了解神经网络和模型泛化
深层神经网络的模型概括 , 过度拟合和正则化方法的挑战 文章插图
文章插图
> Source
在完成了与神经网络有关的多个AI项目之后 , 我意识到模型的概括能力对于AI项目的成功至关重要 。我想写这篇文章来帮助读者了解如何使用正则化方法来优化模型的性能 , 并更好地理解基于神经网络提供可靠且可扩展的AI解决方案的复杂性 。
泛化是用于描述模型对新数据做出反应的能力的术语 。
泛化是模型经过训练后可以消化新数据并做出准确预测的能力 。这可能是您的AI项目中最重要的元素 。模型的概括能力对于AI项目的成功至关重要 。确实 , 我们担心模型在训练数据上训练得太好 , 但是无法推广 。
因此 , 我们常常没有达到生产阶段……在提供新数据时 , 它会做出不准确的预测 , 即使模型能够对训练数据做出准确的预测 , 也会使模型无用 。这称为过拟合 。
相反的情况也可能发生 。欠拟合是指未对数据进行足够的模型训练 。在欠拟合的情况下 , 即使使用训练数据 , 模型也一样无用 , 也无法做出准确的预测 。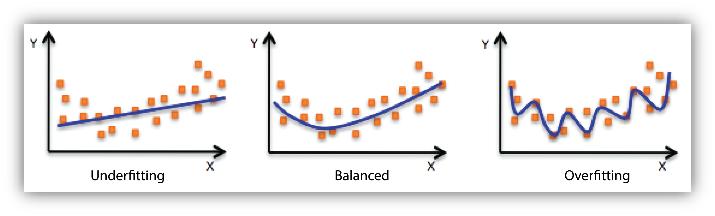 文章插图
文章插图
在所有AI项目中 , 我们都基于现有数据构建模型 , 并希望它们能完美地适应(概括)新数据 。在监督学习中 , 我们拥有过去的数据以及所有我们希望预测的预测值和真实值 。尽管定义了业务问题 , 但是收集相关数据 , 清理和准备数据以及建立模型都具有挑战性 , 并且非常耗时……另一个挑战仍然存在–如何知道模型能否很好地预测未来?
训练可以很好地泛化到新数据的深度神经网络是一个具有挑战性的问题 。
当涉及到神经网络时 , 正则化是一种对学习算法稍加修改的技术 , 以使模型具有更好的泛化能力 。反过来 , 这也改善了模型在看不见的数据上的性能 。
模型复杂度从业务角度来看 , 深度神经网络的主要优势在于 , 随着向越来越大的数据集馈入数据 , 神经网络的性能不断提高 。当公司尝试创建数据网络效果时 , 这非常有趣 。
但是 , 具有几乎无限数量的示例的模型最终将在网络能够学习的容量方面达到某些限制 。正确的正则化是获得更好的泛化性能的关键原因 , 因为深度神经网络经常被过度参数化并可能遭受过度拟合的问题 。
我们可以通过以下方法降低神经网络的复杂度 , 以减少过度拟合: 文章插图
文章插图
减少模型的容量可将模型过度拟合训练数据集的可能性降低到不再适合的程度 。
通过保持较小的网络权重来减少过度拟合的技术称为正则化方法 。
正则化:添加额外信息以将不适的问题转化为更稳定的良好问题的一类方法 。
下面 , 我列出了我们经常使用的几种正则化方法(确实存在其他方法 , 例如权重约束或活动正则化) 。但是 , 减少过度拟合的最简单方法是从本质上限制模型的容量 。
全连接(FC)层最容易过拟合 , 因为它们包含最多的参数 。辍学应该应用于这些层(影响它们与下一层的连接) 。除标准形式的辍学外 , 还存在几种辍学的变体 , 旨在进一步提高泛化性能 。例如 , 自适应辍学 , 其中辍学率由另一个神经网络动态确定…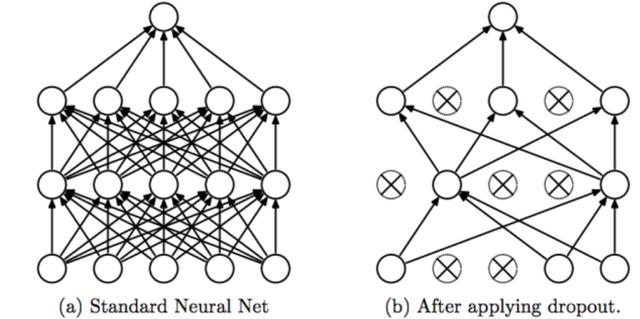 文章插图
文章插图
但是 , 我注意到 , 如果您使用CNN , 则现在不经常使用辍学 。相反 , 我看到越来越多的数据科学家使用批处理规范化 。当您拥有大量数据集时 , 批处理规范化比辍学更为有效 。
噪声正规化的一种常见类型是在训练过程中注入噪声:将噪声添加或乘以神经网络的隐藏单元 。通过在训练深度神经网络时允许一些误差 , 不仅可以提高训练性能 , 而且可以提高模型的准确性 。
根据Jason Brownlee的说法 , 训练期间使用的最常见的噪声类型是在输入变量中添加高斯噪声 。添加的噪声量(例如 , 扩展或标准偏差)是可配置的超参数 。噪声太小没有作用 , 而噪声太大使映射功能难以学习 。确保在评估模型或使用模型对新数据进行预测时 , 不添加任何噪声源 。
早期停止早期停止是一种交叉验证策略 , 在该策略中 , 我们将一部分训练集保留为验证集 。实际上 , 当我们看到验证集的性能越来越差时 , 我们就停止了对模型的训练 。
换句话说 , 这种方法尝试在估计噪声的模型之前 , 尽早停止估计器的训练阶段 , 即该阶段已学会从数据中提取所有有意义的关系 。
- 中国|浅谈5G移动通信技术的前世和今生
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 二维码|村网通?澳大利亚一州推出疫情追踪二维码 还考虑采用人脸识别和地理定位
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 花15.5亿元与中粮包装握手言和 加多宝离上市又进一步?|15楼财经 | 清远加多宝
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 内容|浅谈内容行业的一些规律和壁垒,聊聊电商平台孵化小红书难点(外部原因)