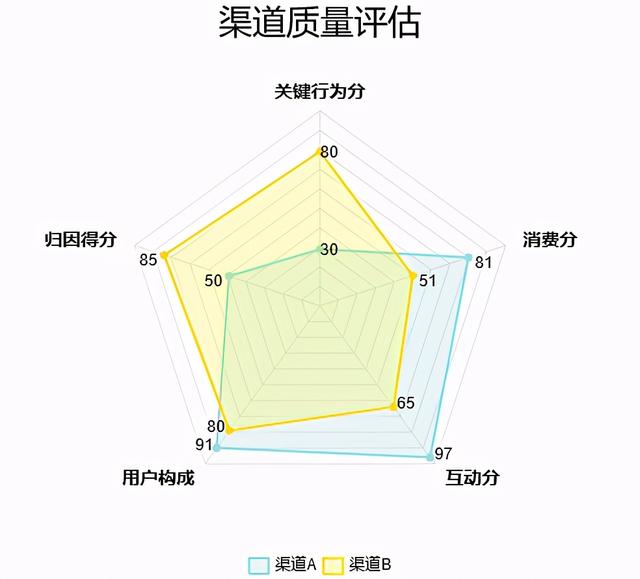
渠道质量评估模型( 二 )
在渠道质量评估初期 , 我们手上可能有一大堆的指标 , 最终究竟用哪些指标 , 需要进行指标筛选 , 通常 有以下几种方式:
- 相关性分析:绘制相关性矩阵 , 相关性特别强的指标保留更常用的那个指标就好
- 通过一些机器学习或者统计学的手段进行特征筛选
- 层次分析法(AHP)
- 专家打分法
- 基于线性回归输出的参数作为权重打分依据
 文章插图
文章插图长期渠道质量评估(LTV预测)
LTV可以通过各种各样的方式进行拟合 , 但是有三个点需要特别注意:
- LTV视具体的用途需要来评估是否要把渠道和用户终端机型等固有特征加到模型中 , 这些特征加入到模型中固然可以增加模型的准确性 , 如果以准确性作为唯一的评估指标 , 那么这样做没有问题 。 如果要根据得分对最终的渠道做评估优化 , 我们应当避免采用这些特征 , 而是仅根据用户的行为属性进行建模 , 虽然可能会损失部分的准确性 , 但更能有效反映渠道的好坏变化(也即是说 , 我们不对用户做先入为主的判断 , 不关心用户的来源渠道和机型 , 仅根据用户的表现来给分) 。
- 用短期的用户行为预估长期的LTV基本很难做到准确 , 而长期的用户行为周期太长 , 容易让渠道优化失去先机 , 一种比较好的办法是同时构建两个模型:1.短期模型 , 通过用户前3-10天的数据预测未来1个月的表现;2.长期模型:根据用户1个月的数据预测未来1年的行为表现;3.根据两个模型的结果可以校准模型 , 也可能能发现某些渠道的异常表现 。
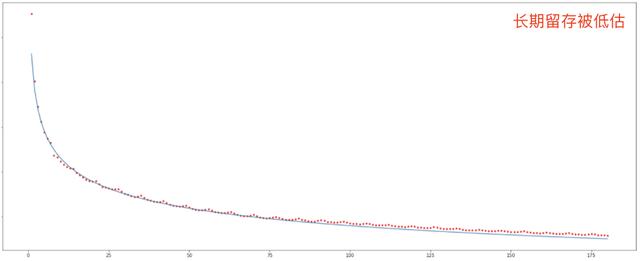
- 关注LTV的分布 , 常见的LTV分布是60%-70%的用户未来不会再产生LTV , 而剩余的少量用户的LTV分布近似正态分布 , 如下图所示 , 这种分布对建模是一种挑战 , 需要提前对LTV的分布有比较清晰的认知 。 对这种情况可以采用分段拟合 , 比如分类+回归模型进行建模 。
 文章插图
文章插图LTV拟合思路一:基于留存曲线进行拟合
以具体的渠道的留存曲线作为样本点来进行留存曲线的拟合 , 这样的好处是易于实现 , 坏处是没法对渠道进行进一步按照广告创意等的自由拆解 , 每一次维度发生变化 , 就要重新建模 , 每个渠道都是单独的模型 , 难以复用 。
基于留存曲线的拟合需要注意两个点:
- 函数形态的选择 , 比如究竟是用对数函数还是用指数函数等等 , 这里我们应该将留存曲线尽量拉长 , 来看看各类函数形态在长期留存上的表现 。
- 样本点的选择 , 1-3天的留存天属于强影响点 , 是否需要保留 , 我们经常遇到的问题是 , 曲线为了拟合这些点 , 而导致在长期留存上出现拟合不上的情况 , 这里建议在拟合的时候 , 对样本点做一个组合遍历 , 比如对1-10天的区间进行穷举 , 选出表现最好的样本点就行了 , 这个时候样本点并不是越多越好
 文章插图
文章插图 文章插图
文章插图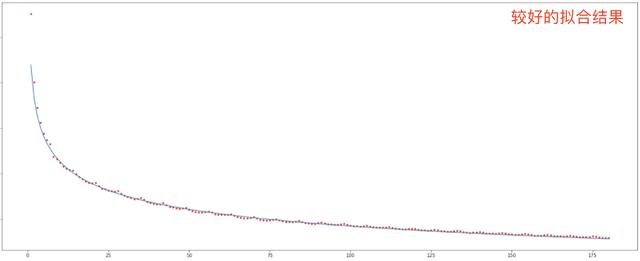 文章插图
文章插图LTV拟合思路二:基于用户明细进行拟合
单用户的长期LTV会受到随机性的影响 , 不过一旦将用户聚集到渠道等粒度上 , 结果还是相对准确的 , 并且这样的结果支持多个维度的组合分析 , 从头到尾只需要构建一套模型 。 模型的预测手段很多 , 这里不再赘述 , 仅对模型的评估进行一些说明 。 模型评估除了常用的MSE , 决定系数等之外 , 还需要关注的几个指标是:
【渠道质量评估模型】斯皮尔曼等级相关系数
- 在LTV的预测中 , 某些时候 , 相比于精度 , 我们更关注渠道的排序问题 , 也即是确实把末尾10%的渠道预测为了末尾的10% , 头部的10%的渠道预测为了头部的10% , 假设这样一个极端场景 , 每个渠道的LTV均预测低了5% , 这对整体渠道投放预算的优化调整几乎是没有影响的 。 所以在评估的时候 , 我们需要关注这样的指标 。
- 区企联企协|谋求更高质量的转型发展!区企联企协与区科技局成功举办科技考察对接活动
- 广告点击|广告效果评估:30天的广告时间评估最全面
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收
- 新机|中兴公布全新渠道及市场策略,两款新机同步亮相
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 公司|走好科技成果转化“先手棋”——中煤集团石煤机公司依托技术创新推动高质量发展
- 团购|金龙鱼:目前公司的零售渠道已涉足社区团购业务
- 突破|Redmi红米手机:Note9系列新零售渠道销量突破30万台
- 新媒体工作室|勇当政法新媒体高质量发展排头兵,曲阜检察团队风采展
- 俄罗斯|华为,在俄罗斯智能手机线上渠道,销量排名第一