python爬虫教程,采集美团网酒店信息
文章目录
- 一、分析网页二、爬取酒店信息
私信小编01即可获取大量Python学习资料
网站的页面是 JavaScript 渲染而成的 , 我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的 , 因此这些数据并不存在于原始 HTML 代码中 , 而 requests 仅仅抓取的是原始 HTML 代码 。 抓取这种类型网站的页面数据 , 解决方案如下:
分析 Ajax , 很多数据可能是经过 Ajax 请求时候获取的 , 所以可以分析其接口 。
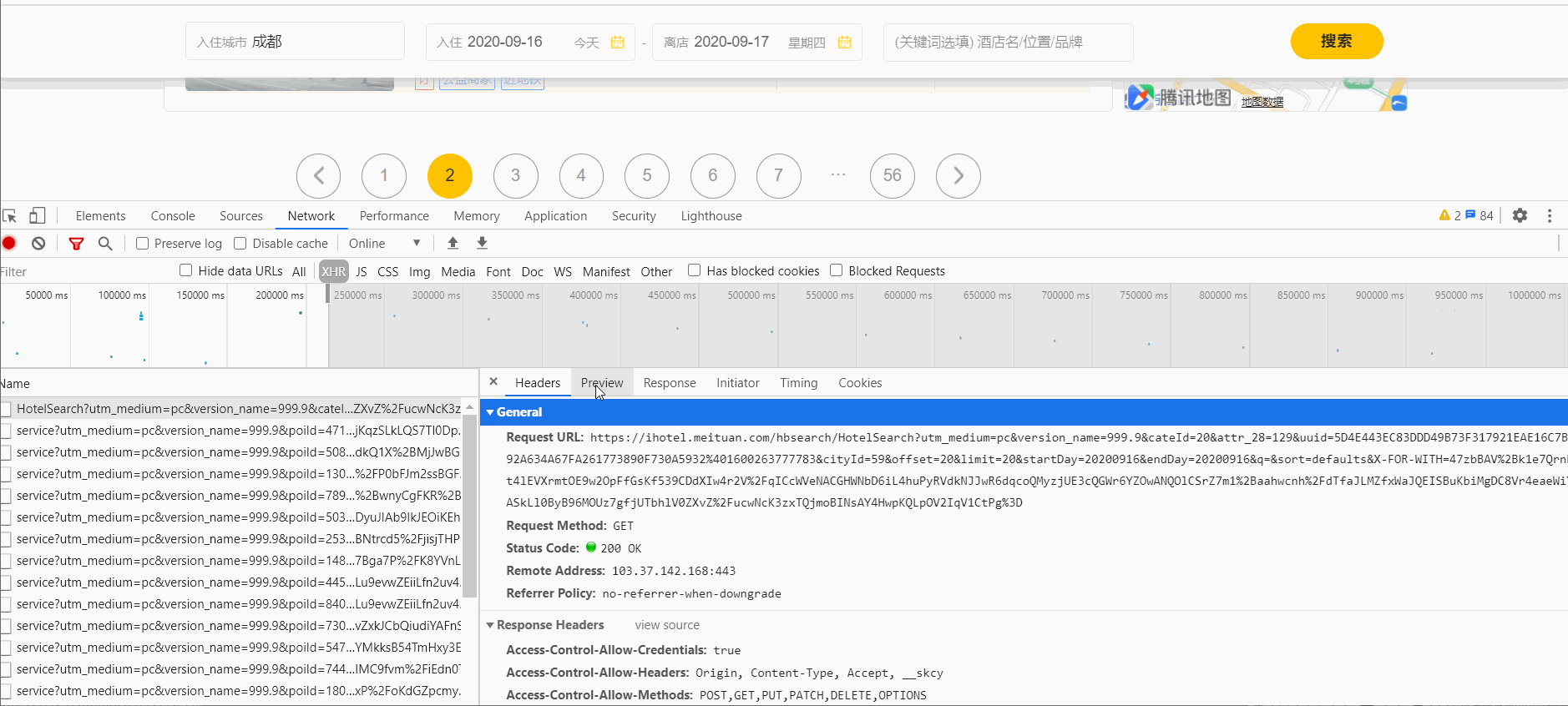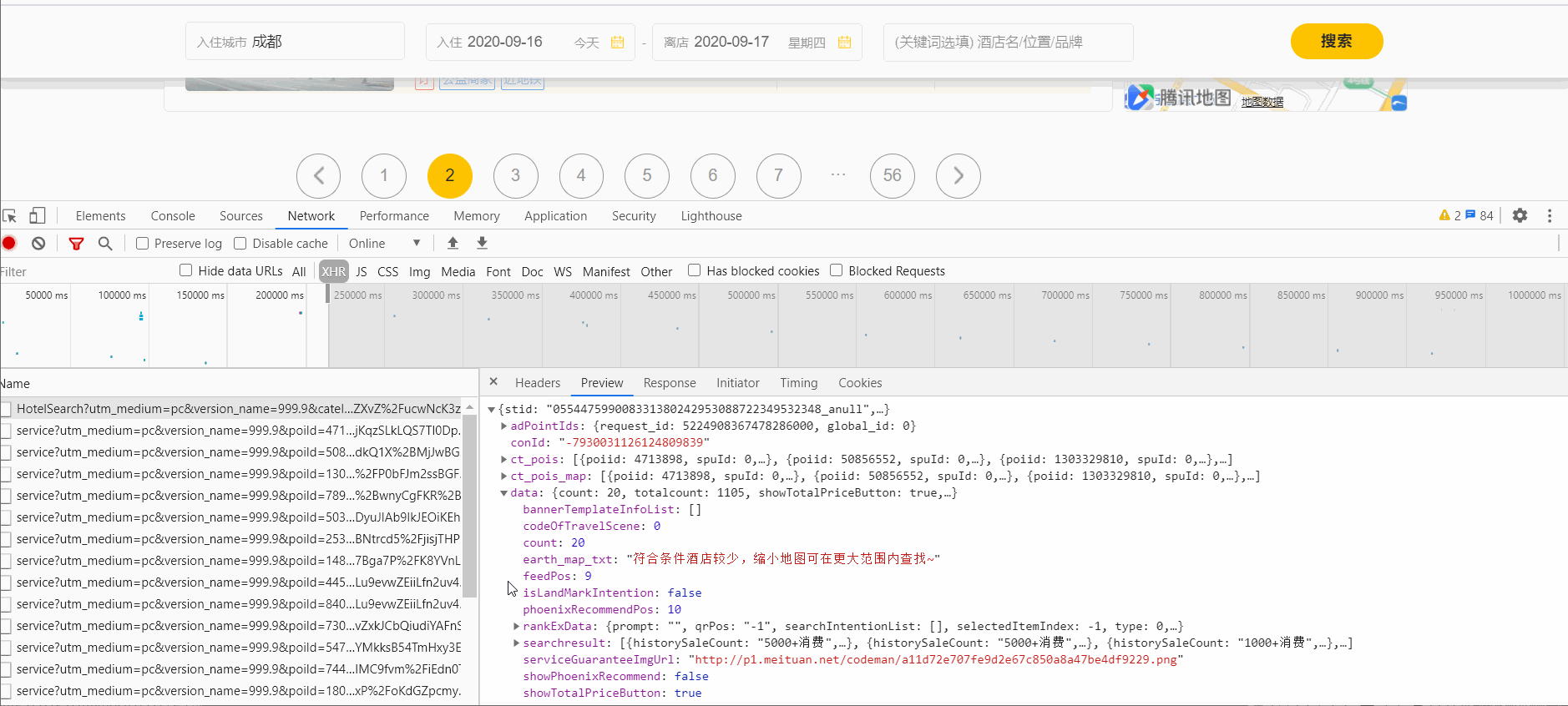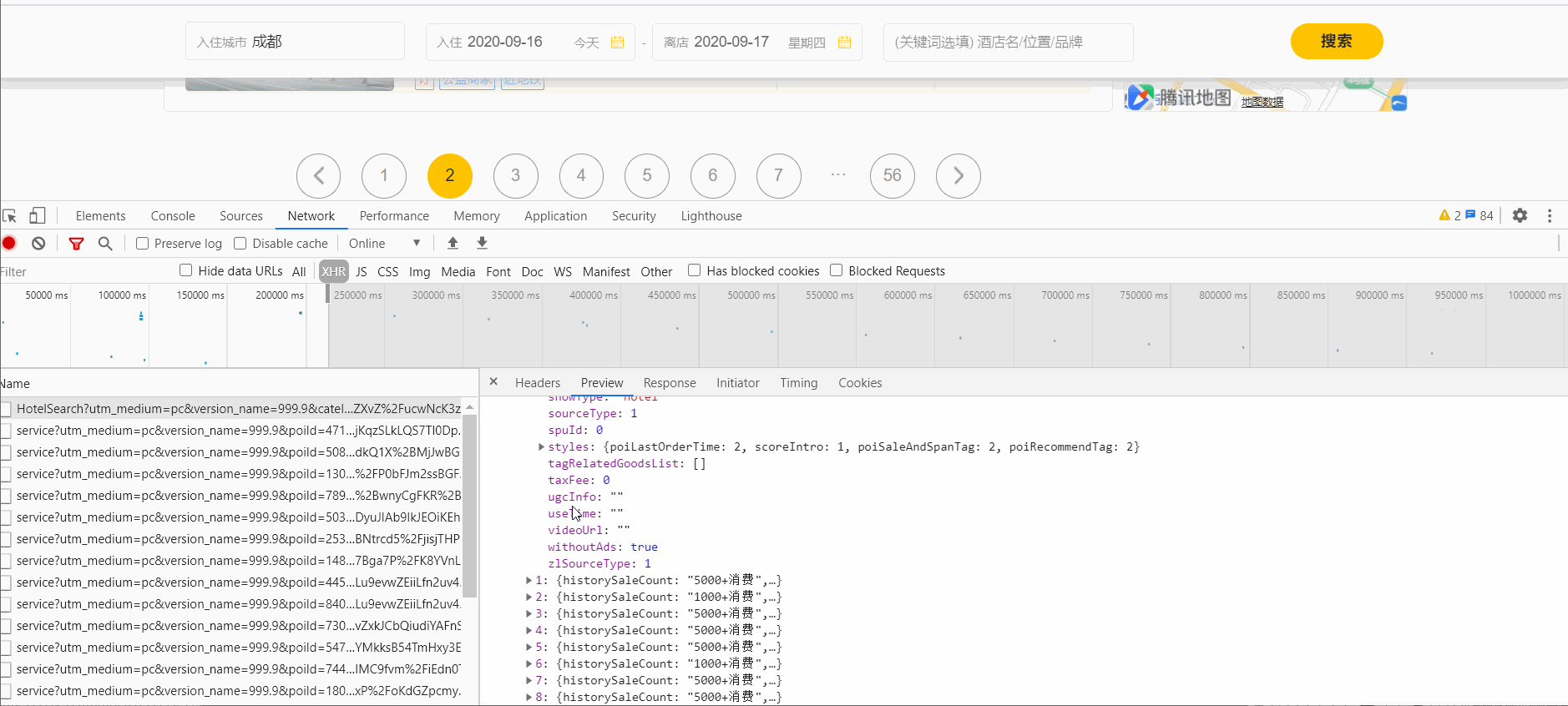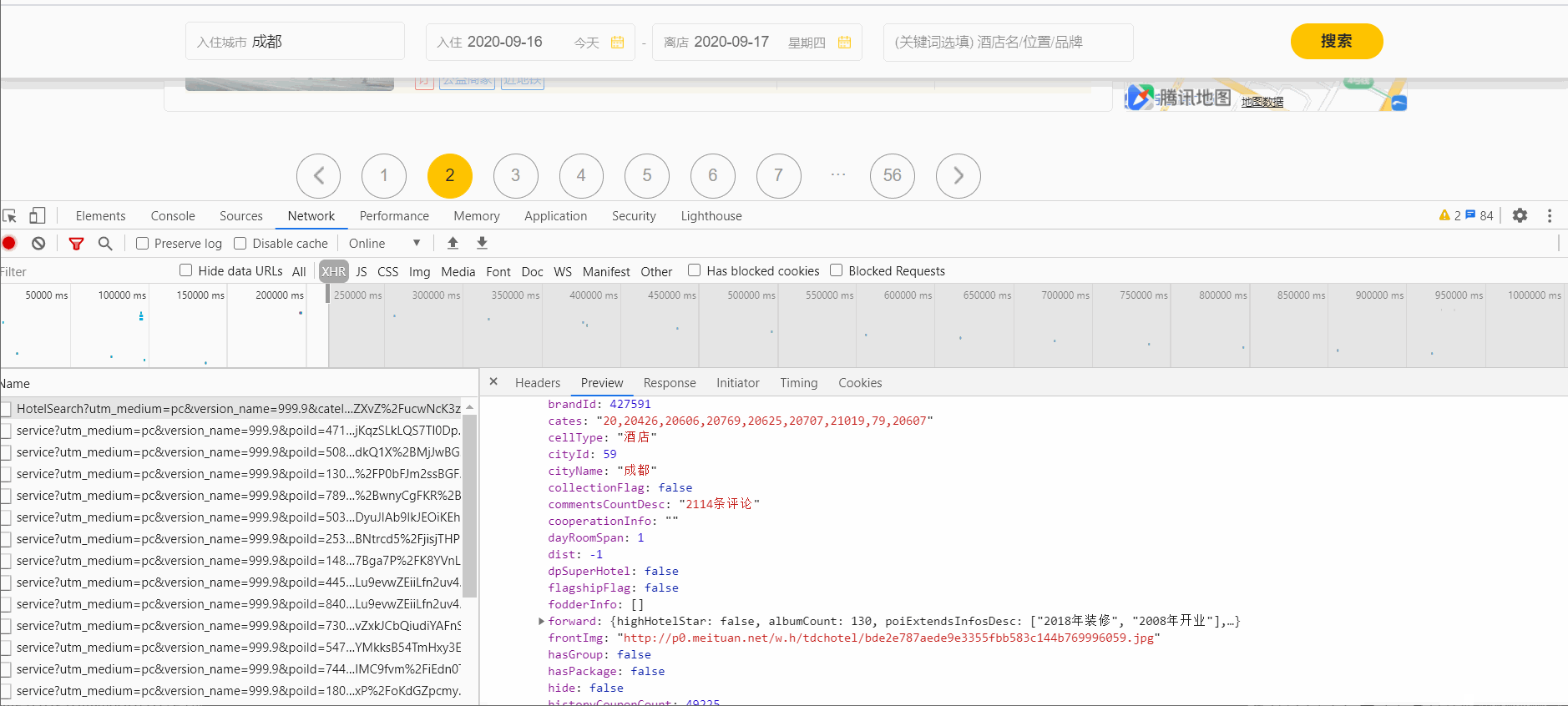
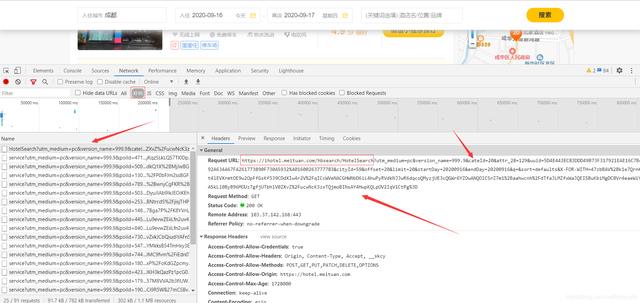 文章插图
