渠道质量评估模型( 三 )
- 用来判断模型是否能对样本点的真实分布有个较好的拟合效果 , 而不是最终的拟合结果都趋近与腰部 , 头部和尾部没有拟合好 , 导致结果区分度不强(比如较差的渠道会拟合高 , 较好的渠道会拟合低) , 具体评估方法和实现代码详见:
- 材料:
- GitHub:
 文章插图
文章插图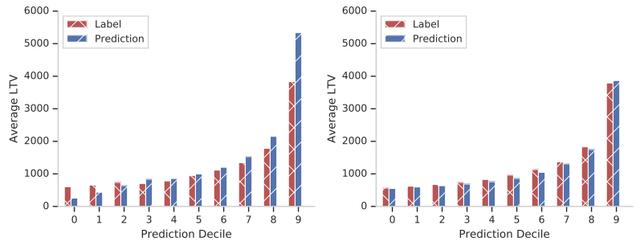 文章插图
文章插图04
反作弊及异常识别
作弊的识别除了要依赖反作弊团队专业的作弊识别技术外 , 分析师还需要做什么呢?分析师的优势在哪里呢?
分析师的优势在于:对渠道的结算逻辑 , 渠道归因逻辑 , 用户激活 , 用户站内承接 , 用户后续表现有一套完整清晰的认识 , 这些优势最终可以应用在以下几个地方:
- 明确哪些渠道 , 哪些结算方式是作弊的重灾区 , 以及究竟是媒体作弊还是代理商作弊?
- 撞库过程中 , 哪些指标异常可以反映付费渠道在抢占免费量 , 这时候即使付费渠道质量很好 , 结果也是不可信的 , 以及归因过程中 , 从ip , imei等更多维度上 , 也能看出一些问题 。
- 哪些行为指标之间是强相关的 , 如果在某些渠道上 , 这些指标并不相关 , 甚至负相关 , 说明该渠道可能存在问题
- 一个正常的留存曲线是什么样的?比如某些渠道前10天表现特别好 , 10天后突然变差 , 这种情况分析师可以识别 , 但是反作弊比较难识别 , 这种情况可能由于积分墙导致 , 需要引起注意 , 否则会对投放预算造成强误导 。
- 用户的正常行为是什么样的?用户的异常行为是什么样的?
05
渠道优化在对渠道质量进行准确评估并且识别出异常渠道后 , 我们来到了渠道优化环节 , 渠道优化一方面需要调整预算 , 另一方面涉及到具体渠道的优化细节 。 各个渠道由于结算方式的不同 , 而导致优化逻辑截然不同:
- 比如预装本质上属于一种合约广告 , 按照装机量进行收费 , 优化的逻辑就是给出准确的装机建议 , 并且做好预装的调起和承接工作
- 再比如几大主要的应用商店厂商比如华米OV应用商店是无法拆解付费免费量的 , 就会导致应用商店的用户质量看起来很高 , 但其实可能是虚假繁荣
- 还有很多时候SEM的目标在于找出大量的低成本长尾词来获客 , 而信息流专注于投放素材的优化和调整 , 并且具有较强的时效性
作者:姜博
- 区企联企协|谋求更高质量的转型发展!区企联企协与区科技局成功举办科技考察对接活动
- 广告点击|广告效果评估:30天的广告时间评估最全面
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收
- 新机|中兴公布全新渠道及市场策略,两款新机同步亮相
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 公司|走好科技成果转化“先手棋”——中煤集团石煤机公司依托技术创新推动高质量发展
- 团购|金龙鱼:目前公司的零售渠道已涉足社区团购业务
- 突破|Redmi红米手机:Note9系列新零售渠道销量突破30万台
- 新媒体工作室|勇当政法新媒体高质量发展排头兵,曲阜检察团队风采展
- 俄罗斯|华为,在俄罗斯智能手机线上渠道,销量排名第一