如何对Pandas DataFrame进行自定义排序
 文章插图
文章插图
Pandas DataFrame有一个内置方法sort_values() , 可以根据给定的变量对值进行排序 。 该方法本身使用起来相当简单 , 但是它不适用于自定义排序 , 例如 ,
- t恤尺寸:XS、S、M、L和XL
- 月份:一月、二月、三月、四月等
- 星期几:周一、周二、周三、周四、周五、周六和周日 。
问题假设我们有一个关于服装店的数据集:
df = pd.DataFrame({'cloth_id': [1001, 1002, 1003, 1004, 1005, 1006],'size': ['S', 'XL', 'M', 'XS', 'L', 'S'],})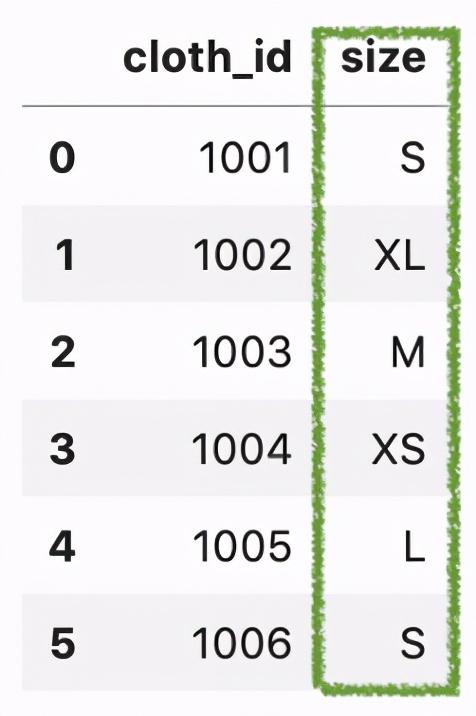 文章插图
文章插图我们可以看到 , 每一块布料都有一个尺寸值 , 数据应该按以下顺序排序:
- XS代表特大号
- S代表小号
- M代表中号
- L代表大号
- XL为特大号
 文章插图
文章插图输出不是我们想要的 , 但它在技术上是正确的 。 实际上 , sort_values()是按数字顺序对数值数据排序 , 对对象数据按字母顺序排序 。
以下是两种常见的解决方案:
- 为自定义排序创建新列
- 使用CategoricalDtype将数据强制转换为具有有序性的类别类型
首先 , 让我们创建一个映射数据帧来表示自定义排序 。
df_mapping = pd.DataFrame({'size': ['XS', 'S', 'M', 'L', 'XL'],})sort_mapping = df_mapping.reset_index().set_index('size') 文章插图
文章插图之后 , 使用sort_mapping中的映射值创建一个新的列 size_num 。
df['size_num'] = df['size'].map(sort_mapping['index'])最后 , 按新的列大小对值进行排序 。df.sort_values('size_num') 文章插图
文章插图这当然是我们的工作 。 但它创建了一个备用列 , 在处理大型数据集时效率可能会降低 。
我们可以使用CategoricalDtype更有效地解决这个问题 。
使用CategoricalDtype将数据强制转换为具有有序性的类别类型CategoricalDtype是具有类别和顺序的分类数据的类型[1] 。 它对于创建自定义排序非常有用[2] 。 让我们通过一个例子来看看这是如何工作的 。
首先 , 让我们导入CategoricalDtype 。
from pandas.api.types import CategoricalDtype然后 , 创建一个自定义类别类型cat_size_order- 第一个参数设置为['XS'、'S'、'M'、'L'、'XL']作为尺寸的唯一值 。
- 第二个参数ordered=True , 将此变量视为有序 。
cat_size_order = CategoricalDtype(['XS', 'S', 'M', 'L', 'XL'],ordered=True)然后 , 调用astype(cat_size_order)将大小数据强制转换为自定义类别类型 。 通过运行df['size'] , 我们可以看到size列已经被转换为一个类别类型 , 其顺序为[XS>>> df['size'] = df['size'].astype(cat_size_order)>>> df['size']0S1XL2M3XS4L5SName: size, dtype: categoryCategories (5, object): [XS < S < M < L < XL]最后 , 我们可以调用相同的方法对值进行排序 。df.sort_values('size') 文章插图
文章插图这样效果更好 。 让我们来看看原理是什么 。
使用cat的codes属性访问现在size列已经被转换为category类型 , 我们可以使用.cat访问器以查看分类属性 。 在幕后 , 它使用codes属性来表示有序变量的大小 。
让我们创建一个新的列代码 , 这样我们可以并排比较大小和代码值 。
df['codes'] = df['size'].cat.codesdf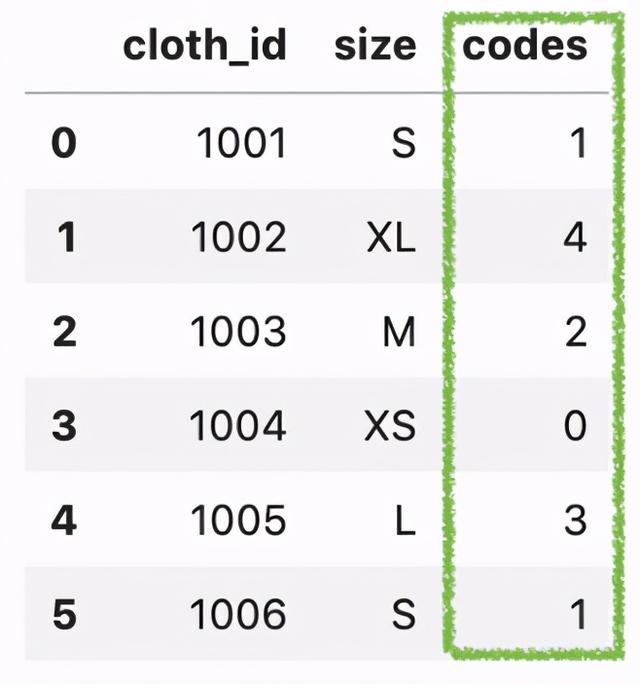 文章插图
文章插图我们可以看到XS、S、M、L和XL的代码分别为0、1、2、3、4和5 。 codes是类别实际值 。 通过运行df.info() , 我们可以看到实际上是int8 。
>>> df.info()RangeIndex: 6 entries, 0 to 5Data columns (total 3 columns): #ColumnNon-Null CountDtype----------------------------0cloth_id6 non-nullint641size6 non-nullcategory 2codes6 non-nullint8dtypes: category(1), int64(1), int8(1)memory usage: 388.0 bytes
- 纠结|硬杠红米Note9Pro?iQOO Z1跌至1575,对比之后纠结了!
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 时尚先生|小米雷军成2020年最出圈企业家:获时尚双刊年度人物
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 电信|巴西电信协会及运营商发文 反对限制华为5G