文章插图在XHR里可以找到 , Request URL有几个关键参数 , uuid和cityId是城市标识 , offset偏移量可以控制翻页 , 分析网页发现 , 第x页的offset为:(x-1)*20 , limit表示每页有20条信息 , startDay和endDay为当前的日期 。
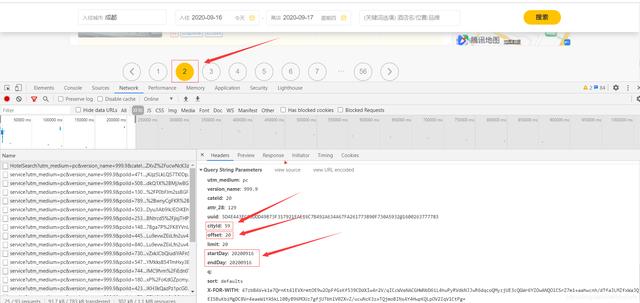 文章插图
文章插图在Preview里可以找到每页的20条信息
 文章插图
文章插图模拟JavaScript渲染过程 , 直接抓取渲染后的结果 。
selenium和pyppeteer爬虫就是用的这种方法
二、爬取酒店信息
"""@Author:叶庭云@Date:2020/9/16 15:01@CSDN:"""import requestsimport jsonimport openpyxlimport loggingfrom concurrent.futures import ThreadPoolExecutorimport randomimport timelogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')url = ""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36","Referer": ""}wb = openpyxl.Workbook()sheet = wb.activesheet.append(['酒店名称', '酒店地址', '酒店类型', '最低价', '评价', '评论数', '经度', '纬度'])def hotel_data(x):data = http://kandian.youth.cn/index/{'utm_medium': 'pc','version_name': 999.9,'cateId': 20,'attr_28': 129,'uuid': '5D4E443EC83DDD49B73F317921EAE16C7B492A634A67FA261773890F730A5932@1600263777783','cityId': 59,'offset': x * 20,'limit': 20,'startDay': 20200916,'endDay': 20200916,'q': '', 'sort': 'defaults','X-FOR-WITH': '47zbBAV+k1e7QrnKt4lEVXrmtOE9w2OpFfGsKf539CDdXIw4r2V/qICcWVeNACGHWNbD6iL4huPyRVdkNJJwR6dqcoQMyzjUE3cQGWr6YZOwANQOlCSrZ7m1+aahwcnh/dTfaJLMZfxWaJQEISBuKbiMgDC8Vr4eaeWiYASkLl0ByB96MOUz7gfjUTbhlV0ZXvZ/ucwNcK3zxTQjmoBINsAY4HwpKQLpOV2IqV1CtPg=',}res = requests.get(url, headers=headers, params=data)time.sleep(random.randint(1, 3))results = json.loads(res.text)['data']['searchresult']for con in results:name = con['name']# 酒店名称addr = con['addr']# 酒店地址star = con['hotelStar']# 酒店类型price = con['lowestPrice']# 最低价scoreIntro = con['scoreIntro']# 评价comments = con['commentsCountDesc']# 