Python入门教程!手把手教会你爬取网页数据( 二 )
在实际的使用过程中 , 到底使用 BeautifulSoup 还是 XPath , 完全取决于个人喜好 , 哪个用起来更加熟练方便 , 就使用哪个 。
爬虫实战:爬取豆瓣海报我们可以从豆瓣影人页 , 进入都影人对应的影人图片页面 , 比如以刘涛为例子 , 她的影人图片页面地址为
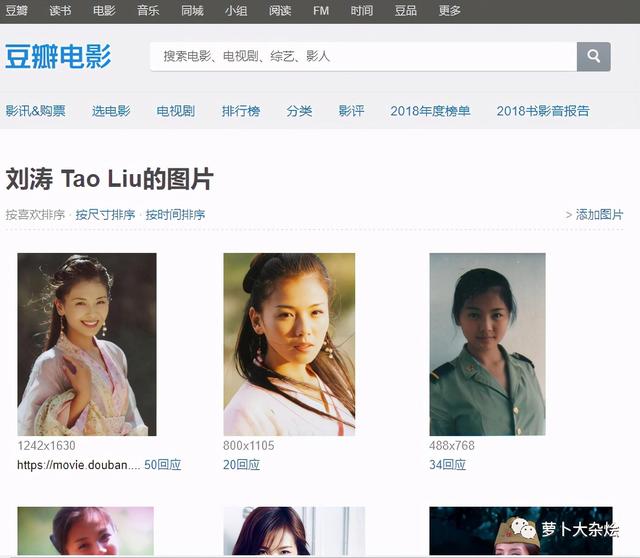 文章插图
文章插图
下面我们就来分析下这个网页
目标网站页面分析注意:网络上的网站页面构成总是会变化的 , 所以这里你需要学会分析的方法 , 以此类推到其他网站 。 正所谓授人以鱼不如授人以渔 , 就是这个原因 。
Chrome 开发者工具Chrome 开发者工具(按 F12 打开) , 是分析网页的绝佳利器 , 一定要好好使用 。
我们在任意一张图片上右击鼠标 , 选择“检查” , 可以看到同样打开了“开发者工具” , 而且自动定位到了该图片所在的位置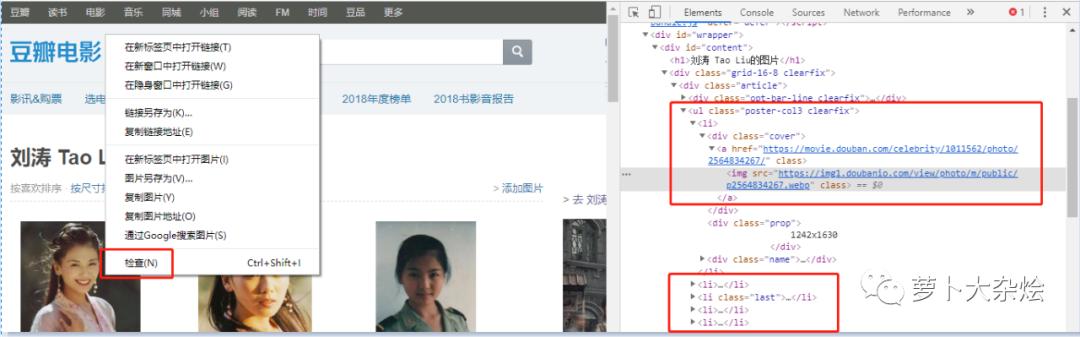 文章插图
文章插图
可以清晰的看到 , 每张图片都是保存在 li 标签中的 , 图片的地址保存在 li 标签中的 img 中 。
知道了这些规律后 , 我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面 , 从而获取其中的图片地址 。
代码编写我们只需要短短的几行代码 , 就能完成图片 url 的提取
import requestsfrom bs4 import BeautifulSoupurl = ''res = requests.get(url).textcontent = BeautifulSoup(res, "html.parser")data = http://kandian.youth.cn/index/content.find_all('div', attrs={'class': 'cover'})picture_list = []for d in data:plist = d.find('img')['src']picture_list.append(plist)print(picture_list)>>>['', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '']可以看到 , 是非常干净的列表 , 里面存储了海报地址 。 但是这里也只是一页海报的数据 , 我们观察页面发现它有好多分页 , 如何处理分页呢 。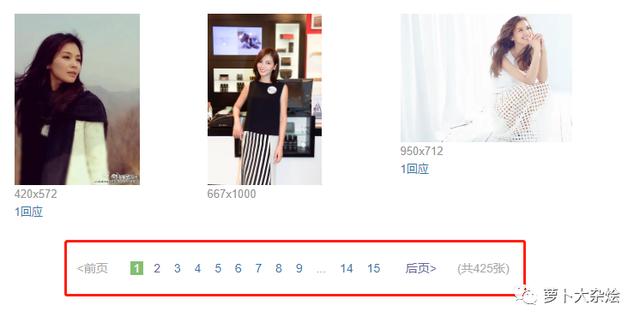 文章插图
文章插图
分页处理我们点击第二页 , 看看浏览器 url 的变化
?type=C --tt-darkmode-color: #999999;">发现浏览器 url 增加了几个参数
再点击第三页 , 继续观察 url
?type=C --tt-darkmode-color: #999999;">通过观察可知 , 这里的参数 , 只有 start 是变化的 , 即为变量 , 其余参数都可以按照常理来处理
