python爬虫高级教程:多线程队列,生产消费模式爬虫( 二 )
队列中共有31388条链接
创建线程任务方法:
def working():while True: #需要使用while 否则线程执行完一次操作就关闭了url = q.get() #默认队列为空时 , 线程暂停doing(url)q.task_done()#告诉队列本次取操作已经完毕def doing(url):#线程在获取到链接后的行为rsp=requests.get(url=url[0],headers=headers)html_4=bs4.BeautifulSoup(rsp.text,'html.parser')ul=html_4.find('ul',class_='thrui')f=open('./Thread_Test/{}/{}/{}/{}.csv'.format(url[1][0],url[1][1],url[1][2],url[1][3]),'w',encoding='utf-8',newline='')csv_writer=csv.writer(f)csv_writer.writerow(title)for i in ul.find_all('li'):lis=[]a=i.find_all('div')for j in a:if len(j.text.split())==0:passelse:lis.append(j.text.split()[0])print(url[1][0],url[1][1],url[1][2],url[1][3],'剩余',q.qsize())csv_writer.writerow(lis)f.close()创建子线程
threads = []for i in range(10): #开启十个子线程t = threading.Thread(target=working) #线程的目标任务为working方法threads.append(t)开启子线程
for item in threads:item.setDaemon(True)item.start()q.join()#在队列为空时才进行后面的语句 , 需要配合task_done()使用基本的多线程爬虫就完成了 。
还有一个更优的方法生成一个新的队列来储存主线程创建的十个子线程获取到网页数据 , 子线程并不直接写入 , 而是交给主线程 , 主线程再生成新的子线程来写入队列里的数据 , 这样就减少了十个子线程等待写入文件的时间 , 专注于爬取数据 。
由于数据量太大 , 测试仅选择了一个省的数据进行爬取 。 约1300条数据 文章插图
文章插图
此图为线程直接写入所需时间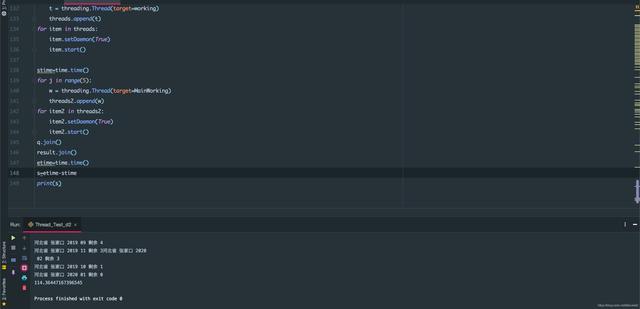 文章插图
文章插图
此图为使用新线程专门处理写入数据所需时间 文章插图
文章插图
次图为单线程爬虫所需时间
可以看到使用新线程专门处理写入数据时 , 速度比边爬边写快了30秒=百分之二十 , 而单线程花费了恐怖的1405秒 , 为多线程的十倍之多 , 可见多线程在爬取大量数据时是非常有用的 。 当然 , 这么快的速度肯定会遭到反扒处理 , 封ip之类的 , 所以要事先准备一个ip池 , 每个线程在爬取一段时间后就更换一个ip , 线程不建议开太多 , 避免给目标网站服务器造成太大压力 , 做一个绅士爬虫!
这段代码还可以再继续优化:1.爬虫的类库提取2.线程的类库提取3.存数据库的类库提取4.main()函数优化
【python爬虫高级教程:多线程队列,生产消费模式爬虫】初上手多线程 , 对于锁什么的还不是很懂 , 若有错误的地方欢迎指明 。
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- 十分钟教会你使用Python操作excel,内附步骤和代码