 。 gRPC有许多令人兴奋的功能:实时流传输 , 端到端代码生成以及强大的跨平台支持 。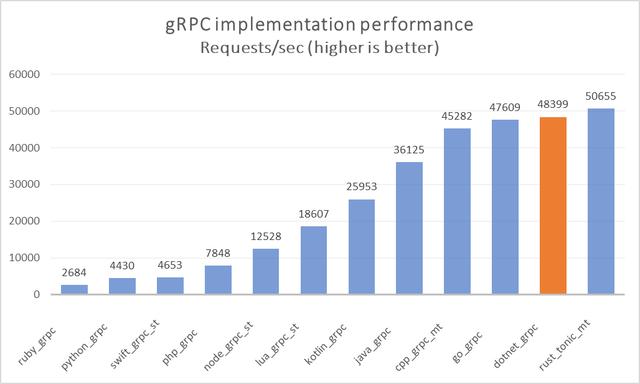 文章插图
文章插图
结果基于.NET 5中完成的工作 。 基准测试表明.NET 5服务器性能比.NET Core 3.1快60% 。 .NET 5客户端性能比.NET Core 3.1快230% 。
本文我们就一起来学习下.NET 5究竟使用什么黑魔法能让性能如此大幅度的提高 。
减少内存分配去年 , Microsoft给CNCF提供了.NET的gRPC的新实现 。 该框架建立在Kestrel和HttpClient之上的 , gRPC成为.NET生态系统的一流成员 。
gRPC使用HTTP/2作为其基础协议 。 当涉及到性能时 , 快速的HTTP/2实现是最重要的因素 。 .NET的gRPC服务器基于Kestrel建立 , Kestrel是用C#编写的HTTP服务器 , 其设计中关注立足于性能 , 在TechEmpower基准测试中的性能最高的选手之一 。 而gRPC会自动从Kestrel的许多性能改进中受益 。 但是 , .NET 5中进行了许多HTTP/2特定的优化 。
减少内存分配是首先优化的部分 。 减少每个HTTP/2请求内存分配 , 就能减少垃圾回收(GC)的时间 。
下面是请求超过10w个gRPC请求时候的性能分析器: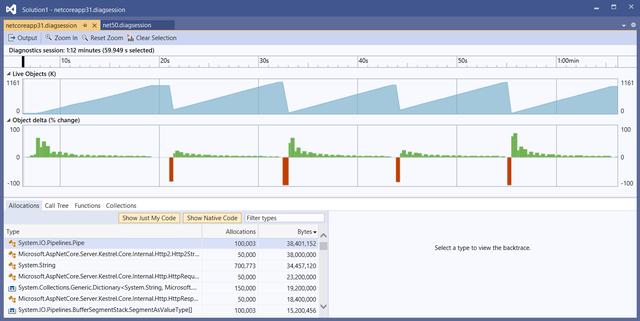 文章插图
文章插图
活动对象图的锯齿形图案表示内存在建立 , 然后进行了垃圾回收 。 每个请求大约要分配3.9KB 。
通过在HTTP / 2连接中添加了连接池 , 每个请求的内存分配减少了一半 。 它可支持对内部类型(如Http2Stream和)和公共可访问类型(如HttpContext和HttpRequest)请求重用 。
合并流后 , 可以进行一系列优化:
重用输入和输出Pipe实例 。
重用已知的标头字符串值 。 与头重用有关 , 添加HTTP/伪装头作为已知头 。 String分配使用倒数第三字节 。
重用了一些较小的按请求对象 。
当服务器处于负载状态时 , 连接池非常有用 , 但是也需要释放不再使用的内存 。 如果最近5秒钟内HTTP请求没有使用 , 则从连接池中删除该流 。
还有许多较小的减少内存分配的方法:
删除Kestrel的HTTP/2流控制中的分配 。
每当触发流控制时 , 可重置的ManualResetValueTaskSourceCore类型将替换分配新对象 。
验证HTTP请求路径时 , 将数组分配替换为stackalloc 。
消除了一些与日志记录有关的意外分配 。
如果任务已经完成 , 避免分配 。
最后通过特殊的Taskcontent-length 0字节保存字符串分配 。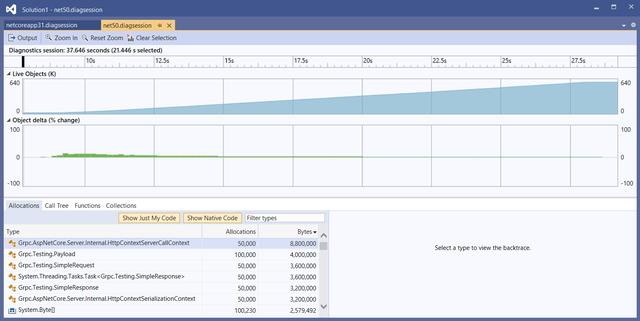 文章插图
文章插图
经过优化后 , .NET 5中的每个请求内存分配只有330B , 减少了92% 。 优化后锯齿图案不再出现 。 这样在服务器处理10w个gRPC调用时 , 垃圾收集也不再会运行 。
从Kestrel中读取HTTP标头HTTP/2连接支持通过TCP Socket的并发请求 , 这个功能称为多路复用 。 它允许HTTP/2有效利用连接 , 但是一次只能处理一个连接上的一个请求的标头 。 HTTP/2的HPack标头压缩是有状态的 , 并且取决于顺序 。 处理HTTP/2标头是一个瓶颈 , 因此要尽可能快 。
优化的性能HPackDecoder 。 解码器是一个状态机 , 可读取传入的HTTP/ 2 HEADER帧 。 状态机允许Kestrel在帧到达时对其进行解码 , 但是解码器在解析每个字节之后检查状态 。 另一个问题是语义值 , 标头名称和值被复制了多次 。 该PR的优化包括:
加强解析循环 。 例如 , 如果刚刚解析了标头名称 , 则该值必须在后面 。 无需检查状态机即可确定下一个状态 。
跳过所有语义解析 。 HPack中的文字具有长度前缀 。 如果知道接下来的100个字节是语义 , 则无需检查每个字节 。 标记语义的位置并在其末尾继续解析 。
避免复制语义字节 。 以前 , 原义字节在传递给Kestrel之前总是复制到中间数组 。 在大多数情况下 , 这不是必需的 , 而是可以对原始缓冲区进行切片 , 然后将ReadOnlySpan传递给Kestrel 。
这些更改一起显着减少了解析标头所需的时间 。 标头大小几乎不再成了影响因素 。 解码器标记值的开始和结束位置 , 然后切片该范围 。
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 夹缝|“互联网卖菜”背后:夹缝中的菜贩与巨头们的垄断
- 骁龙865|5G手机中的性能怪兽,256+120W闪充,比iPhone12值得买
- RFID在冷链物流中的作用-RFID冷链资产管理解决方案
- 成员|千元机中的实力派再添新成员,三部千元机,一部更比一部强!
- Kotlin集合vs Kotlin序列与Java流
- 金融市场中的NLP——情感分析
- 二叉树:求搜索树中的众数
- USB接口中的皇帝!浅析雷电Thunderbolt的前生今世
- 面试官:聊聊 etcd 中的 Raft 吧