使用Go进行io_uring的动手实践( 二 )
- 结果 : 的返回值 readv syscall。如果成功 , 它将读取字节数 。否则 , 它将具有错误代码 。
- 用户数据 :我们在SQE中传递的标识符 。
这意味着我们实际上在内存中映射了三件事:提交队列 , 完成队列和提交队列数组 。下图应使情况更清楚:
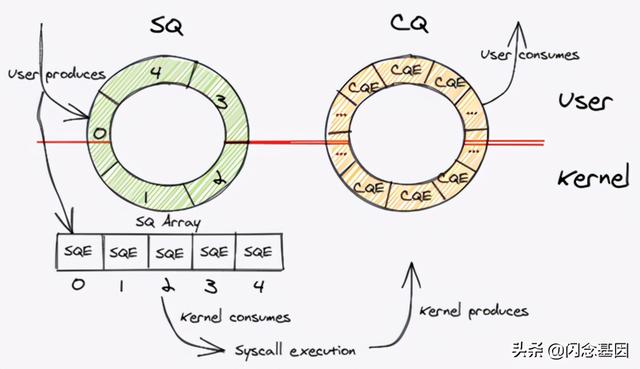 文章插图
文章插图现在 , 让我们重新访问 的 flags 之前跳过 字段 。正如我们所讨论的 , CQE条目可能完全不同于队列中提交的条目 。这带来了一个有趣的问题 。如果我们要一个接一个地执行一系列I / O操作怎么办? 例如 , 文件副本 。我们想从文件描述符中读取并写入另一个文件 。在当前状态下 , 我们甚至无法开始提交写入操作 , 直到看到CQ中出现读取事件为止 。那就是 的地方 flags 进来。
我们可以 设置 IOSQE_IO_LINK 在 flags 现场 以实现这一目标 。如果设置了此选项 , 则下一个SQE将自动链接到该SQE , 直到当前SQE完成后它才开始 。这使我们能够按所需方式对I / O事件执行排序 。文件复制只是一个示例 。从理论上讲 , 我们可以 链接 任何 彼此 系统调用 , 直到在未设置该字段的情况下推送SQE , 此时该链被视为已损坏 。
系统调用通过对 简要概述 io_uring 操作方式的, 让我们研究实现它的实际系统调用 。只有两个 。
- int io_uring_setup(unsigned entries, struct io_uring_params *params);
- int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t sig);
fdto_submitmin_complete精明的读者会注意到 ,中具有 to_submit 和 min_complete 在相同的调用 意味着我们可以使用它来仅提交 , 或仅完成 , 甚至两者! 这将打开API , 以根据应用程序工作负载以各种有趣的方式使用 。轮询模式对于延迟敏感的应用程序或具有极高IOPS的应用程序 , 每次有可用数据读取时让设备驱动程序中断内核是不够高效的 。如果我们要读取大量数据 , 那么高中断率实际上会减慢用于处理事件的内核吞吐量 。在这些情况下 , 我们实际上会退回轮询设备驱动程序 。要将轮询与一起使用 io_uring, 我们可以 设置 IORING_SETUP_IOPOLL 在 标志 io_uring_setup 呼叫中, 并将轮询事件与 的 保持一致 IORING_ENTER_GETEVENTS 设置 io_uring_enter 呼叫中。
但这仍然需要我们(用户)拨打电话 。为了提高性能 ,,io_uring 它还具有称为“内核侧轮询”的功能 通过该功能 , 如果将 设置为 IORING_SETUP_SQPOLL 标志 io_uring_params, 内核将自动轮询SQ以检查是否有新条目并使用它们 。这基本上意味着我们可以继续做所有的I /我们想?不执行甚至一个 单一的。系统。打电话。这改变了一切 。
但是 , 所有这些灵活性和原始功率都是有代价的 。直接使用此API并非易事且容易出错 。由于我们的数据结构是在用户和内核之间共享的 , 因此我们需要设置内存屏障(神奇的编译器命令以强制执行内存操作的顺序)和其他技巧 , 以正确完成任务 。
幸运的是 , 的创建者Jens Axboe io_uring 创建了一个包装器库 ,liburing 以帮助简化所有操作 。使用 liburing, 我们大致必须执行以下步骤:
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验