评论数lng, lat = con['lng'], con['lat']# 经纬度data = http://kandian.youth.cn/index/[name, addr, star, price, scoreIntro, comments, lng, lat]sheet.append(data)logging.info(data)if __name__ =='__main__':page = [i for i in range(56)]with ThreadPoolExecutor(max_workers=4) as executor:executor.map(hotel_data, page)wb.save("hotel.xlsx")【python爬虫教程,采集美团网酒店信息】程序运行成功 , 酒店信息保存到了Excel 。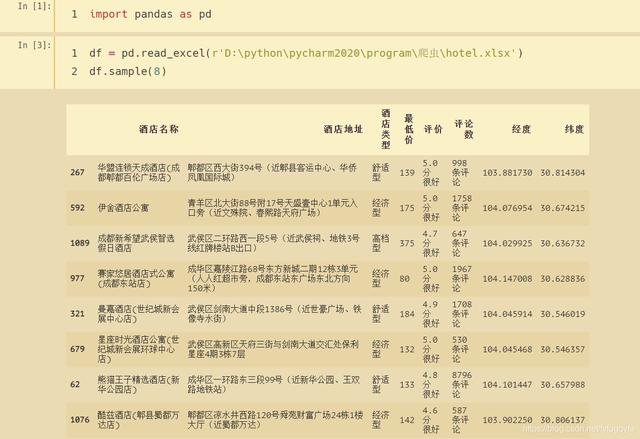 文章插图
文章插图- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 随身携带「Windows」Windows To Go制作教程
- Python中文速查表-Pandas 基础