腾讯出品:自循环半监督算法性能逼近监督学习
 文章插图
文章插图
本期分享MICCAI2020的一篇关于医学图像分割的半监督学习文章
《Self-Loop Uncertainty: A Novel Pseudo-Label for Semi-supervised Medical Image Segmentation 》 。
为解决医学数据标注费时费力等问题 , 腾讯Jarvis实验室提出了一种自循环不确定性半监督医学图像分割方法 。 通过利用大量的无标签数据进行半监督学习提升分割的准确率 , 其性能逼近监督学习!”
该方法通过设计一种循环优化半监督学习任务网络生成伪标签(pseudo-label) , 在训练的过程中不断提升伪标签的可信度以提升医学图像分割的准确率 。
实验在两个开源的数据集上表现出较好的性能 。 文章插图
文章插图
论文地址:
1 问题的挖掘
老生常谈的问题:深度学习需要大量的带标注的数据 , 但在医学领域 , 标注数据成本太高且不易于获取 。 半监督 , 弱监督或者无监督方法应运而生 。
本文作者重点研究半监督方法 , 罗列了主流的通过无标注数据进行医学图像分割的方法 。 第一种是基于sofxmax 概率图(softmax probability map)法;第二种是基于蒙特卡洛(MC)dropout法;第三种是通过网络集成的不确定性估计方法 。
本文提出了一种自循环不确定性半监督方法 , 从文章的题目以及后续内容分析 , 其属于第三种 。 该方法构造了一个拼图游戏子任务 , 通过优化一个全卷积网络(FCN)编码器(Encoder)将无标注数据的假标签的真实性逐步提升来达到提升模型性能的目的 。
此方法对于网络的益处主要有以下两点:1、自监督学习子任务使得神经网络模型对原始输入数据进行了深度的信息挖掘 , 这对于后续的分割任务是有利的;2、同一个网络在不同阶段进行训练和优化 , 可以看做集成学习 , 但本文提出的方法耗费的计算资源更少 。
作者在两个开源的医学数据集上进行了验证 , 实验结果显示比当前主流的如上文所述的第一二种方法性能提升更好 。
2 方法
本文提出的半监督分割方法框架如下图所示 。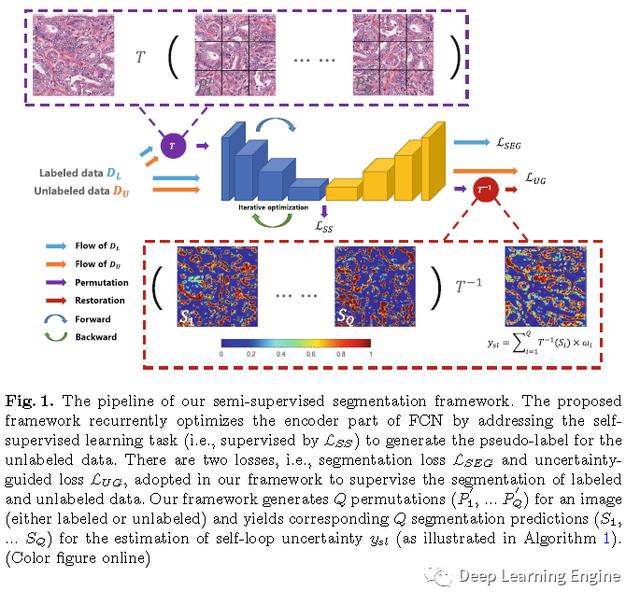 文章插图
文章插图
其中 , 训练集和分别表示标注和无标注数据 。 本文作者提出的半监督学习框架包含3个损失 。 图中彩色的箭头代表着信息的流动 , 和分别是橙色和蓝绿色 。 每一个批次的数据包含和 , 训练计算监督分割损失m(本文采用的二分类交叉熵损失函数 , 优化模型的分割性能) , 自监督损失(利用标注和无标注数据 , 提升模型挖掘数据信息的能力 , 指导模型生成伪标签)以及损失 。
2.1 自监督子任务
如前文所述 , 自监督损失是用来丰富模型对原始输入数据信息的挖掘以及生成自循环不确定标签(伪标签) 。 这种生成伪标签的子任务方法有多种 , 如预测旋转 , 图像作色等 。 本文作者采用的半监督学习方法用到的子任务是图像拼图游戏 , 包括图像的平移和选择变换 。 通过该方法对FCN编码器部分进行训练和优化以及生成伪标签 。
在这里我们不展开详细介绍拼图游戏作为代理任务的具体实现方法 , 大家可以自行百度参考《Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles》这篇文章的博客 。
与标准的拼图游戏方法类似(本质上还是把拼图问题转化为分类问题) , 作者将图像分成3×3合计9个图像块 。 9个图像块采用随机排列的方式有9!种(9的阶乘362880种组合方式) , 使用所有的类别进行训练是不现实的 。 即使可以产生这么多种类别 , 但是大多数的类别之间是很相似的 , 有可能只有两个位置的差别 , 而预测拼图问题很可能面对的一个问题就是 , 网络没有学习到图像的语义特征 , 而是只学到了每个patches的相对位置 。 基于以上的原因 , 作者在确定排列的时候 , 会计算不同排列之间的汉明距离 , 选择有足够大汉明距离的排列 , 这样就可以保证不同排列有较大的差异 , 确保网络不会只是记住了它们的相对位置 。 本文中作者选取的排列组合的子集大小为 , 循环次 。 即每次从排列组合(K=100)中随机选取一个作为本次随机组合的方式进行训练 。 FCN的编码器在此基础上就循环进行更新 , 因为这个训练方法是从K=100个随机组合中选取一个进行训练 , 相当于是K分类任务 , 故loss函数用的就是交叉熵损失函数 。
本文用到的拼图方法和原始的方法有两点差异 。 第一 , 增加了排列组合的多样性 , 除了平移变换外 , 每个图像块都随机旋转一个角度
- 商品|问道自有品牌,山姆多方博弈
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 自动|碳博士控股子公司推出最新款自动驾驶清扫车
- 世代|Z星球——腾讯布局Z世代教育社交的新尝试
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- 自动驾驶汽车|海外|自动驾驶无法可依?美国多个团体联合发布自动驾驶立法大纲
- 车辆|魔道之争,自主驾驶汽车会不会变成犯罪分子的工具?
- 品牌|为求差异化 山姆升级自有品牌Member’s Mark
- 旗舰|手机带“Pro”就一定专业?这两款自拍旗舰来了一场对比