了解神经网络和模型泛化( 二 )
这是通过监视验证损失(或另一个验证指标)并在此特定指标停止改进时结束训练阶段来完成的 。通过这样做 , 我们给估算器足够的时间来学习有用的信息 , 但没有足够的时间来学习噪声 。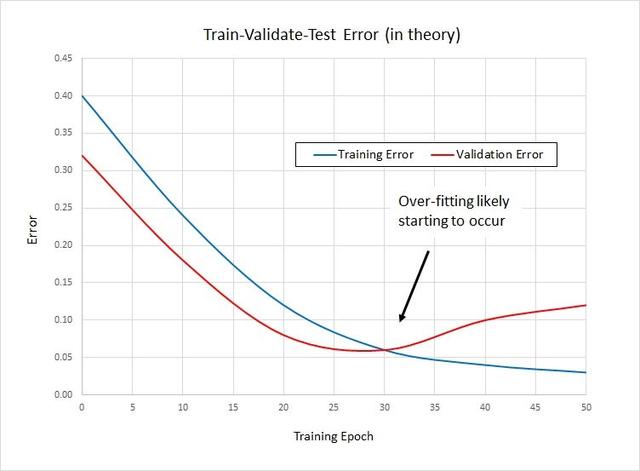 文章插图
文章插图
> Source
我使用这种方法的问题是 , 不能保证在任何给定的时间点 , 模型都不会再次开始改进 。一个比提早停止更实际的方法是存储在验证集上获得最佳性能的模型权重…
转移学习此方法是通过将网络的权重初始化为在大型通用数据集中预先训练的具有相同体系结构的另一个网络的权重来完成的 。我们经常将这种方法用于计算机视觉项目 。当我们的业务问题没有太多数据时 , 它对我们有很大帮助 , 但是我们可以找到另一个类似的问题 。在这种情况下 , 我们可以使用迁移学习来减少过度拟合 。
批处理规范化(BN)是一种规范深度神经网络中间层中的激活的技术 。
批处理标准化除了具有正则化效果外 , 还可以通过其他方式帮助您的模型(允许使用更高的学习率等) 。我建议您验证每层的权重和偏差分布看起来近似于标准正态 。
由于BN具有正则化效果 , 因此这也意味着您可以经常删除辍学(这很有帮助 , 因为辍学通常会减慢训练速度) 。
在训练过程中 , 我们会更新批次归一化参数以及神经网络的权重和偏差 。批处理归一化的另一个重要观察结果是 , 由于使用迷你批显示随机性 , 因此批处理归一化可作为正则化 。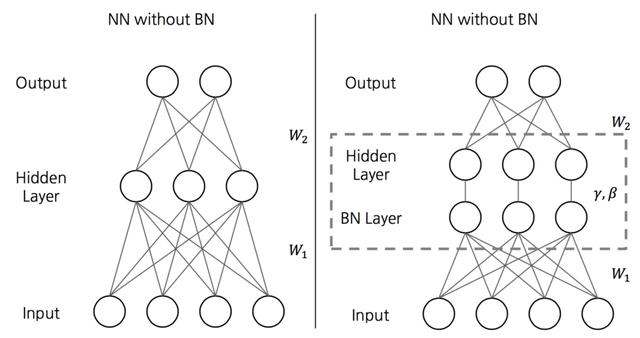 文章插图
文章插图
批处理大小=一次向前/向后传递中的训练示例数 。批次大小越大 , 您将需要更多的存储空间 。
数据扩充 。处理过度拟合的另一种方法是提高数据质量 。您可能会想到离群值/噪声消除 , 但是实际上它们的效率非常有限 。另一个有趣的方式(尤其是在与图像有关的任务中)是数据增强 。目的是随机转换训练样本 , 以使它们在模型中看起来不同时 , 它们传达相同的语义信息 。就个人而言 , 当我发现模型在训练集上的损失接近0时 , 我便开始考虑使用数据增强 。
意见建议我建议在考虑正则化方法之前先执行一些基本步骤 。确实 , 在大多数时候 , 我们无法确定对于每个学习问题 , 都存在一个可学习的神经网络模型 , 该模型可以产生所需的低泛化误差 。
正确的期望首先要找到一个很好的参考 , 它表示您在数据集或最相似的可找到参考的体系结构上 , 都可以达到所需的泛化错误 。在训练自己的数据集之前 , 尝试在这些参考数据集上重现这样的结果是很有趣的 , 以测试所有基础结构是否正确到位 。
训练程序验证这也是检查您的训练程序是否正确的关键 。这些检查包括: 文章插图
文章插图
超参数/架构搜索最后 , 关键是要了解 , 正则化本身并不一定意味着您的泛化误差会变小:模型必须具有足够大的容量才能实现良好的泛化属性 。这通常意味着您需要足够深的网络 , 然后才能看到正则化的好处 。
如果没有其他帮助 , 您将必须测试多个不同的超参数设置(贝叶斯优化可能会在此处提供帮助)或多个不同的体系结构更改 。
有关此主题的更多信息 , 我建议以下链接:
-normalization-in-neural-networks-1ac91516821c-volume15 / srivastava14a.old / srivastava14a.pdf-
【了解神经网络和模型泛化】(本文翻译自Alexandre Gonfalonieri的文章《Understand Neural Networks & Model Generalization》 , 参考:)
- 中国|浅谈5G移动通信技术的前世和今生
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 二维码|村网通?澳大利亚一州推出疫情追踪二维码 还考虑采用人脸识别和地理定位
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 花15.5亿元与中粮包装握手言和 加多宝离上市又进一步?|15楼财经 | 清远加多宝
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 内容|浅谈内容行业的一些规律和壁垒,聊聊电商平台孵化小红书难点(外部原因)