使用Go进行io_uring的动手实践
作者:秃头大哥
出处:
在Linux中 , 系统调用(syscalls)是一切的核心 。它们是应用程序与内核交互的主要接口 。因此 , 至关重要的是它们要快 。尤其在后Spectre / Meltdown后世界中 , 这一点尤为重要 。
如果觉得看完文章有所收获的话 , 可以关注我一下哦
知乎: 秃顶之路:
【使用Go进行io_uring的动手实践】b站: linux亦有归途:
大部分系统调用都处理I / O , 因为大多数应用程序都是这样做的 。对于网络I / O , 我们拥有 epoll 一系列syscall , 它们为我们提供了相当快的性能 。但是在文件系统I / O部门中 , 有点缺乏 。我们已经有 async_io 一段时间了 , 但是除了少量的利基应用程序之外 , 它并不是非常有益 。主要原因是它仅在使用 打开文件时才起作用 O_DIRECT 标志。这将使内核绕过所有操作系统缓存 , 并尝试直接在设备之间进行读写 。当我们试图使事情进展很快时 , 这不是执行I / O的好方法 。在缓冲模式下 , 它将同步运行 。
All that is changing slowly because now we have a brand new interface to perform I/O with the kernel: io_uring。
周围有很多嗡嗡声 。没错 , 因为它为我们提供了一个与内核进行交互的全新模型 。让我们深入研究它 , 并尝试了解它是什么以及它如何解决问题 。然后 , 我们将使用Go来构建一个小型演示应用程序来使用它 。
背景让我们退后一步 , 想一想通常的系统调用是如何工作的 。我们进行系统调用 , 我们在用户层中的应用程序调用内核 , 并在内核空间中复制数据 。完成内核执行后 , 它将结果复制回用户空间缓冲区 。然后返回 。所有这些都在syscall仍然被阻止的情况下发生 。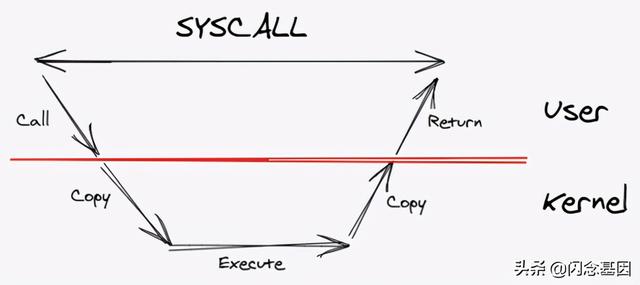 文章插图
文章插图
马上 , 我们可以看到很多瓶颈 。有很多复制 , 并且有阻塞 。Go通过在应用程序和内核之间引入另一层来解决此问题:运行时 。它使用一个虚拟实体(通常称为 P ) , 其中包含要运行的goroutine队列 , 然后将其映射到OS线程 。
这种间接级别使它可以进行一些有趣的优化 。每当我们进行阻塞的syscall时 , 运行时就知道了 , 它会将线程与 的 分离 P 执行goroutine, 并获得一个新线程来执行其他goroutine 。这称为越区切换 。而当系统调用返回时 , 运行时尝试将其重新安装到 P。如果无法获得免费的 P, 它将把goroutine推入队列以待稍后执行 , 并将线程存储在池中 。当您的代码进入系统调用时 , 这就是Go呈现“非阻塞”状态的方式 。
很好 , 但是仍然不能解决主要问题 , 即仍然发生复制并且实际的syscall仍然阻塞 。
让我们考虑一下手头的第一个问题:复制 。我们如何防止从用户空间复制到内核空间? 好吧 , 显然我们需要某种共享内存 。好的 , 可以使用 来完成 , 该 mmap 系统调用 系统调用可以映射用户与内核之间共享的内存块 。
那需要复制 。但是同步呢? 即使我们不复制 , 我们也需要某种方式来同步我们和内核之间的数据访问 。否则 , 我们将遇到相同的问题 , 因为应用程序将需要再次进行syscall才能执行锁定 。
如果我们将问题视为用户和内核是两个相互独立的组件 , 那么这本质上就是生产者-消费者问题 。用户创建系统调用请求 , 内核接受它们 。完成后 , 它会向用户发出信号 , 表明已准备就绪 , 并且用户会接受它们 。
幸运的是 , 这个问题有一个古老的解决方案:环形缓冲区 。环形缓冲区允许生产者和使用者之间实现高效同步 , 而根本没有锁定 。正如您可能已经知道的那样 , 我们需要两个环形缓冲区:一个提交队列(SQ) , 其中用户充当生产者并推送syscall请求 , 内核使用它们;还有一个完成队列(CQ) , 其中内核是生产者推动完成结果 , 而用户使用它们 。
使用这种模型 , 我们完全消除了所有内存副本和锁定 。从用户到内核的所有通信都可以非常高效地进行 。这实质上是 的核心思想 io_uring 实施。让我们简要介绍一下它的内部 , 看看它是如何实现的 。
io_uring简介要将请求推送到SQ , 我们需要创建一个提交队列条目(SQE) 。假设我们要读取文件 。略过许多细节 , SQE基本上将包含:
- 操作码 :描述要进行的系统调用的操作码 。由于我们对读取文件感兴趣 , 因此我们将使用 的 readv 映射到操作码 系统调用 IORING_OP_READV。
- 标志 :这些是可以随任何请求传递的修饰符 。我们稍后会解决 。
- Fd :我们要读取的文件的文件描述符 。
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验