伯克利&清华从GPT等预训练语言模型中无监督构建出知识图谱( 三 )
在TAC KBP上 , 本文与两个经典的开放信息抽取模型OpenIE 5.1(Ollie系统的后继)以及Stanford OpenIE系统(目前TAC KBP 2013任务上最好的开放信息抽取系统)的抽取结果进行了比较 。
表2实验表明 , MAMA-GPT-2_XL取得了最好的实验结果 , 也超越了传统的基于句法解析的信息抽取模型 。
同时本文发现 , 随着预训练模型参数量的增大 , 生成结果的表现会更好 。
另外 , 在同等规模的参数下 , BERT在F1指标和召回率的表现相对GPT-2系列模型更好;但是GPT-2的精确度却要更高一些 。
这可能是由于Masked LM的训练目标使得BERT学习到比GPT-2更灵活、但也噪音更大的知识 。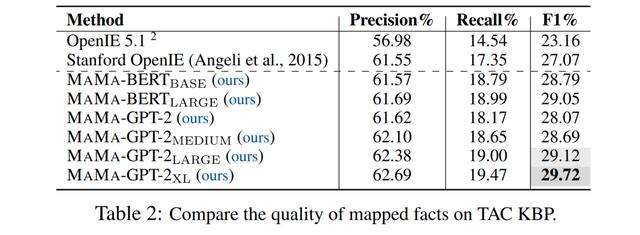 文章插图
文章插图
更进一步的 , 我们在更大规模的Wikidata上验证了我们的结果 。
表3中实验结果表明 , 在更大规模的语料上 , 相比TAC KBP , MAMA取得了比开放信息抽取方法好得多的表现 。 同时 , 这也说明了MAMA具有在大规模语料上的扩展能力 。
值得注意的是 , Wikidata中知识的构建 , 很多并非从Wikipedia的文本得来 , 所以实验的F1表现要比小规模、完全从目标文本中构建的TAC KBP要低一些 。
同时也说明了更大规模的文本语料中蕴含有更多的待发掘的知识 。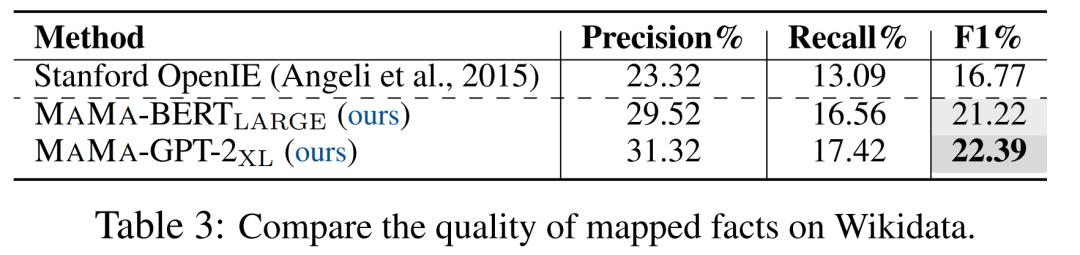 文章插图
文章插图
最后 , 我们也对开放schema内的知识进行了采样和人工评估 。
结果发现 , 抽取出的开放schema知识中 , 大约35%的知识都是正确的 。
这也证明了当前的大规模知识图谱仍然是不完整完善、需要进一步的补充和优化的 。
最后 , 一系列实验结果都表明预训练语言模型中存储了丰富的知识 , 不但数量上可以超越当前既有的知识图谱 , schema上也更加灵活开放 。
更多详细的实验分析 , 请参考原文 , 另外论文附录中也提供了详细的知识样例 。
4 作者简介
王晨光:加州大学伯克利分校博士后 , 师从Dawn Song 。
研究方向:自然语言处理、机器学习系统、安全 。
个人主页:
刘潇:清华大学四年级本科生 , 师从唐杰教授 。
研究方向:知识图谱 , 自监督学习 。
Dawn Song:加州大学伯克利分校教授 , ACM Fellow、IEEE Fellow、麦克阿瑟天才奖、古根海姆奖、斯隆奖、AMiner发布的全球计算机安全领域最具影响力的学者奖得主 。
研究方向:深度学习、安全、区块链 。
个人主页:~dawnsong/
本文的工作某种程度上具有突破意义 , 称得上是一个重要发现的开端 , 为此AI科技评论特地联系到了本文的作者 , 对本文的工作问了以下一些问题 , 以对本工作的前因后果以及存在的优缺点做一个全面的呈现 。
5AI科技评论十五问1、AI科技评论:这项工作的完成中 , 哪些人对您帮助或支持很大?
作者:特别感谢Dawn Song , 她给文章提供了大力的全面的支持 。 另外 , 也要感谢伯克利组里的小伙伴以及一些朋友和师长 , Xinyun Chen, Yu Gai, Dan Hendrycks, Qingsong Lv, Yangqiu Song, Jie Tang, and Eric Wallace , 他们给文章写作、实验提供了很多很有意义的建议 。
2、AI科技评论:从预训练语言模型中构建知识图谱 , 这项工作的idea怎么来的?
作者:源自一次偶然的实验 , 发现BERT和GPT-2中的注意力权重可以连接句子中可能的知识成分 。
3、AI科技评论:团队之前对知识图谱有过研究吗?对预训练语言模型又有过哪些深耕研究?
作者:团队一直对知识图谱进行着深入的研究 。 例如Dawn Song在主导计算机安全领域的知识体系构建 , 王晨光的博士毕业课题就是关于知识图谱构建 , 刘潇参与了构建全球最大开放学术图谱Open Academic Graph (OAG) 。
Dawn Song做过大量有影响力的深度学习工作 , 例如利用预训练模型提升分布的鲁棒性、对抗攻击、程序合成、设计更好的衡量GPT-3效果的指标等 。
4、AI科技评论:传统的构建知识图谱的方式有哪些?具体举一些例子 。
作者:构建知识图谱的方式大致分两种:
1)有监督的方式 。 例如:Wikidata, Freebase, YAGO, YAGO2, DBpedia 。 这些知识图谱中的知识都是人工基于类似于Wikipedia的inforbox这样的数据源贡献的 。
2)半监督方式 。 像是开放信息抽取系统 , 例如OLLIE, Reverb, Stanford OpenIE, OpenIE 5.1等 。 这些系统利用一些语言特征 , 例如句法分析 , 从语料中抽取开放schema的知识图谱 。 还有一些知识图谱 , 例如NELL, DeepDive, Knowledge Vault或多或少都需要人工参与来贡献固定schema的知识 。
- 势不可挡|清华教授刘瑜:我的女儿正势不可挡地成为一个普通人
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 京东另类科学实验室之"5G来了"
- 清华大学刘知远:知识指导的自然语言处理
- ICPC--1200:数组的距离时间限制&1201:众数问题
- "财富梦"AI外贸配方?国货搭载AI"火箭营销"?
- ICPC--1206: 字符串的修改&1207:字符排列问题
- ICPC--1204: 剔除相关数&1205: 你爱我么?
- 音乐平台"改头换面",是新一轮社交平台,还是生活放松圈
- MITRE ATT&CK系列文章之Windows管理共享风险检测