同时还可以知道 , 这个 start 参数应该是起到了类似于 page 的作用 , start = 30 是第二页 , start = 60 是第三页 , 依次类推 , 最后一页是 start = 420 。
于是我们处理分页的代码也呼之欲出了
首先将上面处理 HTML 页面的代码封装成函数
def get_poster_url(res):content = BeautifulSoup(res, "html.parser")data = http://kandian.youth.cn/index/content.find_all('div', attrs={'class': 'cover'})picture_list = []for d in data:plist = d.find('img')['src']picture_list.append(plist)return picture_list然后我们在另一个函数中处理分页和调用上面的函数
def fire():page = 0for i in range(0, 450, 30):print("开始爬取第 %s 页" % page)url = '?type=C --tt-darkmode-color: #999999;">此时 , 我们所有的海报数据都保存在了 data 变量中 , 现在就需要一个下载器来保存海报了
def download_picture(pic_l):if not os.path.exists(r'picture'):os.mkdir(r'picture')for i in pic_l:pic = requests.get(i)p_name = i.split('/')[7]with open('picture\\' + p_name, 'wb') as f:f.write(pic.content)再增加下载器到 fire 函数 , 此时为了不是请求过于频繁而影响豆瓣网的正常访问 , 设置 sleep time 为1秒
def fire():page = 0for i in range(0, 450, 30):print("开始爬取第 %s 页" % page)url = '?type=C --tt-darkmode-color: #999999;">下面就执行 fire 函数 , 等待程序运行完成后 , 当前目录下会生成一个 picture 的文件夹 , 里面保存了我们下载的所有海报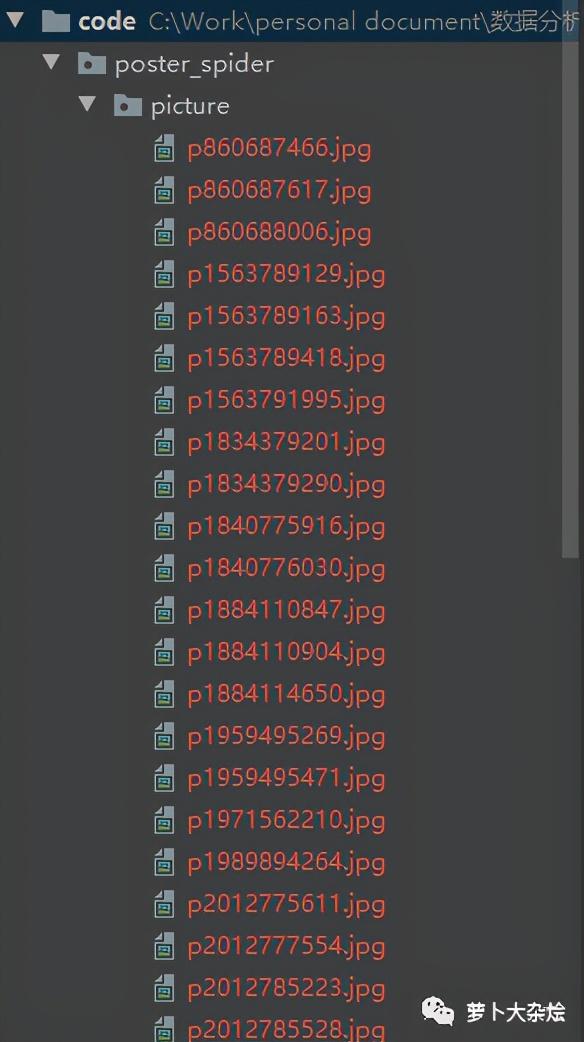 文章插图
文章插图
核心代码讲解下面再来看下完整的代码
import requestsfrom bs4 import BeautifulSoupimport timeimport osdef fire():page = 0for i in range(0, 450, 30):print("开始爬取第 %s 页" % page)url = '?type=C --tt-darkmode-color: #999999;">fire 函数
这是一个主执行函数 , 使用 range 函数来处理分页 。
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- 十分钟教会你使用Python操作excel,内附步骤和代码