Python入门教程!手把手教会你爬取网页数据
其实在当今社会 , 网络上充斥着大量有用的数据 , 我们只需要耐心的观察 , 再加上一些技术手段 , 就可以获取到大量的有价值数据 。 这里的“技术手段”就是网络爬虫 。 今天就给大家分享一篇爬虫基础知识和入门教程:
什么是爬虫?爬虫就是自动获取网页内容的程序 , 例如搜索引擎 , Google , Baidu 等 , 每天都运行着庞大的爬虫系统 , 从全世界的网站中爬虫数据 , 供用户检索时使用 。
爬虫流程其实把网络爬虫抽象开来看 , 它无外乎包含如下几个步骤
- 模拟请求网页 。 模拟浏览器 , 打开目标网站 。
- 获取数据 。 打开网站之后 , 就可以自动化的获取我们所需要的网站数据 。
- 保存数据 。 拿到数据之后 , 需要持久化到本地文件或者数据库等存储设备中 。
Requests 使用Requests 库是 Python 中发起 HTTP 请求的库 , 使用非常方便简单 。
模拟发送 HTTP 请求
发送 GET 请求
当我们用浏览器打开豆瓣首页时 , 其实发送的最原始的请求就是 GET 请求
import requestsres = requests.get('')print(res)print(type(res))>>>可以看到 , 我们得到的是一个 Response 对象如果我们要获取网站返回的数据 , 可以使用 text 或者 content 属性来获取
text:是以字符串的形式返回数据
content:是以二进制的方式返回数据
print(type(res.text))print(res.text)>>> ..... 发送 POST 请求对于 POST 请求 , 一般就是提交一个表单
r = requests.post('', data=http://kandian.youth.cn/index/{"key": "value"})data 当中 , 就是需要传递的表单信息 , 是一个字典类型的数据 。header 增强
对于有些网站 , 会拒绝掉没有携带 header 的请求的 , 所以需要做一些 header 增强 。 比如:UA , Cookie , host 等等信息 。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36","Cookie": "your cookie"}res = requests.get('', headers=header)解析 HTML现在我们已经获取到了网页返回的数据 , 即 HTML 代码 , 下面就需要解析 HTML , 来提取其中有效的信息 。
BeautifulSoup
BeautifulSoup 是 Python 的一个库 , 最主要的功能是从网页解析数据 。
from bs4 import BeautifulSoup# 导入 BeautifulSoup 的方法# 可以传入一段字符串 , 或者传入一个文件句柄 。 一般都会先用 requests 库获取网页内容 , 然后使用 soup 解析 。 soup = BeautifulSoup(html_doc,'html.parser')# 这里一定要指定解析器 , 可以使用默认的 html , 也可以使用 lxml 。 print(soup.prettify())# 按照标准的缩进格式输出获取的 soup 内容 。 BeautifulSoup 的一些简单用法print(soup.title)# 获取文档的 titleprint(soup.title.name)# 获取 title 的 name 属性print(soup.title.string)# 获取 title 的内容print(soup.p)# 获取文档中第一个 p 节点print(soup.p['class'])# 获取第一个 p 节点的 class 内容print(soup.find_all('a'))# 获取文档中所有的 a 节点 , 返回一个 listprint(soup.find_all('span', attrs={'style': "color:#ff0000"}))# 获取文档中所有的 span 且 style 符合规则的节点 , 返回一个 list具体的用法和效果 , 我会在后面的实战中详细说明 。XPath 定位
XPath 是 XML 的路径语言 , 是通过元素和属性进行导航定位的 。 几种常用的表达式
表达式含义node选择 node 节点的所有子节点/从根节点选取//选取所有当前节点.当前节点..父节点@属性选取text()当前路径下的文本内容
一些简单的例子
xpath('node')# 选取 node 节点的所有子节点xpath('/div')# 从根节点上选取 div 元素xpath('//div')# 选取所有 div 元素xpath('./div')# 选取当前节点下的 div 元素xpath('//@id')# 选取所有 id 属性的节点当然 , XPath 非常强大 , 但是语法也相对复杂 , 不过我们可以通过 Chrome 的开发者工具来快速定位到元素的 xpath , 如下图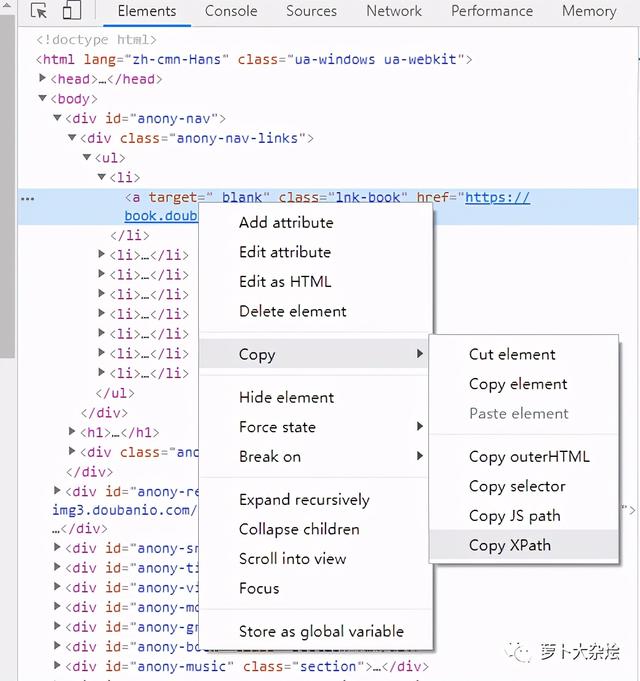 文章插图
文章插图得到的 xpath 为
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- 十分钟教会你使用Python操作excel,内附步骤和代码