伯克利&清华从GPT等预训练语言模型中无监督构建出知识图谱( 二 )
如图2(a)所示 , 在第1步生成中(即图中的橙色箭头) , “is”被加入到当前生成的候选三元组中得到“(Dylan, is”:因为如图2(b)中所示 , 在从Dylan出发的注意力权重中(矩阵第一列) , is具有最大的注意力分数 。 当前候选匹配度变为0.3(即0+0.3) 文章插图
文章插图
图2
在实际操作中 , 由于Transformer具有多头注意力 , 我们尝试了不同的注意力权重合并策略 , 并最后发现取多头平均注意力权重的效果最好(详情参考附录) 。 在第2步的生成中 , 我们采用相同的步骤 , 跳过了a生成了songwriter , 进而得到“(Dylan, is songwriter” 。 候选的匹配度此时为0.7(即0.3+0.4) 。
3. STOP(停止):如果当前候选已到达尾部实体 , 那么我们将这整个三元组加入到集束中作为候选知识 。 当集束大小为1时 , (Dylan, is, songwriter)就成为了唯一的结果 。 对应的最终匹配度为0.7 。
以上只是MATCH算法的一个简单例子 , 详情请参考原文 。 在实际的语句中 , 我们还会遇到知识以反向的形式存在的情况 , 如“… said Jason Forcier, a vice president at battery maker A123 Systems Inc.”, 因此我们允许MATCH算法进行双向的搜索 。 集束的大小也不局限于1 , 在实际搜索中以宽度优先的方式进行 , 最后返回匹配程度最高的k条候选知识 。 这一集束搜索算法的时间复杂度是O(k·d) , 其中d为搜索深度 。
二、MAP阶段:通过映射候选知识构建开放知识图谱
在获取原始的知识三元组后 , 需要进行适当的映射 , 与既有的知识图谱schema(如Wikidata)进行比对合并的同时 , 我们也对开放schema的结果进行保留整理 , 从而构建开放知识图谱 。
我们获取的第一类知识是可以完全映射到既有知识图谱schema的知识 。
利用专家构建的既有知识图谱 , 可以避免大量重复的实体与关系 , 也可以为进行自动结果评测打好基础 。 在这里 , 我们构建了简单的无监督的实体链接和关系映射方法 , 以最小的成本来实现这一目标:
实体链接方法:基于维基百科超链接和之前Crosswikis的结果 , 我们构造了大规模的mention-to-entity词典来进行实体链接 。 同时 , 语境信息也对实体链接具有重要的影响 , 因此我们简单地采用了的Glove词向量进行消歧 , 从而链接到含义相近的实体 。
关系映射方法:本文基本采用了Stanford OpenIE中提出的共现方法来构造关系映射 。 具体来说 , 如果一对头尾实体在抽取结果和既有知识图谱中共现 , 我们认为他们的关系短语很有可能是相同含义的 。 实际中 , 我们对关系短语进行词形还原并移除停用词来构建这样的映射 。 构建完初步的共现结果后 , 我们人工筛选了候选映射较多的关系短语的前15个结果 。 同时 , 我们也仿照Stanford OpenIE对部分关系的实体类型进行了简单的限制 。
第二类知识 , 属于开放schema的知识 。
具体来说有两种:
第一种属于半映射的知识 , 即(h, r, t)中有至少一个可以映射到既有知识图谱的schema中 , 而这一类也是开放schema知识的主要组成部分;
第二种属于完全开放的知识 , 即(h, r, t)都完全无法映射到既有的schema中 。
如此一来 , MAMA构建的知识图谱既包含了既有知识图谱schema范畴内的知识 , 也包含了更加灵活开放的开放型知识 , 为下一代知识图谱的构建提供了参考方向 。 例如图3 , 是MAMA在Wikipedia的Bob Dylan词条及其邻居词条中抽取出的部分知识图谱 。 蓝色的点边代表第一类包含于既有schema内的知识 , 而黄色的点边则代表了开放schema中的新知识 。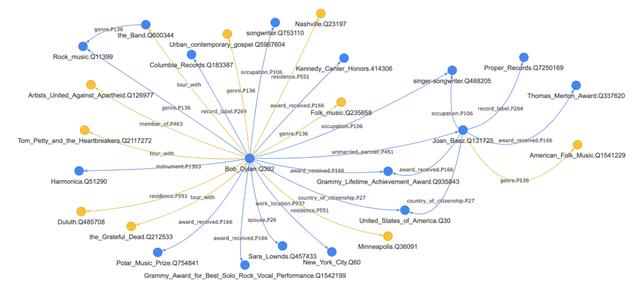 文章插图
文章插图
图3
3 结果
为了近一步验证MAMA构建的知识图谱的质量 , 本文分别对两类生成的知识进行了评估 。
对于能映射到当前知识图谱schema内的知识 , 本文定量地进行了自动化的评估;
对于开放schema的知识 , 本文通过采样进行了人工检查 。 文章插图
文章插图
表1
对于第一类可映射到既有schema内的知识 , 本文在两个大规模数据集上进行了评测 。 其一是经典的TAC Knowledge Base Population (KBP)的Slot Filling任务(本文选取2013年的数据) , 根据给定的实体和关系 , 在大规模文本中寻找填充答案 。
但是 , KBP标准答案的规模较小 , 无法很好地验证MAMA是否能在更大规模的数据上具有良好的扩展性 , 于是本文利用整个Wikidata和英文Wikipedia中的文本进行了评测 。 数据规模如表1所示 。
- 势不可挡|清华教授刘瑜:我的女儿正势不可挡地成为一个普通人
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 京东另类科学实验室之"5G来了"
- 清华大学刘知远:知识指导的自然语言处理
- ICPC--1200:数组的距离时间限制&1201:众数问题
- "财富梦"AI外贸配方?国货搭载AI"火箭营销"?
- ICPC--1206: 字符串的修改&1207:字符排列问题
- ICPC--1204: 剔除相关数&1205: 你爱我么?
- 音乐平台"改头换面",是新一轮社交平台,还是生活放松圈
- MITRE ATT&CK系列文章之Windows管理共享风险检测